Одной из самых игнорируемых новых функций HTML5 является Microdata. Микроданные позволяют нам более конкретно классифицировать и маркировать наш веб-контент машиночитаемым способом. Почему это важно, потому что это может положительно повлиять на ваши результаты поиска.
Когда вы ищете что-то в Google или где-то еще, вы получаете список ссылок с несколькими предложениями описания под ними. Мы все используем эти описания, которые Google называет « Rich Snippets », чтобы определить, по какой ссылке нажать.
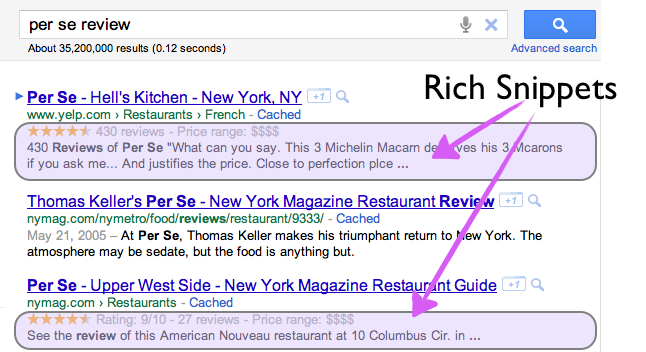
Не хотели бы вы иметь возможность влиять на то, что отображается во фрагментах результатов поиска для вашего сайта? Разве не было бы неплохо уточнить для поисковой системы и ее ботов, которые просматривают вашу страницу: «Эй, Google, я знаю, у меня есть двадцать изображений на моей странице, но это изображение, это мое биографическое изображение». Или возможно, «Привет, Бинг, я знаю, что на моей странице есть тонны ссылок, но эта ссылка относится к моему событию».
С помощью микроданных мы можем пометить наш существующий HTML несколькими новыми атрибутами, чтобы маркировать и классифицировать наш контент так, чтобы поисковые системы могли как понимать, так и использовать в своих богатых фрагментах.
Прежде чем мы добавим эти новые атрибуты, нам нужно выбрать словарь того, что мы пытаемся описать. Мы могли бы написать свои собственные словари или использовать чужие. У нас был сайт http://data-vocabulary.org , поддерживаемый Google с несколькими словарями. Но было неясно, поддерживали ли другие поисковые системы. К счастью для нас, в июне 2011 года Google, Microsoft и Yahoo! объединились, чтобы договориться об очень большом наборе словарей, которые мы можем использовать на наших сайтах.
Троица поиска вместе
Трудно представить Google, Microsoft и Yahoo! сотрудничать в чем-либо, не говоря уже о поиске, но это именно то, что они делают на сайте schema.org . Schema.org предоставляет набор словарей, которые мы можем использовать с микроданными. Используя словари для таких вещей, как Персона, Книга и Организация, которые находятся на определенном schema.org, мы можем быть уверены, что наши Микроданные будут понятны Google, Bing и Yahoo! поиск
Как это устроено
Чтобы использовать микроданные, мы должны добавить как минимум три новых атрибута в существующий HTML:
Itemscope-
Itemtype -
Itemprop
Чтобы следовать этому примеру, перейдите на страницу демонстрации . Посмотреть исходный код для полного кода.
Itemscope
Itemscope устанавливает объем того, что мы описываем с помощью микроданных. Вы можете думать об этом как об определении родительского элемента, внутри которого будут содержаться другие элементы с информацией, которую мы пытаемся предоставить поисковым системам. Все элементы, вложенные в элемент с itemscope будут придерживаться словаря, указанного вами в # 2, itemtype .
Если мы хотим описать человека в его онлайн-резюме, мы могли бы обернуть вокруг него элемент section и дать ему атрибут itemscope для начала:
<section itemscope> Audre Lorde was an author, academic, activist and poet, known for her many contributions to feminist literature and thought. Perhaps her most celebrated work is " <a href="http://t.co/8wbANUC"> Sister Outsider </a>," a collection of essays and speeches. She passed away on November 17th, 1992. </section>
Itemtype
Атрибут itemtype — это то, где мы объявляем, какой словарь мы используем, и что мы пытаемся описать. Самая основная лексика на schema.org предназначена для Thing . Словарь Thing включает в себя четыре свойства, которые мы можем установить: описание, изображение, имя и URL. Все остальные вещи (Книги, Рестораны, Места) происходят от словаря Вещей.
Чтобы продолжить добавление микроданных в наше онлайн-резюме, мы добавляем тип элемента в наше лицо:
<section itemscope itemtype=”http://schema.org/Person”> Audre Lorde was an author, academic, activist and poet, known for her many contributions to feminist literature and thought. Perhaps her most celebrated work is " <a href="http://t.co/8wbANUC"> Sister Outsider </a>," a collection of essays and speeches. She passed away on November 17th, 1992. </section>
Itemprop
itemprop — это способ добавления метки к большинству нашего контента. Мы просто добавляем атрибут itemprop к существующим элементам с содержимым, которое мы хотим пометить. Как мы маркируем контент? Это зависит от того, какое значение мы присваиваем itemprop . Значение должно быть одним из свойств нашего словаря.
В некоторых случаях вы можете пометить чистый текстовый контент с помощью itemprops . В этих случаях нет никаких HTML-элементов для добавления атрибутов, поэтому часто добавляются divs или divs .
Чтобы продолжить с нашим примером:
<section itemscope itemtype=”http://schema.org/Person”> <span itemprop=”name”>Audre Lorde</span> was an <span itemprop=”jobTitle”>author,</span> <span itemprop=”jobTitle”>academic,</span> <span itemprop=”jobTitle”>activist</span> and <span itemprop=”jobTitle”>poet</span>, known for her many contributions to feminist literature and thought. Perhaps her most celebrated work is " <a href="http://t.co/8wbANUC"> Sister Outsider </a>," a collection of essays and speeches. She passed away on November 17th, 1992. </section>
Теперь мы указали, какое свойство элемента нас интересует, но как поисковая система узнает, какой контент я имею в виду? Использует ли он только текстовое содержимое внутри элементов span («Audre Lorde», «author» и т. Д.). Как узнать, откуда взять URL для itemprop=”url” в элементе a ?
Хорошая новость заключается в том, что он по сути всегда захватывает ценность, которую вы надеетесь получить. Полный список находится в спецификации Microdata :
-
A,areaилиlinkэлементы принимают значение в атрибутеhref - Элемент
metaпринимает значение в атрибутеcontent - Элементы
Audio,embed,iframe,img,source,trackилиvideoберут абсолютный URL из атрибутаsrc - Элемент
timeполучает значение из атрибутаdatetime - Элемент
objectберет абсолютный URL из атрибутаdata - Все остальные элементы принимают текстовое содержимое внутри элемента. (пример:
span,p,div)
Говоря о Datetime
У нас есть дата смерти на нашей маленькой биографической странице. Можем ли мы просто добавить itemprop=”deathDate” , которое является свойством, определенным в словаре Person ? К сожалению, мы не можем. Нам нужно сначала обернуть его в новый элемент time HTML5, чтобы у нас была машиночитаемая дата.
She passed away on <time itemprop="deathDate" datetime="1992-11-17">November 17th, 1992</time>.
Все это звучит знакомо …
Вы можете найти эти понятия знакомыми, так как они были вокруг в течение некоторого времени. Микроформаты — это один из способов, который использовался в прошлом, чтобы сделать контент HTML машиночитаемым. Если вы посмотрите на HTML в профиле LinkedIn, вы обнаружите, что он размечен микроформатом hCard. То же самое относится и к событиям Facebook.
Одна проблема с микроформатами заключается в том, что мы перегружаем атрибут class нестандартным способом. Становится трудно itemscope , «используется ли этот класс в моем CSS или для микроформатов?». Используя новые выделенные атрибуты itemscope , itemtype и itemprop , Microdata избегает этой путаницы.
Другое ограничение для микроформатов заключается в том, что любые данные, которые вы хотите включить, должны находиться внутри одного родительского элемента, что может быть ограничением, особенно если у вас есть соответствующая информация, скажем, в нижнем колонтитуле вашего сайта.
Включение элементов за пределы родительского элемента с Itemref
Давайте предположим, что внизу страницы у нас был нижний колонтитул со списком сносок о тексте об Одре Лорде выше. Если бы сноски были ссылками, было бы хорошо включить их как itemprop=”url” в нашу разметку.
<section itemscope itemtype=”http://schema.org/Person”> <span itemprop=”name”>Audre Lorde</span> was an <span itemprop=”jobTitle”>author,</span> <span itemprop=”jobTitle”>academic,</span> <span itemprop=”jobTitle”>activist</span> and <span itemprop=”jobTitle”>poet</span>, known for her many contributions to feminist literature and thought[<a href=”#citation1”>1</a>]. <!-- snip --> </section> <!-- more HTML --> <footer> <a name=”citation1”>[1]</a> <a id=”cite1” itemprop=”url” href=”http://en.wikipedia.org/wiki/Audre_Lorde”> Audre Lorde on Wikipedia </a> </footer>
Как мы можем включить эту ссылку в нашем нижнем колонтитуле на странице? Используя атрибут itemref в теге открытия раздела:
<section itemscope itemtype=”http://schema.org/Person” itemref=”cite1”>
Это скажет поисковым системам также извлекать релевантный контент из элемента с id cite1, как наш элемент link в нижнем колонтитуле.
Что если вы хотите сослаться на более чем один id позже на странице? Способ сделать это — просто указать разделенный пробелами список id в itemref , так же как вы можете указать несколько атрибутов class , используя разделенный пробелами список.
Резюме
Микроданные позволяют нам пометить наши существующие элементы и текст машиночитаемыми метками, что позволяет нашим сайтам более четко видеть и понимать основные поисковые системы. Google, Yahoo! И Microsoft собралась вместе, чтобы дать нам богатый словарный запас вещей, которые мы можем описать с помощью http://schema.org . И как надлежащая часть спецификации HTML5 с ее собственными выделенными атрибутами, небольшая дополнительная работа может дать вам реальное преимущество в результатах поиска.
Дополнительные ресурсы
Руководство по началу работы
Google Rich Snippets
Инструмент тестирования Rich Snippets