Одной из важных вещей, которые мне нравятся в моей работе, является то, что я являюсь частью команды разработчиков программного обеспечения, которая не только создает программное обеспечение для людей, но и активно управляет веб-инфраструктурой с высоким трафиком. Это означает, что, как разработчики, мы живем с технической задолженностью, которую мы создаем, и мы используем наше лучшее суждение, чтобы помочь погасить эту задолженность, когда это имеет смысл. Недавно мы просматривали графики мониторинга и заняли некоторое время, чтобы посмотреть на наши экземпляры memcached. Этот конкретный клиент использует Circonus и имеет метрики, настроенные для кэша памяти, включая общий объем памяти, скорость выборки / размещения (как запросов, так и байтов) и частоту попаданий / промахов.
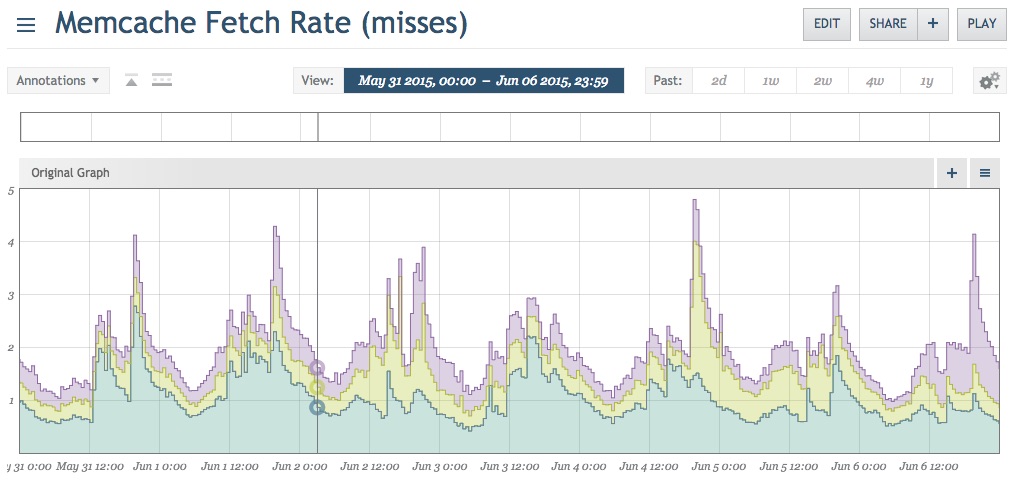
Эти пропуски не особенно велики по объему, однако пропуски в кеше часто являются признаком того, что что-то в системе может быть быстрее. Их может стоить исследовать, прежде чем объем трафика увеличится, и небольшая неэффективность начнет накапливаться.
Диагностирование
Мы знаем, что случаются промахи, но у нас есть вызовы кеша по всему коду. Чтобы отследить это, нам нужно увидеть, что на самом деле происходит в системе, чтобы наблюдать за тем, что упускается. К сожалению, memcached не предоставляет внутреннего механизма для этого, что делает эту задачу достаточно сложной, так что некоторые люди написали сторонние приложения, специально предназначенные для этого, такие как mctop. К счастью для меня, эти системы работают на Illumos, поэтому мы получаем выгоду от dtraceutility. Dtrace позволяет мне детально осматривать производственные системы практически без риска, поэтому мы можем посмотреть непосредственно на один из экземпляров memcache и посмотреть, что происходит в режиме реального времени. Вместо того, чтобы писать свой собственный, мы использовали отличный сценарий memcached dtrace от Matt Ingenthron, который он любезно делает доступным по адресу https://gist.github.com/ingenthr/6116473.
Запустив скрипт потока ключей на одном из производственных компьютеров, мы видим ключи по мере их извлечения или установки.
$ sudo ~/memcache_scripts/keyflow.d
get OGefRqwX:45220, FOUND KEY
get H02pZPjq:2087rulessml::en, FOUND KEY
get 3P4iT8M/:4, FOUND KEY
get WETtYDA0:__special_reg_map, FOUND KEY
get WETtYDA0:__special_reg_map, FOUND KEY
get 3P4iT8M/:4, FOUND KEY
get suB5w6XF:683112, FOUND KEY
get 3P4iT8M/:4, FOUND KEY
get WETtYDA0:1:default, FOUND KEY
get WETtYDA0:1:default, FOUND KEY
get H02pZPjq:2087rulessml::en, FOUND KEY
get 3P4iT8M/:4, FOUND KEY
...Что показывает команды и ключи memcache; «get», говоря: «получить это из memcached», ключ, который он пытается получить, и результат. Внутренний код кэширования этого клиента использует модуль-обертку для ключей пространства имен на основе их модуля (первые 9 символов), а затем предоставленного разработчиком ключа.
Мы действительно заботимся только о промахах, поэтому давайте отфильтруем только те:
$ sudo ~/memcache_scripts/keyflow.d | grep NOT
get WETtYDA0:1:Win-A-Mercedes-Benz, NOT FOUND
get OGefRqwX:98801, NOT FOUND
get OGefRqwX:78634, NOT FOUND
...Наблюдая за этим немного, мы заметили несколько общих недостатков при кешировании. Мы выбрали ключ, который, казалось, показывался с высокой частотой («rest_api: gmail.com») и начали оттуда.
Ошибки не всегда ваша ошибка
У этого ключа было пространство имен, поэтому мы можем начать с рассмотрения потока ключей, выполняя поиск этого пространства имен.
$ sudo ~/memcache_scripts/keyflow.d | grep rest_api
get rest_api:hotmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:yahoo.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUNDREST API клиента Node.js неоднократно выполнял вызовы memcache для выборки с одного и того же домена. Распространенный шаблон после пропуска кэша — сделать запрос к авторитетному источнику, а затем установить это значение в кэше в следующий раз. В этом случае мы не видим никаких наборов, только выборки для одного и того же элемента несколько раз. Время копаться.
Мы смогли быстро определить, где был сделан кеш-вызов. Этот клиент отклоняет регистрации через API для доменов, которые являются членами его черного списка. Список очень большой, поэтому мы хотим только кэшировать текущие «горячие» домены и вернуться к проверке базы данных для остальных. Код для этого был довольно прост.
// Try to find the domain in the cache
mc.get(key, function(err, data){
if(err || “undefined” === typeof data){
// Hit the database if nothing was found
return queryIllegalDomainEmail( email.domain, function(err, res){
if(err){
return callback(err);
}
// Cache what we got from the db
mc.set(key, res, 3600);
return callback(null, res);
});
} else {
return callback(null, data);
}
});Если ключ не находится в кеше, запросите его, установите его и продолжайте. Код игнорирует возвращаемые значения из set (), так как в случае ошибки мы на самом деле ничего не будем с этим делать. Чтобы отладить проблему, мы добавляем функцию обратного вызова, чтобы увидеть ответ. Странно, с этого момента все заработало! Мы могли видеть команды «set», идущие в memcached из скрипта dtrace. Углубившись вглубь вызова функции set (), мы обнаружим, что это на самом деле проблема с модулем npm, который мы используем для обработки memcached. Если обратный вызов не предоставлен функции set (), модуль проверки модуля не видит его как функцию и считает, что существует несоответствие типов. Затем он пытается вернуть ошибку, используя предоставленный обратный вызов, который не существует, поэтому он ничего не делает; молча терпит неудачу. Это ужасный случай провала.Если требуется функция обратного вызова, она должна выйти из строя громко и немедленно. Если это не требуется, то он должен продолжать работать, как ожидается; при условии, что с запросом ничего не случилось. Весь остальной код пакета написан для правильной работы, если не предоставлен обратный вызов, поэтому изменение функции проверки в исходном коде модуля npm для разрешения неопределенных обратных вызовов — это все, что было необходимо.
Мы создали проблему в репозитории github модуля и отправили в проект запрос на извлечение с тестовым примером. Посмотрим, согласны ли они.
Кэширование для отрицательных ответов
Следующей по значимости причиной пропуска кэша была распространенная ошибка. При проверке кэша мы часто говорим: «Каково значение X?» Если мы не найдем его, мы проверим достоверный источник. Но что, если у авторитетного источника его тоже нет? Часто мы просто идем дальше. Взять, к примеру, код отслеживания, отправленный на страницу покупки. Определенные коды автоматически дают кому-то скидку 10%, поэтому нам нужно проверить, является ли это специальный код. Если это не так, то мы ничего не делаем. Это был один из тех случаев. Однако в подавляющем большинстве случаев большинство этих поисков ничего не возвращают, поскольку они использовались только для отслеживания. «Ничто» также является значением и может быть кэшировано. Кэшируя отрицательный ответ или отсутствие значения, страница может продолжать избегать медленного поиска в базе данных. Это улучшает время загрузки страницы в общем случае.Важно помнить ваши бизнес-правила для аннулирования этих данных. Если добавляется скидка, сколько времени понадобится истечению ваших значений в кэше, чтобы отразить новое значение?
Не возвращай то, что ты уже знаешь
Следующий пункт немного сложнее диагностировать. Просматривая некоторые шаблоны доступа, мы заметили, что один и тот же ключ часто выбирается несколько раз подряд. Любопытно, почему это был столь востребованный ключ, и мы его исследовали.
Есть много вещей, которые люди ненавидят в объектно-ориентированном программировании, но особая любознательность заключается в том, что подход «черного ящика» часто скрывает, насколько дорогими могут быть конкретные вызовы. У этого клиента есть несколько разных представлений, которые могут отображаться для страницы в зависимости от контекста, и часто разные варианты поведения включаются / выключаются в зависимости от этого конкретного представления. Эти флаги будут предоставлены путем создания объекта Page и проверки его. например:
my $page = new PageObject( $request );
if( $page->do_the_thing() ) {
// Do the thing.
}Поскольку функции были добавлены / удалены, эти вызовы в конечном итоге были разбросаны по всему коду, где бы ни был проверен флаг. Этот конструктор, неизвестный программисту, извлекает эти флаги из memcache. После нескольких месяцев запросов новых возможностей код теперь должен получать те же данные из memcache 7-10 раз при загрузке одной страницы. С помощью небольшого рефакторинга этого легко избежать, выбирая данные один раз в начале и передавая объект различным логическим путям, которые следовали. Вызовы Memcache в нашей сети составляют всего несколько миллисекунд, но эти миллисекунды складываются.
Полученные результаты
Этот график состоит из двух дней до и после исправления. Показатели пропусков практически сведены к нулю:
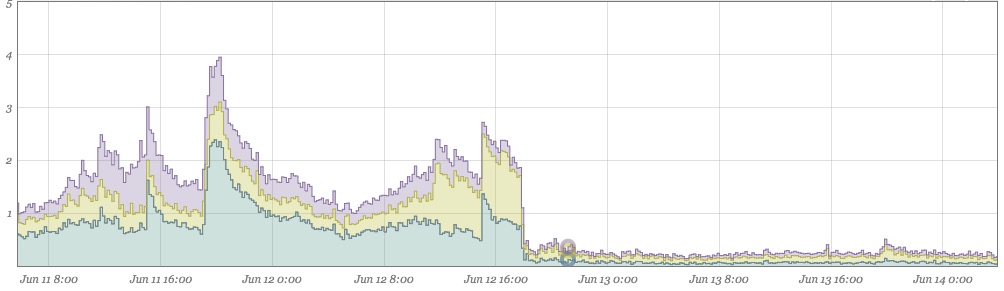
Так же, как и приветствие (ниже), объем попаданий в кеш теперь также уменьшается из-за того, что больше не получает одно и то же значение несколько раз при одной и той же загрузке страницы. На приведенном ниже графике слева показана новая модель трафика, наложенная на предыдущую неделю. После отправки мы видим примерно 10-20% -ное снижение общего количества выборок memcached. Все это экономит время, быстрее доставляя страницы клиентам.
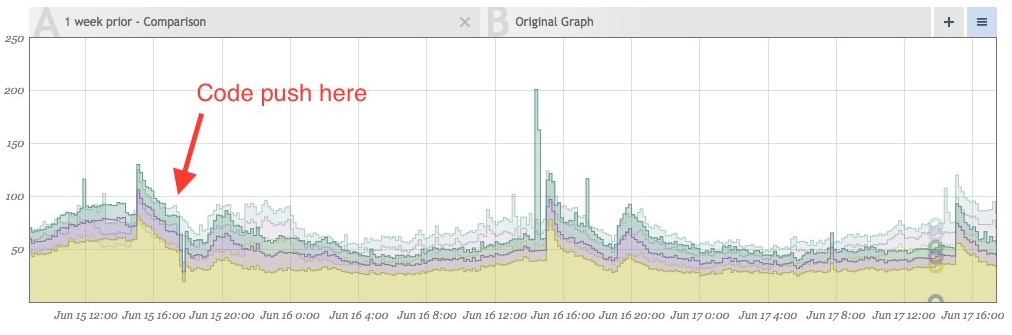
Удаление шума делает события более заметными
После очистки наших данных отсутствие шума делает события, отклоняющиеся от нормы, еще более наглядными. Вскоре после внедрения вышеуказанных исправлений это выскочило у нас:
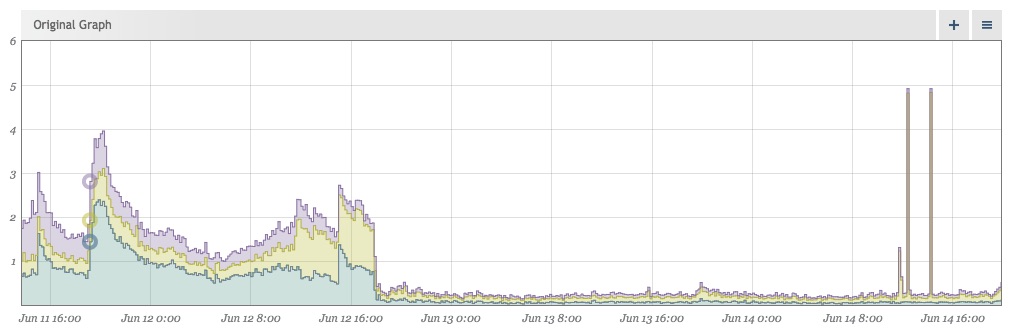
Убедитесь, что ваши собственные библиотеки правильны
В то время как мы могли смотреть на трафик в реальном времени для нашей предыдущей проблемы, расследование этих всплесков должно было быть выполнено после факта, но нам все равно нужно было выяснить, что же происходит. Взяв некоторые из журналов трафика с того времени, мы смогли воспроизвести часть трафика и найти виновника. Это было довольно относительно.
get WETtYDA0:1:999999.9', NOT FOUND
get union, NOT FOUND
get all, NOT FOUND
get WETtYDA0:1:CertifiedWinnerRSP, FOUND KEY
get WETtYDA0:1:default, FOUND KEY
get WETtYDA0:1:999999.9', NOT FOUND
get union, NOT FOUND
get all, NOT FOUND
get WETtYDA0:1:CertifiedWinnerRSP, FOUND KEY
get WETtYDA0:1:default, FOUND KEY
get WETtYDA0:1:999999.9', NOT FOUND
get union, NOT FOUND
get all, NOT FOUND
get WETtYDA0:1:CertifiedWinnerRSP, FOUND KEY
get WETtYDA0:1:default, FOUND KEYПохоже, мы пытались извлечь фрагменты SQL-запросов из memcache. Конечно же, расследование показывает, что сайт сканировался в тот момент. Попытка внедрения SQL приводила к дополнительным выборкам ключей кэша.
Мы могли бы воспроизвести ошибку, ударив одну из наших машин разработчиков следующим:
https://dev.site.com/page?.9%27%20union%20all%20Это переводит в значение типа:
“999999.9' union all”Те же три ключа, которые мы пытались получить.
This turned out to be a bug with the internal wrapper module. The module would just accept whatever key it was given and attempt to fetch it. This does not play nicely with the memcache protocol. A memcache key may not contain any whitespace or control characters, and must be <= 250 characters. Whitespace in the get request are used to allow someone to fetch multiple keys with a single fetch command, which is what we were doing and the reason why dtrace showed it as three separate fetches. Since our module would just take the first response and ignore the rest, there was no vulnerability here (yay!), just inefficiencies. Doing multiple gets at once is a great technique to combine requests, but the context of this module is assuming a single key get request.
To fix it, the module was modified to strip invalid values out. The example would now attempt to fetch:
'WETtYDA0:1:999999.9unionall'This would be a single fetch attempt, cache miss, and life would go on.
Conclusions
1. Caching is a great tool, but like all parts of a system, it’s worth revisiting things now and again to make sure things are working the way they should be. It may be possible to find some cheap performance gains and some good examples of anti-patterns.
2. There’s a lot of benefits to monitoring beyond just looking for errors. None of these bugs were particularly bad, in fact, most of them still produced the correct outcome. Monitoring isn’t always to show where mistakes are, but where improvements can be made, and just as importantly to show if they were successful or not.