Распространенным мифом в SQL является идея, что коррелированные подзапросы являются злыми и медленными. Например, этот запрос здесь:
|
1
2
3
4
5
6
|
SELECT first_name, last_name, (SELECT count(*) FROM film_actor fa WHERE fa.actor_id = a.actor_id)FROM actor a |
Это «заставляет» ядро базы данных запускать вложенный цикл в форме (в псевдокоде):
|
1
2
3
4
5
6
7
|
for (Actor a : actor) { output( a.first_name, a.last_name, film_actor.where(fa -> fa.actor_id = a.actor_id) .size()} |
Итак, для каждого актера соберите все соответствующие film_actors и посчитайте их. Это даст количество фильмов, в которых играл каждый актер.
Похоже, что было бы гораздо лучше выполнить этот запрос «оптом», т.е. выполнить:
|
1
2
3
4
5
|
SELECT first_name, last_name, count(*)FROM actor aJOIN film_actor fa USING (actor_id)GROUP BY actor_id, first_name, last_name |
Но так ли это быстрее? И если так, почему вы ожидаете этого?
Массовая агрегация против вложенных циклов
Массовая агрегация в этом случае на самом деле означает, что мы собираем всех актеров и все film_actors, а затем объединяем их в памяти для группы по операции. План выполнения (в Oracle) выглядит следующим образом:
|
1
2
3
4
5
6
7
8
9
|
-------------------------------------------------------------------| Id | Operation | Name | A-Rows |-------------------------------------------------------------------| 0 | SELECT STATEMENT | | 200 || 1 | HASH GROUP BY | | 200 ||* 2 | HASH JOIN | | 5462 || 3 | TABLE ACCESS FULL | ACTOR | 200 || 4 | INDEX FAST FULL SCAN| IDX_FK_FILM_ACTOR_ACTOR | 5462 |------------------------------------------------------------------- |
В нашей таблице film_actor имеется 5462 строки, и для каждого актера мы объединяем, группируем и объединяем их все, чтобы получить результаты. Давайте сравним это с планом вложенного цикла:
|
1
2
3
4
5
6
7
8
|
-----------------------------------------------------------------------| Id | Operation | Name | Starts | A-Rows |-----------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 200 || 1 | SORT AGGREGATE | | 200 | 200 ||* 2 | INDEX RANGE SCAN| IDX_FK_FILM_ACTOR_ACTOR | 200 | 5462 || 3 | TABLE ACCESS FULL| ACTOR | 1 | 200 |----------------------------------------------------------------------- |
Теперь я включил строку «Начинается», чтобы проиллюстрировать, что, собрав все 200 актеров, мы запускаем подзапрос 200 раз, чтобы получить счет для каждого актера. Но на этот раз с дальностью сканирования.
Только из плана, мы можем сказать, какой из них быстрее? Массовая агрегация потребует больше памяти (для загрузки всех данных), но имеет меньшую алгоритмическую сложность (линейную). Для вложенного цикла потребуется меньше памяти (вся необходимая информация доступна из индекса напрямую), но, похоже, он имеет более высокую алгоритмическую сложность (квадратичную).
На самом деле это не совсем так.
Суммарная агрегация действительно линейна, но согласно O (M + N), где M = количество актеров и N = количество film_actors, тогда как вложенные циклы не квадратичны, это O (M log N). Нам не нужно пересматривать весь индекс, чтобы получить счет.
В какой-то момент, чем выше сложность, тем хуже, но с этим небольшим количеством данных это не так:
На оси х указан размер N, а на оси у — «значение сложности», например, сколько времени (или памяти) используется алгоритмом.
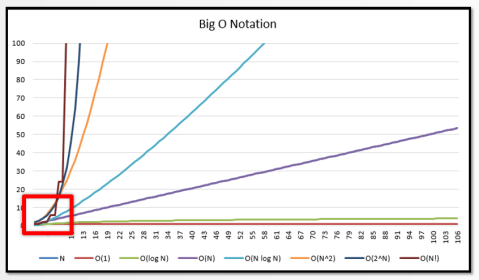
Эффекты алгоритмической сложности для больших N
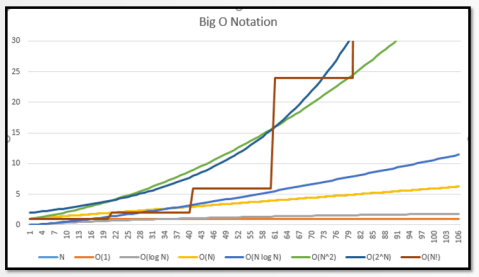
Эффекты алгоритмической сложности для «малого» N
Вот заявление об отказе от вышеуказанного:
Алгоритмическая сложность для «маленького N» = «работает на моей машине»
Нет ничего лучше, чем проверять вещи измерениями. Давайте запустим следующую программу PL / SQL:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
SET SERVEROUTPUT ONDECLARE v_ts TIMESTAMP; v_repeat CONSTANT NUMBER := 1000;BEGIN v_ts := SYSTIMESTAMP; FOR i IN 1..v_repeat LOOP FOR rec IN ( SELECT first_name, last_name, (SELECT count(*) FROM film_actor fa WHERE fa.actor_id = a.actor_id) FROM actor a ) LOOP NULL; END LOOP; END LOOP; dbms_output.put_line('Nested select: ' || (SYSTIMESTAMP - v_ts)); v_ts := SYSTIMESTAMP; FOR i IN 1..v_repeat LOOP FOR rec IN ( SELECT first_name, last_name, count(*) FROM actor a JOIN film_actor fa USING (actor_id) GROUP BY actor_id, first_name, last_name ) LOOP NULL; END LOOP; END LOOP; dbms_output.put_line('Group by : ' || (SYSTIMESTAMP - v_ts));END;/ |
После трех запусков и в сравнении со стандартной базой данных Sakila (получите ее здесь: https://github.com/jOOQ/jOOQ/tree/master/jOOQ-examples/Sakila ) с 200 актерами и 5462 film_actors, мы видим, что вложенные Выберите последовательно превосходит массовую группу по:
|
1
2
3
4
5
6
7
8
|
Nested select: +000000000 00:00:01.122000000Group by : +000000000 00:00:03.191000000Nested select: +000000000 00:00:01.116000000Group by : +000000000 00:00:03.104000000Nested select: +000000000 00:00:01.122000000Group by : +000000000 00:00:03.228000000 |
Помогаем оптимизатору
Некоторые интересные отзывы от Маркуса Винанда (автора http://sql-performance-explained.com ) были даны в Твиттере:
Существует третий вариант: вложение операции GROUP BY в производную таблицу:
|
1
2
3
4
5
6
7
8
|
SELECT first_name, last_name, cFROM actor aJOIN ( SELECT actor_id, count(*) c FROM film_actor GROUP BY actor_id) USING (actor_id) |
который производит немного лучший план, чем «обычная» группа по запросу:
|
01
02
03
04
05
06
07
08
09
10
|
--------------------------------------------------------------------| Id | Operation | Name | A-Rows |--------------------------------------------------------------------| 0 | SELECT STATEMENT | | 200 ||* 1 | HASH JOIN | | 200 || 2 | TABLE ACCESS FULL | ACTOR | 200 || 3 | VIEW | | 200 || 4 | HASH GROUP BY | | 200 || 5 | INDEX FAST FULL SCAN| IDX_FK_FILM_ACTOR_ACTOR | 5462 |-------------------------------------------------------------------- |
Добавляем его в бенчмарк как таковой:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
SET SERVEROUTPUT ONDECLARE v_ts TIMESTAMP; v_repeat CONSTANT NUMBER := 1000;BEGIN v_ts := SYSTIMESTAMP; FOR i IN 1..v_repeat LOOP FOR rec IN ( SELECT first_name, last_name, (SELECT count(*) FROM film_actor fa WHERE fa.actor_id = a.actor_id) FROM actor a ) LOOP NULL; END LOOP; END LOOP; dbms_output.put_line('Nested select : ' || (SYSTIMESTAMP - v_ts)); v_ts := SYSTIMESTAMP; FOR i IN 1..v_repeat LOOP FOR rec IN ( SELECT first_name, last_name, count(*) FROM actor a JOIN film_actor fa USING (actor_id) GROUP BY actor_id, first_name, last_name ) LOOP NULL; END LOOP; END LOOP; dbms_output.put_line('Group by : ' || (SYSTIMESTAMP - v_ts)); v_ts := SYSTIMESTAMP; FOR i IN 1..v_repeat LOOP FOR rec IN ( SELECT first_name, last_name, c FROM actor a JOIN ( SELECT actor_id, count(*) c FROM film_actor GROUP BY actor_id ) USING (actor_id) ) LOOP NULL; END LOOP; END LOOP; dbms_output.put_line('Group by in derived table: ' || (SYSTIMESTAMP - v_ts));END;/ |
… Показывает, что он уже очень близок к вложенной опции выбора:
|
1
2
3
4
5
6
7
|
Nested select : +000000000 00:00:01.371000000Group by : +000000000 00:00:03.417000000Group by in derived table: +000000000 00:00:01.592000000Nested select : +000000000 00:00:01.236000000Group by : +000000000 00:00:03.329000000Group by in derived table: +000000000 00:00:01.595000000 |
Вывод
Мы показали, что при некоторых обстоятельствах коррелированные подзапросы могут быть лучше, чем массовая агрегация. В Oracle. С наборами данных малого и среднего размера. В других случаях это не так, поскольку размер M и N, наши две алгоритмические переменные сложности увеличиваются, O (M log N) будет намного хуже, чем O (M + N).
Вывод: не доверяйте никаким первоначальным суждениям Мера. Когда вы выполняете такой запрос много раз, 3-кратное замедление может иметь большое значение. Но не идите и заменяйте все ваши массовые скопления
Понравилась эта статья? Контент является частью нашего тренинга по производительности Data Geekery SQL
| Ссылка: | Коррелированные подзапросы злые и медленные. Или они? от нашего партнера JCG Лукаса Эдера в блоге JAVA, SQL и JOOQ . |