 В этом посте я объясню конфигурации распределения ресурсов для Spark на YARN, опишу режимы yarn-client и yarn-cluster и приведу примеры.
В этом посте я объясню конфигурации распределения ресурсов для Spark на YARN, опишу режимы yarn-client и yarn-cluster и приведу примеры.
Spark может запросить два ресурса в YARN: процессор и память. Обратите внимание, что конфигурации Spark для распределения ресурсов устанавливаются в spark-defaults.conf с именем, подобным spark.xx.xx. Некоторые из них имеют соответствующий флаг для клиентских инструментов, таких как spark-submit / spark-shell / pyspark, с именем, например -xx-xx. Если конфигурация имеет соответствующий флаг для клиентских инструментов, необходимо поставить флаг после конфигурации в круглых скобках »()». Например:
|
1
2
|
spark.driver.cores (--driver-cores) |
1. пряжа-клиент против режима пряжи-кластера
Существует два режима развертывания, которые можно использовать для запуска приложений Spark на YARN:
По документации Spark :
- В режиме клиент-пряжа драйвер запускается в клиентском процессе, а мастер приложения используется только для запроса ресурсов из YARN.
- В режиме кластера пряжи драйвер Spark запускается в главном процессе приложения, которым управляет YARN в кластере, и клиент может уйти после запуска приложения.
2. Мастер приложений (AM)
а. Нить-клиент
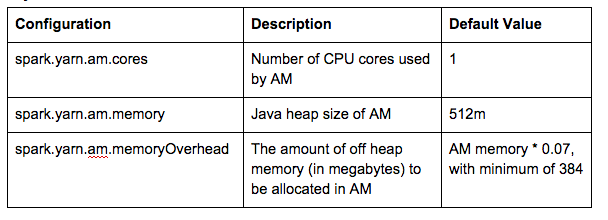
Давайте посмотрим на настройки ниже в качестве примера:
|
1
2
3
|
[root@h1 conf]# cat spark-defaults.conf |grep amspark.yarn.am.cores 4spark.yarn.am.memory 777m |
По умолчанию spark.yarn.am.memoryOverhead имеет значение AM memory * 0,07 с минимальным значением 384. Это означает, что если мы установим для spark.yarn.am.memory значение 777M, фактический размер AM-контейнера будет равен 2G. Это связано с тем, что 777 + Min (384, 777 * 0,07) = 777 + 384 = 1161 и значение по умолчанию yarn.scheduler.minimum-distribution-mb = 1024, поэтому контейнер 2 ГБ будет выделен для AM. В результате выделяется AM-контейнер (2G, 4 ядра) с размером кучи Java -Xmx777M:
Назначенный контейнер контейнер_1432752481069_0129_01_000001 вместимости
|
1
|
<memory:2048, vCores:4, disks:0.0> |
б. Пряжа-кластер
В режиме кластера пряжи драйвер Spark находится внутри YARN AM. Связанные с драйвером конфигурации, перечисленные ниже, также управляют распределением ресурсов для AM.
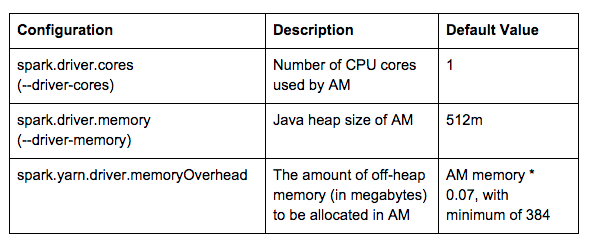
Взгляните на настройки ниже в качестве примера:
|
1
2
3
4
|
MASTER=yarn-cluster /opt/mapr/spark/spark-1.3.1/bin/spark-submit --class org.apache.spark.examples.SparkPi \--driver-memory 1665m \--driver-cores 2 \/opt/mapr/spark/spark-1.3.1/lib/spark-examples*.jar 1000 |
Поскольку 1665 + Min (384,1665 * 0,07) = 1665 + 384 = 2049> 2048 (2G), контейнер 3G будет выделен для AM. В результате выделяется AM-контейнер (3G, 2 ядра) с размером кучи Java -Xmx1665M:
Назначенный контейнер контейнер_1432752481069_0135_02_000001 вместимости:
|
1
|
<memory:3072, vCores:2, disks:0.0> |
3. Контейнеры для исполнителей Spark
Для ресурсов исполнителя Spark режимы yarn-client и yarn-cluster используют одинаковые конфигурации:
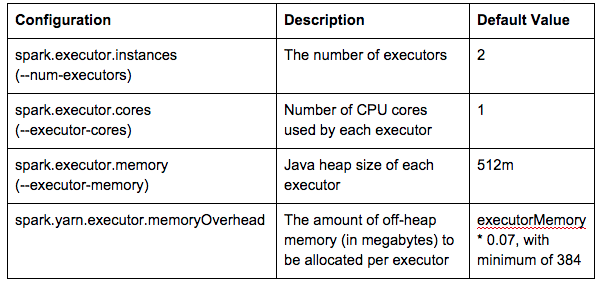
В файле spark-defaults.conf для параметра spark.executor.memory установлено значение 2g.
Spark запустит 2 (3G, 1-ядерный) контейнера-исполнителя с размером кучи Java -Xmx2048M: Назначенный контейнер container_1432752481069_0140_01_000002 вместимости:
|
1
|
<memory:3072, vCores:1, disks:0.0> |
Назначенный контейнер-контейнер_1432752481069_0140_01_000003 вместимости:
|
1
|
<memory:3072, vCores:1, disks:0.0> |
Тем не менее, одно ядро для каждого исполнителя означает, что в любое время для одного исполнителя может выполняться только одна задача. В случае широковещательного соединения память может совместно использоваться несколькими запущенными задачами в одном исполнителе, если мы увеличим количество ядер на исполнителя.
Обратите внимание, что если динамическое распределение ресурсов включено, если для параметра spark.dynamicAllocation.enabled установлено значение true, Spark может масштабировать количество исполнителей, зарегистрированных в этом приложении, в зависимости от рабочей нагрузки. В этом случае вам не нужно указывать spark.executor.instances вручную.
Ключевые вынос
- Конфигурации, связанные с ресурсами драйвера Spark, также управляют главным ресурсом приложения YARN в режиме кластера пряжи.
- При подсчете памяти для исполнителей учитывайте максимальную (7%, 384 м) служебную память вне кучи.
- Количество ядер процессора на исполнителя определяет количество одновременных задач на исполнителя.
В этом посте вы узнали о настройках распределения ресурсов для Spark на YARN. Если у вас есть какие-либо дополнительные вопросы, пожалуйста, задавайте их в разделе комментариев ниже.
| Ссылка: | Конфигурация распределения ресурсов для Spark на YARN от нашего партнера JCG Хао Чжу в блоге Mapr . |