Начиная с версии 2.0, сервер Couchbase предлагает мощный способ создания индексов для документов JSON посредством концепции представлений.
Используя представления, можно определить первичные индексы, составные индексы и агрегаты, позволяющие:
, запрашивать документы по различным свойствам JSON
, создавать статистику и агрегаты
Представления генерируют материализованные индексы, поэтому обеспечивают быстрый и эффективный способ выполнения предопределенных запросов.
Однако в Couchbase 2.x индексы хранятся на диске и считываются с диска для каждого запроса, что имеет некоторые последствия для производительности.
В будущем Couchbase позволит кэшировать индексы в управляемый кеш, аналогично тому, что делается для документов JSON для ускорения запросов.
В то же время этот блог представляет собой простой пример того, как результаты запроса могут кэшироваться в Couchbase для извлечения из кэша, а не для обслуживания из индекса на диске.
Это полезно для сценариев, в которых запрос индекса не обязательно должен быть обновлен немедленно (минуты или больше в порядке), но часто читается (несколько раз в секунду). В этом случае результаты запроса будут рассчитываться очень часто на основе потребностей приложения и считываться из управляемого кэша в остальное время.
Хорошим примером использования для этого является таблица лидеров игры. Представление можно использовать для создания индекса лучших результатов для конкретной игры, и такое представление можно запрашивать каждые несколько минут (например, 5 минут) и кэшировать на Couchbase Server. Все запросы к представлению будут идти против кэшированного значения и, как таковые, будут принимать только мс и не требуют никаких запросов индекса на сервере.
Обратите внимание, что описанный выше метод не зависит от автоматического обновления индексов. По умолчанию каждый индекс в Couchbase обновляется каждые 5 секунд или 5000 обновлений, которые настраиваются через REST API. Узнайте больше об этом по адресу: http://www.couchbase.com/docs/couchbase-manual-2.1.0/couchbase-views-operation-autoupdate.html
Таким образом, это означает, что, хотя индекс можно поддерживать в актуальном состоянии, конкретные запросы, которые не обязательно должны быть актуальными, могут кэшироваться для более высокой пропускной способности и более низкой задержки. Единственное предостережение в том, что максимальная длина значений в Couchbase составляет 20 МБ, поэтому кэшированные запросы не следует использовать для наборов результатов большого размера, хотя всегда можно разделить результаты на несколько кэшированных значений для наборов большего размера.
Это довольно просто реализовать, давайте посмотрим, как мы можем сделать это в Java.
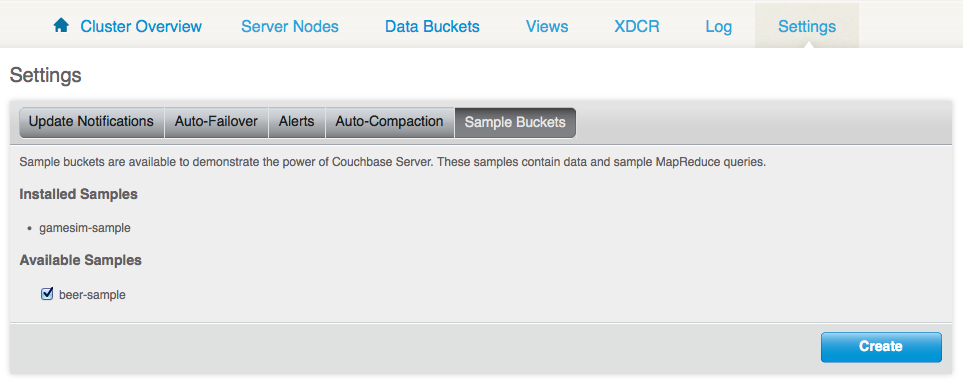
Я буду использовать базу данных bee-sample, которая поставляется с сервером Couchbase. Если вы еще не установили его, зайдите в Настройки и выберите образец пива, затем нажмите «Создать»:
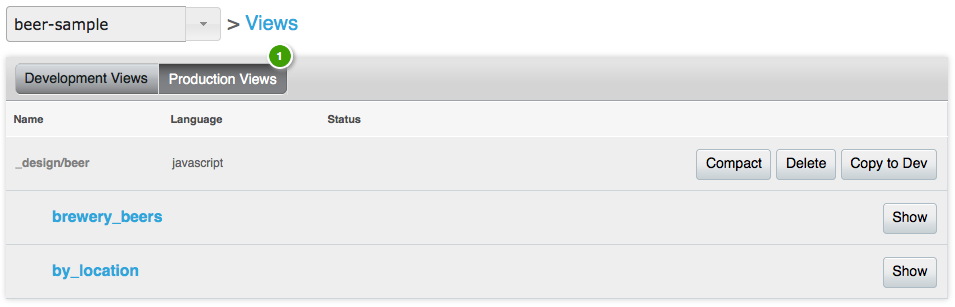
Это идет с представлением brewery_beer, которое я буду использовать для построения примера кэширования:
Теперь давайте взглянем на простое Java-приложение, которое можно использовать для выполнения и кэширования запроса, и сравнивать с выполнением запроса каждый раз.
Код Java, приведенный ниже, сначала подключается к базе данных bee-sample и:
, выполняет запрос 1 раз и читает его из кэша n раз или
, выполняет запрос n раз
В обоих случаях таймер запускается до и после измерения времени выполнения.
Код очень прост, не использует параметры для запроса, но использует includeDocs для извлечения всех документов JSON, связанных с результатами запроса, а не только идентификаторов документов.
Чтобы узнать больше о представлениях и запросах в Couchbase, прочитайте: http://www.couchbase.com/docs/couchbase-devguide-2.1.0/indexing-querying-data.html
Полный исходный код:
// @author Alexis Roos
package com.couchbase.dev.examples;
import com.couchbase.client.CouchbaseClient;
import com.couchbase.client.protocol.views.*;
import java.net.URI;
import java.util.LinkedList;
import java.util.List;
public class CachedQuery {
public static void main(String args[]) {
List<URI> uris = new LinkedList<URI>();
uris.add(URI.create("http://127.0.0.1:8091/pools"));
CouchbaseClient client = null;
try {
client = new CouchbaseClient(uris, "beer-sample", "");
int requestCount = 100;
double t1 = System.currentTimeMillis();
View view = client.getView("beer", "brewery_beers");
Query query = new Query();
query.setIncludeDocs(true).setLimit(10000);
query.setStale(Stale.FALSE);
// Doing query a single time and caching it
ViewResponse result = client.query(view, query);
client.set("cachedBrewery_beersQuery", 0, result.toString());
// Using cache for subsequent requests
for (int i = 0; i < requestCount - 1; i++) {
String cachedIndex = (String) client.get("cachedBrewery_beersQuery");
}
double t2 = System.currentTimeMillis();
System.out.println("Test with cache finished in " + (t2 - t1) / 1000 + " seconds");
t1 = System.currentTimeMillis();
// Querying every single time
for (int i = 0; i < requestCount; i++) {
result = client.query(view, query);
}
t2 = System.currentTimeMillis();
System.out.println("Test without cache finished in " + (t2 - t1) / 1000 + " seconds");
client.shutdown();
} catch (Exception e) {
System.err.println("Error connecting to Couchbase: " + e.getMessage());
System.exit(0);
}
}
}
Выполнение кода выводит оба результата теста, что для 100 последовательных запросов дает:
Test with cache finished in 3.755 seconds Test without cache finished in 19.835 seconds
Не только тестирование с кешем намного быстрее, но и требует меньше ресурсов на сервере Couchbase.
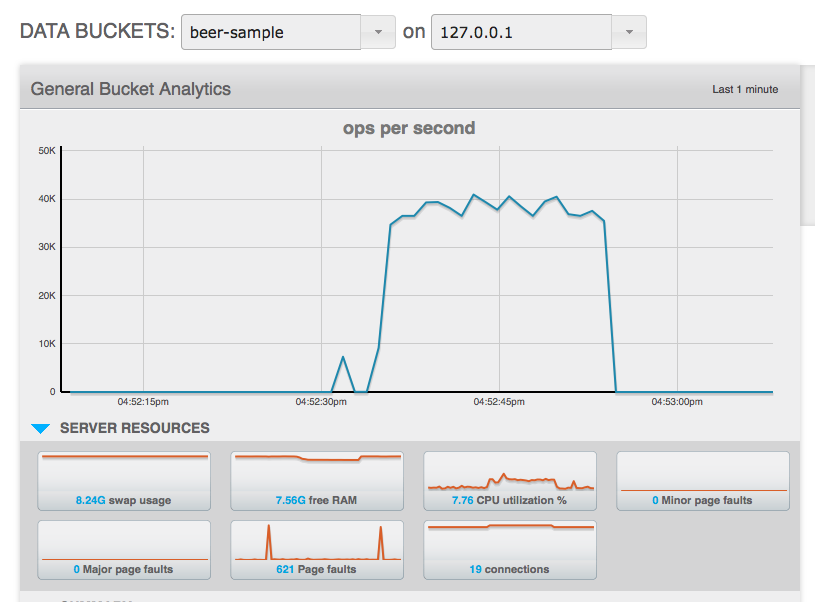
На следующем графике показана метрика операций в секунду для выборки пива, и первый небольшой выброс соответствует тесту с кешем (по сути, отображает количество документов для пивоваренных заводов и пива, поскольку запрос выполняется только один раз), тогда как остальные более крупная кривая показывает, что запрос выполнялся много раз и, как следствие, приводил к гораздо большему количеству операций в секунду.
Использовать кеширование для запросов к представлениям легко и просто настроить программу, которая будет периодически запрашивать представление и сохранять результат на сервере Couchbase, где он будет кэшироваться. В свою очередь, приложения могут использовать это кэшированное значение для эффективности.
Это следует использовать по мере необходимости в зависимости от случаев использования приложения.