В этой статье мы рассмотрим, что значит иметь конвергентную платформу данных для создания и доставки бизнес-приложений. Этот пример приложения будет создавать статьи блога для личного сайта.
На следующем рисунке показан поток данных и то, как приложение MapR-DB Rest использует OJAI API для взаимодействия с таблицами JSON MapR-DB. Затем мы рассмотрим, как запустить ANSI SQL с использованием Apache Drill 1.6 в тех же таблицах JSON MapR-DB, без необходимости преобразования или перемещения данных в другое место.
Получите что-нибудь в его естественной форме и используйте стандартные инструменты для аналитики на месте.
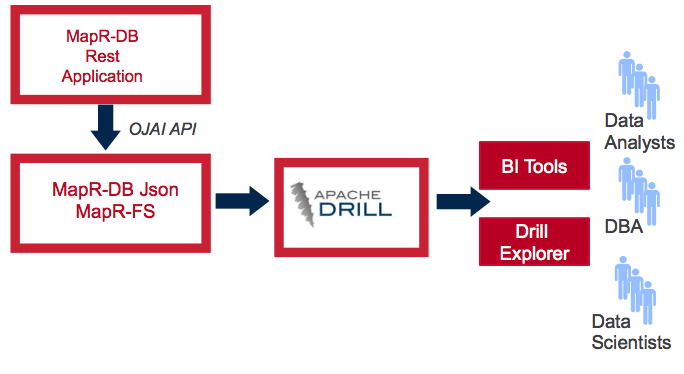
Это приложение MapR-DB REST содержит следующие компоненты:
- Основной класс, который запускает Jetty Server и настраивает интерфейс REST, используя JAX-RS
- Swagger для легкого доступа к HTTP API
- Приложение Angular JS, которое использует этот API
Для начала вам понадобится установка MapR или песочница с 5.1 и Apache Drill 1.6 с минимум 8 ГБ оперативной памяти. Если у вас это уже есть, перейдите в раздел «Настройка среды сборки».
Получение песочницы MapR 5.1 (если требуется)
Загрузите изолированную программную среду MapR 5.1, следуя инструкциям здесь http://maprdocs.mapr.com/51/index.html#SandboxHadoop/t_install_sandbox_vmware.html
Эта песочница должна иметь доступ к Интернету для завершения остальной части установки.
Убедитесь, что вы увеличили объем оперативной памяти с 6 до 8 Гбайт на виртуальной машине перед ее запуском Для Apache Drill потребуется 2 ГБ ОЗУ.
После установки и запуска песочницы вы должны увидеть следующий экран. Обратите внимание, я использую VM Fusion на Mac OSX
Войдите в кластер как mapr, обратите внимание, IP-адрес вашей Песочницы может отличаться от моего примера.
|
1
2
3
4
5
6
7
8
9
|
$ ssh mapr@192.168.185.248The authenticity of host '192.168.185.248 (192.168.185.248)' can't be established.RSA key fingerprint is 6a:36:ea:47:74:e6:57:92:e0:12:c4:8f:ee:64:09:20.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added '192.168.185.248' (RSA) to the list of known hosts.Password: maprWelcome to your Mapr Demo virtual machine.[mapr@maprdemo ~]$Password :- mapr |
Настройка среды сборки
Чтобы иметь возможность собрать приложение для восстановления MapR-DB, нам сначала нужно настроить Maven.
Эти инструкции установят Maven 3 на Centos, чтобы мы могли скомпилировать приложение OJAI. Пожалуйста, измените соответственно для дистрибутива на основе Ubuntu
|
01
02
03
04
05
06
07
08
09
10
11
|
$ su - rootPassword: mapr# yum install git# wget http://mirror.cc.columbia.edu/pub/software/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz# tar xvf apache-maven-3.3.9-bin.tar.gz -C /usr/local# cd /usr/local# ln -s apache-maven-3.3.9/ maven# vi /etc/profile.d/maven.shadd the following lines.export M2_HOME=/usr/local/mavenexport PATH=${M2_HOME}/ |
Выйдите из песочницы и вернитесь, чтобы получить эти изменения. Вы должны увидеть следующее.
|
01
02
03
04
05
06
07
08
09
10
11
|
$ ssh mapr@192.168.185.248Password: maprLast login: Thu Apr 7 23:58:05 2016 from 192.168.185.1Welcome to your Mapr Demo virtual machine.[mapr@maprdemo ~]$ mvn -versionApache Maven 3.3.9 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-10T08:41:47-08:00)Maven home: /usr/local/mavenJava version: 1.7.0_79, vendor: Oracle CorporationJava home: /usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jreDefault locale: en_GB, platform encoding: UTF-8OS name: "linux", version: "2.6.32-573.el6.x86_64", arch: "amd64", family: "unix" |
Загрузка и компиляция приложения MapR-DB Rest
Следующие инструкции сначала настроят структуру каталогов в MapR-FS, загрузят приложение для восстановления MapR-DB, скомпилируют его и, наконец, запустят.
Как пользователь MapR
|
1
2
3
4
5
6
7
8
|
# cd /mapr/demo.mapr.com/# chmod 777 apps# mkdir apps/blog# chmod 777 apps/blog# cd /home/mapr# git clone https://github.com/mapr-demos/maprdb-ojai-rest-sample.git# cd maprdb-ojai-rest-sample/# mvn clean package |
Наконец, запустите программу, введя следующую команду. Обратите внимание, что это заблокирует консоль, поэтому вам может понадобиться другая консоль в кластере для запуска дополнительных команд.
|
1
|
# mvn exec:java -Dexec.mainClass="com.mapr.db.samples.rest.Main" |
Обратите внимание, что иногда порт 8080 уже используется, это можно изменить, изменив порты в следующем файле и затем перекомпилировав приложение.
|
1
|
/home/mapr/maprdb-ojai-rest-sample/src/main/java/com/mapr/db/samples/rest/ Main.java |
Изучите приложение для отдыха MapR-DB
Пожалуйста, не стесняйтесь исследовать приложение Rest MapR-DB и создавать столько статей для вашего блога, сколько вам нужно для демонстрации или тестирования.
После запуска сервера вы можете получить доступ к интерфейсу Swagger, используя следующий URI:
- Http: // <ip_address>: 8080 / чванство
Или веб-приложения
- Http: // <ip_address>: 8080 / приложение / # /
Вы можете использовать веб-приложение для создания пользователя и публикации в блоге.
Затем в интерфейсе Swagger вы можете обнаружить некоторые интересные функции:
- Создать пользователя из предопределенного объекта JSON
|
1
|
{"_id":"2","first_name":"Leon","last_name":"Clayton","age":"46"} |
|
1
|
{"title":"Article1","content":"Here is the content","author":{"name":"leon clayton","id":"1"}} |
- Список пользователей, используя простую проекцию
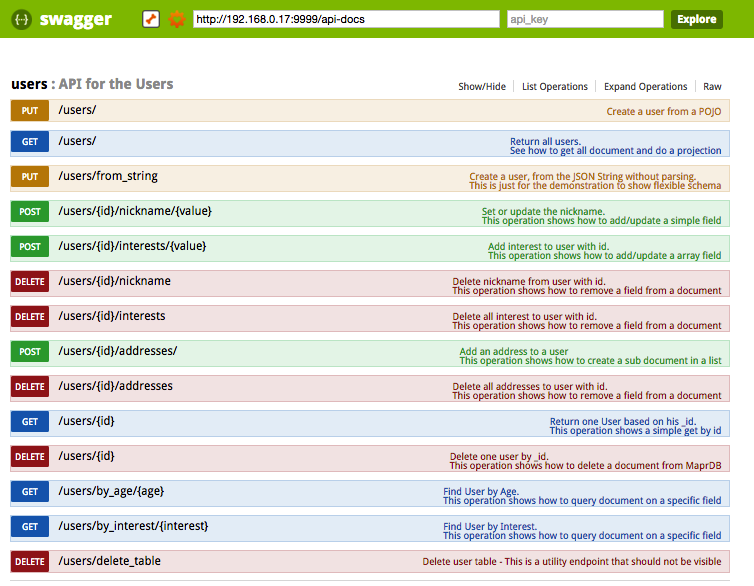
- Обновите пользователя, чтобы добавить псевдоним, добавить интересы и удалить эти атрибуты. Вы видите здесь гибкую схему в действии
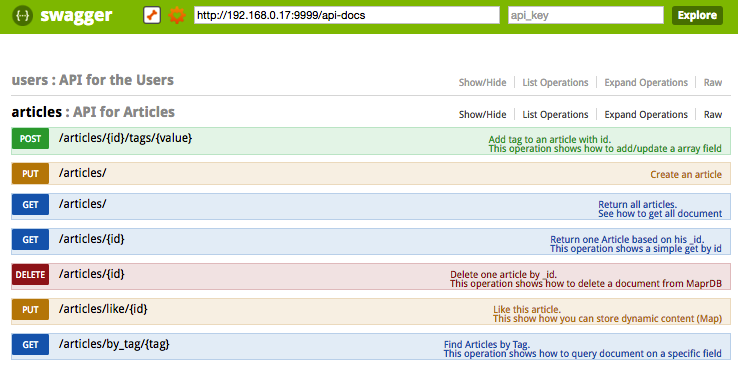
Подобные функции представлены в API REST для статей.
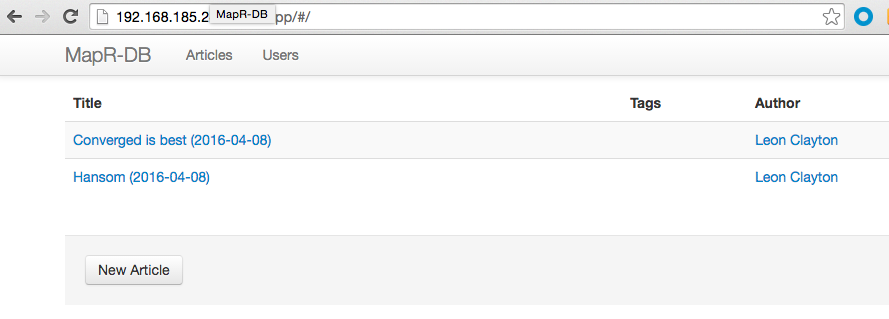
После того как вы создали несколько пользователей и постов, теперь мы можем использовать Apache Drill для доступа к тем же таблицам MapR-DB JSON.
Установка Apache Drill
Если вы используете MapR Sandbox, у вас уже должен быть установлен Apache Drill, но если в вашей установке не установлен Apache Drill, следуйте приведенным ниже инструкциям.
В качестве пользователя root нам нужно установить Apache Drill 1.6 или выше. Сначала очистите и обновите кэш yum, чтобы убедиться, что мы получили последнюю версию.
|
1
2
3
|
# su - root# yum clean all# yum makecache |
Пожалуйста, убедитесь, что следующее говорит Drill 1.6 или выше, прежде чем продолжить. Это загрузит 300 МБ, поэтому это может занять некоторое время.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
# yum install mapr-drillLoaded plugins: fastestmirror, securitySetting up Install ProcessLoading mirror speeds from cached hostfile * base: mirror.vorboss.net * epel: www.mirrorservice.org * extras: mirror.vorboss.net * updates: mirror.vorboss.netResolving Dependencies--> Running transaction check---> Package mapr-drill.noarch 0:1.6.0.201603302146-1 will be installed--> Finished Dependency Resolution |
Получить новый сервер, чтобы забрать Apache Drill
|
1
2
3
4
5
6
7
8
9
|
# /opt/mapr/server/configure.sh -RConfiguring Hadoop-2.7.0 at /opt/mapr/hadoop/hadoop-2.7.0Done configuring HadoopNode setup configuration: cldb drill-bits fileserver hbasethrift hbinternal historyserver hivemetastore hiveserver2 hue nfs nodemanager oozie resourcemanager spark-historyserver webserver zookeeperLog can be found at: /opt/mapr/logs/configure.log setting CATALINA_OPTS="$CATALINA_OPTS -Xmx1024m"New Oozie WAR file with added 'Hadoop JARs, ExtJS library, JARs' at /opt/mapr/oozie/oozie-4.2.0/oozie-hadoop1.warNew Oozie WAR file with added 'Hadoop JARs, ExtJS library, JARs' at /opt/mapr/oozie/oozie-4.2.0/oozie-hadoop2.warINFO: Oozie is ready to be started-> |
Анализ таблиц JSON MapR-DB с использованием Apache Drill
Давайте используем графический интерфейс Apache Drill для просмотра таблиц, которые только что создало приложение OJAI. Apache Drill может управляться любым инструментом BI через соединения ODBC или JDBC. В следующем примере я использовал веб-интерфейс Drill, но вы можете легко использовать здесь все, что захотите.
Перейдите к порту 8047 в песочнице и вы увидите вариант запроса. В запросе введите следующее и нажмите отправить.
|
1
|
select * from dfs.`default`.`/apps/blog/articles` |
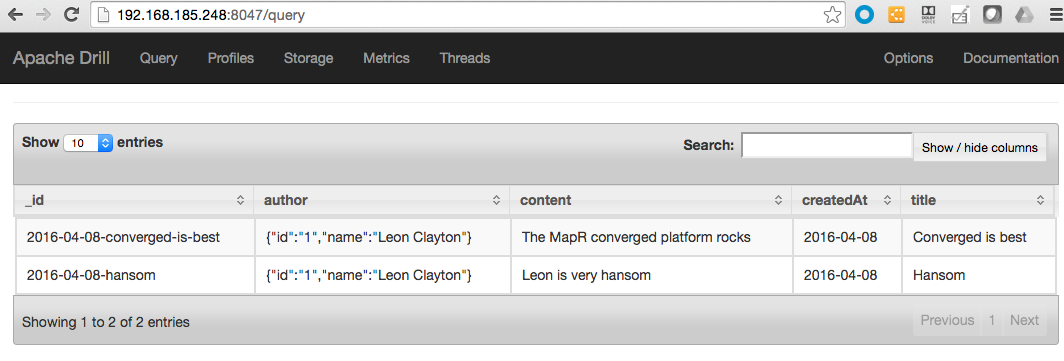
Вы увидите следующие результаты.
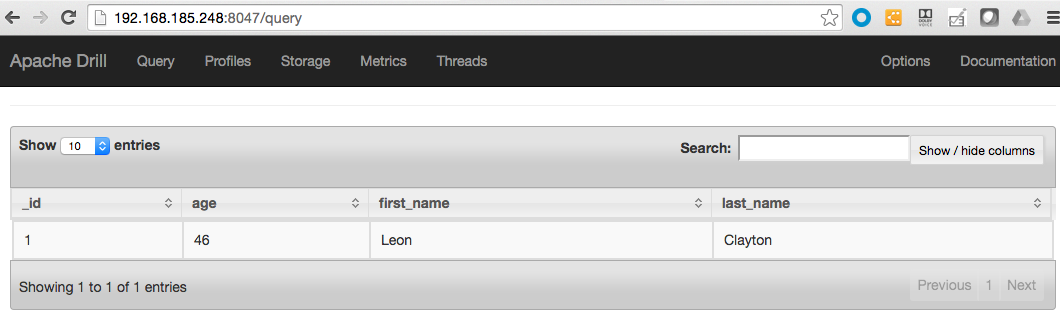
Вторым тестом является следующий запрос
|
1
|
select * from dfs.`default`.`/apps/blog/users` |
Здесь, в этой статье, мы изучили, как настроить приложение, работающее поверх таблиц JSON MapR-DB, и как запрашивать эти данные без необходимости перемещать или преобразовывать данные из исходного формата хранения. Поскольку JSON самоописывает себя, это позволяет другим легко понимать и запрашивать используемые структуры данных. Это очень мощная функция, которая может быть использована для оптимизации разработки приложений и аналитики. Я надеюсь, что вы нашли это полезным.
| Ссылка: | Как создавать приложения на базе данных документов NoSQL и выполнять аналитику на месте от нашего партнера по JCG Чейза Хули в блоге Mapr . |