обзор
Apache Hive является неотъемлемой частью экосистемы Hadoop. Hive можно определить как хранилище данных, такое как программное обеспечение, которое облегчает управление запросами и большими данными в HDFS (распределенная файловая система Hadoop). Следует помнить, что Hive не является программным обеспечением хранилища данных, а предоставляет некоторый механизм для управления данными в распределенной среде и выполнения запросов к ним с использованием языка, подобного SQL, называемого HiveQL или HIVE Query Language. Сценарии Hive могут быть определены как группа команд Hive, связанных вместе, чтобы сократить время выполнения. В этой статье я расскажу о скриптах Hive и их исполнении.
Вступление
HDFS или распределенная файловая система Hadoop обеспечивает масштабируемое и отказоустойчивое хранилище данных. HIVE предоставляет простой SQL-подобный язык запросов — HIVE QL. HIVE QL позволяет разработчикам традиционных карт уменьшить количество подключаемых модулей и преобразователей для более сложного анализа.
Ограничение ВИЧ
Задержка для запросов HIVE обычно очень высока из-за существенных накладных расходов при представлении на работу и планировании. Hive не предлагает запросы в реальном времени и обновления на уровне строк. Лучше всего использовать для анализа журнала.
Блоки данных HIVE
Данные улья подразделяются на следующие четыре категории:
- Базы данных: состоит из пространств имен, которые разделяют таблицы и другие блоки данных, чтобы избежать конфликтов имен.
- Таблицы: это однородные единицы данных, имеющие общую схему. Обычно используемым примером может быть таблица просмотра страницы, где каждая строка может иметь следующие столбцы:
- ID ПОЛЬЗОВАТЕЛЯ
- АЙПИ АДРЕС
- ПОСЛЕДНИЙ ДОСТУП
- URL страницы
В этом примере перечислены записи об использовании веб-сайта или приложения для отдельных пользователей.
- Разделы: Разделы определяют, как хранятся данные. Каждая таблица может иметь один или несколько разделов. Разделы также помогают пользователям эффективно идентифицировать строки, которые удовлетворяют определенным критериям выбора.
- Сегменты или кластеры. Данные в каждом разделе могут быть далее подразделены на сегменты или кластеры или блоки. Данные в приведенном выше примере могут быть кластеризованы на основе идентификатора пользователя, IP-адреса или столбца URL-адреса страницы.
Типы данных ВИЧ
Исходя из необходимости, HIVE поддерживает примитивные и сложные типы данных, как описано ниже:
- Примитивные типы:
- INTEGERS
- TINY INT 1 байтовое целое
- SMALL INT 2-байтовое целое
- INT 4-байтовое целое
- BIGINT 8-байтовое целое
- БУЛЕВЫ
- БУЛЕВСКАЯ ИСТИНА или ЛОЖЬ
- Номера с плавающей точкой
- FLOAT одинарной точности
- Двойная точность
- Тип STRING
- STRING Последовательность символов
- Сложные типы: Сложные типы могут быть построены с использованием примитивных типов данных и других составных типов с помощью:
- Структуры
- Карты или пары ключ-значение
- Массивы — индексированные списки
- INTEGERS
Сценарии HIVE
Как и любой другой язык сценариев, сценарии HIVE используются для коллективного выполнения набора команд HIVE. Сценарии HIVE помогают нам сократить время и усилия, затрачиваемые на написание и выполнение отдельных команд вручную. Сценарии HIVE поддерживаются в HIVE 0.10.0 или более поздних версиях HIVE. Чтобы написать и выполнить скрипт HIVE, нам нужно установить дистрибутив Cloudera для Hadoop CDH4.
Написание сценариев ВИЧ
Сначала откройте терминал в вашем дистрибутиве Cloudera CDH4 и дайте приведенную ниже команду для создания скрипта Hive.
|
1
|
gedit sample.sql |
Как и любой другой язык запросов, файл сценария Hive должен быть сохранен с расширением .sql . Это позволит выполнить команды. Теперь откройте файл в режиме редактирования и напишите команды Hive, которые будут выполняться с помощью этого сценария. В этом примере сценария мы будем последовательно выполнять следующие задачи (создавать, описывать, а затем загружать данные в таблицу. Затем извлекать данные из таблицы).
Создать таблицу ‘product’ в Hive
|
1
|
create table product_dtl ( product_id: int, product-name: string, product_price: float, product_category: string) rows format delimited fields terminated by ‘,’ ; |
Здесь {product_id, product-name, product_price, product_category} являются именами столбцов в таблице «product_dtl». « Поля, оканчивающиеся на«, », означают, что столбцы во входном файле разделены разделителем«, ». Вы также можете использовать другие разделители согласно вашему требованию. Например, мы можем рассмотреть записи во входном файле, разделенные символом новой строки (‘\ n’) .
Опишите таблицу
|
1
|
describe product_dtl; |
Загрузить данные в таблицу
Теперь давайте проверим часть загрузки данных. Создайте входной файл, содержащий записи, которые необходимо вставить в таблицу.
|
1
|
sudo gedit input.txt |
Теперь давайте создадим несколько записей во входном текстовом файле, как показано на рисунке ниже:
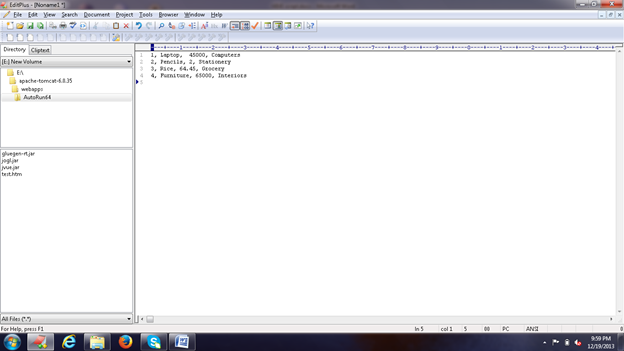
Рисунок 1: Входной файл.
Итак, наш входной файл будет выглядеть так:
|
1
2
3
4
5
6
7
|
1, Laptop, 45000, Computers2, Pencils, 2, Stationery3, Rice, 64.45, Grocery4, Furniture, 65000, Interiors |
Для загрузки данных из этого файла нам нужно выполнить следующую команду:
|
1
|
load data local inpath ‘/home/cloudera/input.txt’ into table product_dtl; |
Извлечение данных. Для извлечения данных мы используем простой оператор выбора, как показано ниже:
|
1
|
select * from product_dtl; |
Приведенная выше команда выполнит и извлечет все записи из таблицы «product» .
Сценарий будет выглядеть следующим образом:
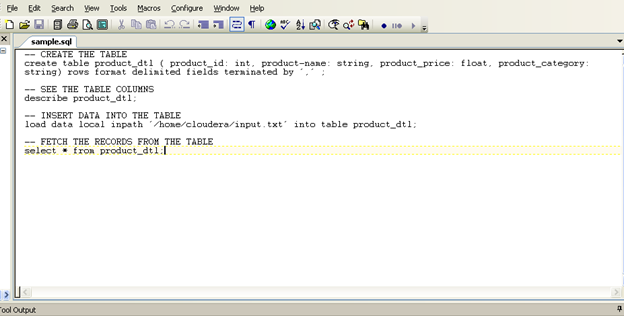
Рисунок 2: Пример файла SQL
Сохраните этот файл sample.sql и выполните следующую команду:
|
1
|
hive –f /home/cloudera/sample.sql |
При выполнении сценария укажите полный путь к местоположению сценария . Здесь образец сценария присутствует в текущем каталоге ; Я не указал полный путь к сценарию.
На следующем рисунке показано, что все команды были выполнены успешно.
Следующий вывод показывает, что таблица создана, и данные из нашего входного файла примера сохранены в базе данных.
| 1 | портативный компьютер | 45000 | компьютеры |
| 2 | карандаши | 2 | Канцтовары |
| 3 | Рис | 64,45 | бакалейные товары |
| 4 | Мебель | 65000 |
Резюме
Прежде чем завершить наше обсуждение, мы должны отметить следующие моменты
- Apache HIVE является неотъемлемой частью HDFS
- HIVE — это язык запросов, похожий на SQL
- Сценарий HIVE легко понять и реализовать
- Hive поддерживает как простые типы данных, так и сложные типы данных.
| Ссылка: | Как создать свой первый сценарий HIVE? от нашего партнера JCG Каушика Пала в блоге TechAlpine — мир технологий . |