Что мы собираемся построить
В этом посте мы рассмотрим, как создать автономный редактор с подсветкой синтаксиса для нашего языка. Функция подсветки синтаксиса будет основана на лексере ANTLR, который мы создали в первом посте . Код будет на Kotlin, однако он должен быть легко конвертируемым в Java. Редактор будет называться Kanvas .
Предыдущие посты
Этот пост является частью серии о том, как создать полезный язык и все вспомогательные инструменты.
Код
Код доступен на GitHub . Код, описанный в этом посте, связан с тегом syntax_highlighting
Настроить
Мы собираемся использовать Gradle в качестве нашей системы сборки.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
buildscript { ext.kotlin_version = '1.0.3' repositories { mavenCentral() maven { name 'JFrog OSS snapshot repo' } jcenter() } dependencies { classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlin_version" }} apply plugin: 'kotlin'apply plugin: 'application'apply plugin: 'java'apply plugin: 'idea'apply plugin: 'antlr' repositories { mavenLocal() mavenCentral() jcenter()} dependencies { antlr "org.antlr:antlr4:4.5.1" compile "org.antlr:antlr4-runtime:4.5.1" compile "org.jetbrains.kotlin:kotlin-stdlib:$kotlin_version" compile "org.jetbrains.kotlin:kotlin-reflect:$kotlin_version" compile 'com.fifesoft:rsyntaxtextarea:2.5.8' compile 'me.tomassetti:antlr-plus:0.1.1' testCompile "org.jetbrains.kotlin:kotlin-test:$kotlin_version" testCompile "org.jetbrains.kotlin:kotlin-test-junit:$kotlin_version"} mainClassName = "KanvasKt" generateGrammarSource { maxHeapSize = "64m" arguments += ['-package', 'me.tomassetti.lexers'] outputDirectory = new File("generated-src/antlr/main/me/tomassetti/lexers".toString())}compileJava.dependsOn generateGrammarSourcesourceSets { generated { java.srcDir 'generated-src/antlr/main/' }}compileJava.source sourceSets.generated.java, sourceSets.main.java clean { delete "generated-src"} idea { module { sourceDirs += file("generated-src/antlr/main") }} |
Это должно быть довольно просто. Несколько комментариев:
- наш редактор будет основан на компоненте RSyntaxTextArea, поэтому мы добавили соответствующую зависимость
- мы указываем версию Kotlin, которую мы используем. Вам не нужно устанавливать Kotlin в вашей системе: Gradle загрузит компилятор и будет использовать его на основе этой конфигурации
- мы используем ANTLR для генерации лексера из нашей грамматики лексера
- мы используем плагин идеи: запустив идею ./gradlew мы можем создать проект IDEA. Обратите внимание, что мы добавляем сгенерированный код в список исходных каталогов
- когда мы запускаем ./gradlew clean, мы также хотим удалить сгенерированный код
Изменения в лексере ANTLR
При использовании лексера для подачи парсера мы можем спокойно игнорировать некоторые токены. Например, мы можем игнорировать пробелы и комментарии. При использовании лексера для подсветки синтаксиса мы хотим захватить все возможные токены. Так что нам нужно немного адаптировать грамматику лексера, которую мы определили в первом посте:
- определение второго канала, куда мы будем отправлять токены, которые бесполезны для парсера, но необходимы для подсветки синтаксиса
- мы добавим новый реал с именем UNMATCHED, чтобы захватить всех персонажей, которые не принадлежат к правильным токенам. Это необходимо как потому, что недопустимые токены должны отображаться в редакторе, так и потому, что при вводе пользователь будет постоянно вводить недопустимые токены
Парсер будет рассматривать только токены в канале по умолчанию, в то время как мы будем использовать канал по умолчанию и канал EXTRA в нашей подсветке синтаксиса.
Это результирующая грамматика.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
lexer grammar SandyLexer; @lexer::members { private static final int EXTRA = 1;} // WhitespaceNEWLINE : '\r\n' | 'r' | '\n' ;WS : [\t ]+ -> channel(EXTRA) ; // KeywordsVAR : 'var' ; // LiteralsINTLIT : '0'|[1-9][0-9]* ;DECLIT : '0'|[1-9][0-9]* '.' [0-9]+ ; // OperatorsPLUS : '+' ;MINUS : '-' ;ASTERISK : '*' ;DIVISION : '/' ;ASSIGN : '=' ;LPAREN : '(' ;RPAREN : ')' ; // IdentifiersID : [_]*[a-z][A-Za-z0-9_]* ; UNMATCHED : . -> channel(EXTRA); |
Наш редактор
Наш редактор будет поддерживать подсветку синтаксиса для нескольких языков. На данный момент я реализовал поддержку Python и Sandy, простого языка, над которым мы работаем в этой серии постов. Для реализации подсветки синтаксиса для Python я начал с грамматики ANTLR для Python . Я начал с удаления правил парсера, оставив только правила лексера. Затем U сделал очень минимальные изменения, чтобы получить последний лексер в репозитории.
Для создания GUI нам понадобится довольно скучный код Swing. Нам нужно создать рамку с меню. Рамка будет содержать панель с вкладками. У нас будет одна вкладка на файл. В каждой вкладке у нас будет только один редактор, реализованный с использованием RSyntaxTextArea.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
fun createAndShowKanvasGUI() { UIManager.setLookAndFeel(UIManager.getSystemLookAndFeelClassName()) val xToolkit = Toolkit.getDefaultToolkit() val awtAppClassNameField = xToolkit.javaClass.getDeclaredField("awtAppClassName") awtAppClassNameField.isAccessible = true awtAppClassNameField.set(xToolkit, APP_TITLE) val frame = JFrame(APP_TITLE) frame.background = BACKGROUND_DARKER frame.contentPane.background = BACKGROUND_DARKER frame.defaultCloseOperation = JFrame.EXIT_ON_CLOSE val tabbedPane = MyTabbedPane() frame.contentPane.add(tabbedPane) val menuBar = JMenuBar() val fileMenu = JMenu("File") menuBar.add(fileMenu) val open = JMenuItem("Open") open.addActionListener { openCommand(tabbedPane) } fileMenu.add(open) val new = JMenuItem("New") new.addActionListener { addTab(tabbedPane, "<UNNAMED>", font) } fileMenu.add(new) val save = JMenuItem("Save") save.addActionListener { saveCommand(tabbedPane) } fileMenu.add(save) val saveAs = JMenuItem("Save as") saveAs.addActionListener { saveAsCommand(tabbedPane) } fileMenu.add(saveAs) val close = JMenuItem("Close") close.addActionListener { closeCommand(tabbedPane) } fileMenu.add(close) frame.jMenuBar = menuBar frame.pack() if (frame.width < 500) { frame.size = Dimension(500, 500) } frame.isVisible = true} fun main(args: Array<String>) { languageSupportRegistry.register("py", pythonLanguageSupport) languageSupportRegistry.register("sandy", sandyLanguageSupport) SwingUtilities.invokeLater { createAndShowKanvasGUI() }} |
Обратите внимание, что в основной функции мы регистрируем поддержку наших двух языков. В будущем мы могли бы представить подключаемую систему для поддержки большего количества языков.
Специфическая поддержка Sandy определена в объекте sandyLanguageSupport (для разработчиков на Java: объект — это просто одноэлементный экземпляр класса). Для поддержки требуется SyntaxScheme и AntlrLexerFactory .
SyntaxScheme просто возвращает стиль для каждого данного типа токена. Довольно легко, а?
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
object sandySyntaxScheme : SyntaxScheme(true) { override fun getStyle(index: Int): Style { val style = Style() val color = when (index) { SandyLexer.VAR -> Color.GREEN SandyLexer.ASSIGN -> Color.GREEN SandyLexer.ASTERISK, SandyLexer.DIVISION, SandyLexer.PLUS, SandyLexer.MINUS -> Color.WHITE SandyLexer.INTLIT, SandyLexer.DECLIT -> Color.BLUE SandyLexer.UNMATCHED -> Color.RED SandyLexer.ID -> Color.MAGENTA SandyLexer.LPAREN, SandyLexer.RPAREN -> Color.WHITE else -> null } if (color != null) { style.foreground = color } return style }} object sandyLanguageSupport : LanguageSupport { override val syntaxScheme: SyntaxScheme get() = sandySyntaxScheme override val antlrLexerFactory: AntlrLexerFactory get() = object : AntlrLexerFactory { override fun create(code: String): Lexer = SandyLexer(org.antlr.v4.runtime.ANTLRInputStream(code)) }} |
Теперь давайте посмотрим на AntlrLexerFactory . Эта фабрика просто создает ANTLR Lexer для определенного языка. Может использоваться вместе с AntlrTokenMaker . AntlrTokenMaker — это адаптер между ANTLR Lexer и TokenMaker, используемый RSyntaxTextArea для обработки текста. В основном TokenMakerBase вызывается для каждой строки файла отдельно при изменении строки. Поэтому мы просим наш ANTLR Lexer обработать только строку, и мы получаем полученные токены и создаем экземпляры экземпляров TokenImpl, которые ожидаются RSyntaxTextArea.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
interface AntlrLexerFactory { fun create(code: String) : Lexer} class AntlrTokenMaker(val antlrLexerFactory : AntlrLexerFactory) : TokenMakerBase() { fun toList(text: Segment, startOffset: Int, antlrTokens:List<org.antlr.v4.runtime.Token>) : Token?{ if (antlrTokens.isEmpty()) { return null } else { val at = antlrTokens[0] val t = TokenImpl(text, text.offset + at.startIndex, text.offset + at.startIndex + at.text.length - 1, startOffset + at.startIndex, at.type, 0) t.nextToken = toList(text, startOffset, antlrTokens.subList(1, antlrTokens.size)) return t } } override fun getTokenList(text: Segment?, initialTokenType: Int, startOffset: Int): Token { if (text == null) { throw IllegalArgumentException() } val lexer = antlrLexerFactory.create(text.toString()) val tokens = LinkedList<org.antlr.v4.runtime.Token>() while (!lexer._hitEOF) { tokens.add(lexer.nextToken()) } return toList(text, startOffset, tokens) as Token } } |
Это будет проблемой для токенов, охватывающих несколько строк. Для этого есть обходные пути, но пока давайте будем простыми и не будем это учитывать, учитывая, что у Сэнди нет токенов, охватывающих несколько строк.
Выводы
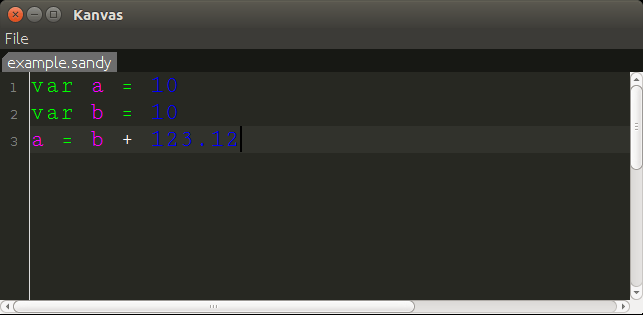
Конечно, этот редактор не является полной функцией. Однако я думаю, что интересно посмотреть, как редактор с подсветкой синтаксиса может быть построен с помощью пары сотен строк довольно простого кода Kotlin.
В следующих постах мы увидим, как обогатить этот редактор такими вещами, как автозаполнение.