Это 3-й пост моего эксперимента Go lang. Если вы хотите прочитать предыдущие сообщения, перейдите по ссылке:
Структуры — это классные типы. Это позволяет создавать пользовательский тип.
Структура базовая
Структура может быть объявлена так
|
1
2
3
4
|
type person struct { firstName string lastName string} |
это объявляет структуру с 2 полями.
Переменные структуры могут быть объявлены следующим образом:
вар р1 человек
Конструкция var инициализирует значение p1 нулевым значением, поэтому оба строковых поля установлены на «».
Конструкция DOT (.) Используется для доступа к полю.
Как определить структурные переменные.
Пара способов, с помощью которых можно создать переменную.
|
1
2
3
4
5
6
7
8
|
var p1 person // Zero value var p2 = person{} //Zero value p3 := person{firstName: "James", lastName: "Bond"} //Proper initialization p4 := person{firstName: "James"} //Partial initialization p5 := new(person) // Using new operator , this returns pointer p5.firstName = "James" p5.lastName = "Bond" |
Сравнение структур
Структуру того же типа можно сравнить с помощью оператора «==»
|
1
2
3
4
5
6
7
8
9
|
p1 := person{firstName: "James", lastName: "Bond"}p2 := person{firstName: "James", lastName: "Bond"}if p1 == p2 { fmt.Println("Same person found!!!!", p1) } else { fmt.Println("They are different", p1, p2) } |
это показывает силу чистого значения, для сравнения не требуется типа равенства / хэш-кода. Язык имеет поддержку первого класса для сравнения по значению.
Структурное преобразование
Go lang не имеет кастинга. Он поддерживает преобразование и применим к любым типам, а не только к struct.
При преобразовании сохраните ссылку на исходный объект и поместите структуру / макет целевого объекта поверх него, чтобы при преобразовании любые изменения, сделанные в исходном объекте после преобразования, были видны целевому объекту.
Это хорошо для уменьшения накладных расходов памяти, но в целях безопасности это может вызвать большие проблемы, поскольку значения могут волшебным образом меняться от исходного объекта.
На другом конце преобразования копирует исходное значение, поэтому после преобразования и источник, и цель не имеют ссылки. Изменение одного не влияет на другое. Это хорошо для безопасности типов и легко рассуждать о коде.
Давайте рассмотрим пример преобразования структуры.
|
1
2
3
4
5
6
7
8
9
|
type person struct { firstName string lastName string}type anotherperson struct { firstName string lastName string} |
Оба вышеперечисленных имеют одинаковую структуру, но эти два нельзя назначить друг другу без преобразования.
|
1
2
3
4
5
6
|
p1 := person{firstName: "James", lastName: "Bond"}anotherp1 := anotherperson{firstName: "James", lastName: "Bond"}p1 = anotherp1 //This is compile time errorp1 = person(anotherp1)//This is allowed |
Компилятор очень умен, чтобы выяснить, что эти два типа совместимы и преобразование разрешено.
Теперь, если вы идете и вносите изменения в структуру другого человека, например, удаляете поле / новое поле / меняете порядок, тогда это становится несовместимым, и компилятор останавливает это!
Когда он разрешает преобразование, он выделяет новую память для целевой переменной и копирует значение.
Например,
|
1
2
|
p1 = person(anotherp1)anotherp1.lastName = "Lee" // Will have not effect on p1 |
Как распределяются структуры
Так как это составной тип и понимание структуры памяти структуры очень полезно знать, к какому типу накладных расходов это относится.
Текущий процессор сделает некоторые крутые вещи для быстрого и безопасного чтения / записи.
Выделение памяти будет выровнено по размеру слова базовой платформы (32-битной или 64-битной), а также будет выровнено по размеру типа, например, 4-байтовое значение будет выровнено по 4-байтовому адресу.
Выравнивание очень важно для скорости и правильности.
Давайте рассмотрим пример, чтобы понять это, в 64-битной платформе размер слова составляет 64 бита или 8 байт, поэтому для чтения 1 слова потребуется 1 инструкция.
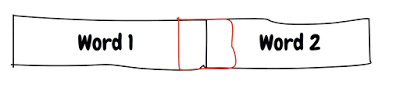
Значение, показанное красным, составляет 2 байта, и если значение, показанное красным, выделено в 2 слова (т.е. на границе слова), то для чтения / записи значения потребуется несколько операций, а для записи может потребоваться какая-то синхронизация.
Поскольку значение составляет всего 2 байта, оно может легко поместиться в одно слово, поэтому компилятор попытается выделить это в одном слове:
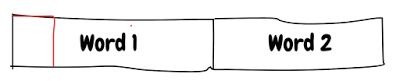
Выше распределение оптимизировано для чтения / записи. Структура распределения работает по тому же принципу.
Теперь давайте возьмем пример структуры и посмотрим, какой будет структура памяти:
|
1
2
3
4
5
6
|
type layouttest struct { b byte v int32 f float64 v2 int32} |
Макет «layoutouttest» будет выглядеть примерно так:
[1 XX 1 1 1 1 X] [1 1 1 1 XXXX] [1 1 1 1 1 1 1 1] [1 1 1 1 XXXX]
Х — для заполнения.
Чтобы разместить эту структуру и добавить выравнивание по типу данных, потребовалось 4 слова.
Если мы вычислим размер структуры (1 + 4 + 4 + 8 = 17), тогда она должна соответствовать значению в 3 словах (8 * 3 = 24), но потребовалось 4 слова (8 * 4 = 32). Может показаться, что 8 байтов потрачены впустую.
Go дает разработчику полный контроль над расположением памяти. Гораздо более компактная структура может быть создана, чтобы получить до 3-х слов.
|
1
2
3
4
5
6
|
type compactlyouttest struct { f float64 v int32 v2 int32 b byte} |
Выше структуры переупорядочено поле в порядке убывания по размеру, который требуется, и это помогает в переходе ниже макета памяти
[1 1 1 1 1 1 1 1] [1 1 1 1 1 1 1 1] [1 XXXXXXX]
При таком расположении меньше места теряется при заполнении, и вы можете испытать желание использовать компактное представление.
Вы не должны делать это по нескольким причинам
— Это нарушает читабельность, потому что связанные поля перемещаются повсюду.
— Память не может быть проблемой, так что это может быть просто из-за оптимизации.
— Процессор очень умный, значения читаются в кешировании, а не в слове, поэтому процессор будет читать несколько слов, и вы никогда не увидите замедления чтения. О том, как работает строка кэша, вы можете прочитать в статье cpu-cache-access-pattern .
— Чрезмерная оптимизация может привести к проблеме ложного совместного использования, прочитайте параллельное счетчик без обмена, чтобы увидеть влияние ложного совместного использования в многопоточном коде.
Так что профилируйте приложение, прежде чем делать какие-либо оптимизации
Go имеет встроенные пакеты для получения деталей выравнивания памяти и другой статической информации типов.
Ниже код дает много деталей о расположении памяти
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
var x layouttestvar y compactyouttest fmt.Printf("Int alignment %v \n", unsafe.Alignof(10)) fmt.Printf("Int8 aligment %v \n", unsafe.Alignof(int8(10))) fmt.Printf("Int16 aligment %v \n", unsafe.Alignof(int16(10))) fmt.Printf("Layoutest aligment %v ans size is %v \n", unsafe.Alignof(x), unsafe.Sizeof(x)) fmt.Printf("Compactlayouttest aligment %v and size is %v \n", unsafe.Alignof(y), unsafe.Sizeof(y)) fmt.Printf("Type %v has %v fields and takes %v bytes \n", reflect.TypeOf(x).Name(), reflect.TypeOf(x).NumField(), reflect.TypeOf(x).Size()) |
Пакет Unsafe &lect дает много внутренних деталей и выглядит так, как будто идея пришла из Java.
Код, используемый в этом блоге, доступен на @ 001-struct github.
|
Смотрите оригинальную статью здесь: Как работает Go lang struct Мнения, высказанные участниками Java Code Geeks, являются их собственными. |