Задержка определяется как
временной интервал между стимуляцией и ответом
и является ценностью, которая имеет значение во многих компьютерных системах (финансовые системы, игры, веб-сайты и т. д.). Поэтому мы — как компьютерные инженеры — хотим указать некоторые верхние границы / наихудшие сценарии для систем, которые мы строим. Как мы можем это сделать? Дни циклов подсчета для инструкций по сборке давно прошли (если вы не работаете со встроенными системами) — нужно учитывать слишком много дополнительных факторов (операционная система — в основном планировщик задач, другие запущенные процессы, JIT, GC и т. Д.). ). Остальной альтернативой является проведение эмпирического (практического) тестирования.
Используйте процентили
Поэтому мы извлекаем JMeter , настраиваем нагрузочный тест, принимаем среднее (среднее) значение 土 3 x стандартное отклонение и с гордостью заявляем, что 99,73% пользователей будут испытывать задержку, которая находится в этом интервале. Мы особенно гордимся тем, что (а) мы рассмотрели реалистичный набор вызовов (URL-адреса, если мы тестируем веб-сайт) и (б) мы разрешили прогрев JIT.
Но мы все еще очень не правы! (что может быть грустно, если наша компания пишет SLA на основе наших номеров — мы можем обанкротить компанию в одиночку!)
Давайте посмотрим, где проблема и как мы можем ее исправить, прежде чем нанести ущерб. Рассмотрите набор данных, изображенный ниже (вы можете получить фактические значения здесь, чтобы сделать свои собственные вычисления).
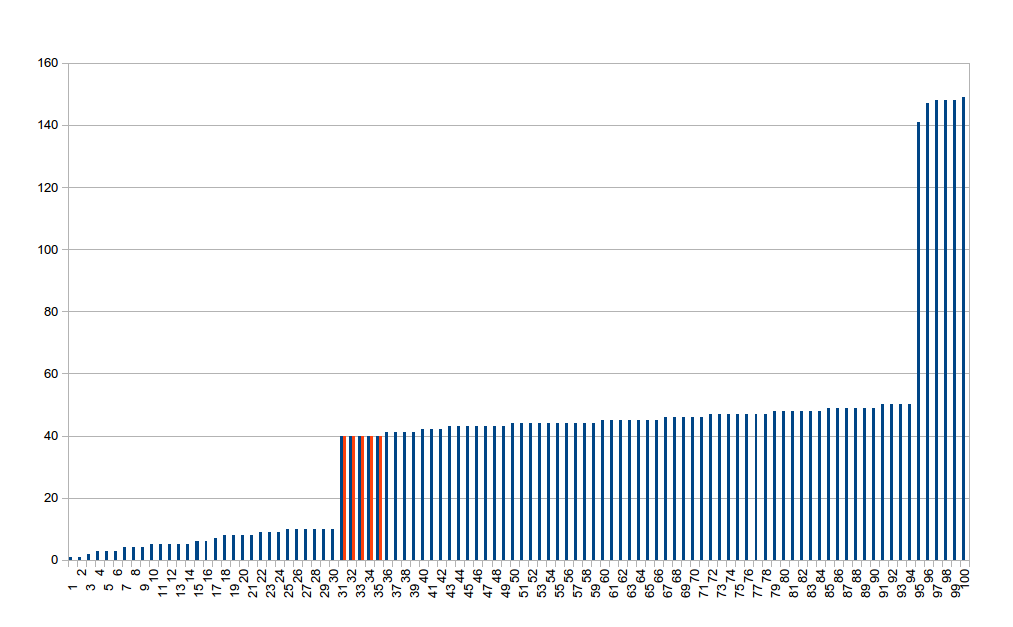
Для простоты в этом примере используется ровно 100 значений. Допустим, они представляют задержку получения определенного URL. Вы можете сразу сказать, что значения можно сгруппировать по трем различным категориям: очень маленькие (возможно, данные уже были в кеше?), Средние (это то, что увидит большинство пользователей) и плохие (вероятно, есть некоторые угловые случаи) , Это типично для средней и большой сложности (то есть «реальной жизни»), состоящей из множества движущихся частей, и называется мультимодальным распределением. Подробнее об этом в ближайшее время.
Если мы быстро перенесем эти значения в LibreOffice Calc и выполним подсчет чисел, мы придем к выводу, что среднее (среднее) значений равно 40, и согласно правилу шести сигм 99,73% пользователей должны испытывать задержки меньше, чем 137. Если вы внимательно посмотрите на график, вы увидите, что среднее значение (отмечено красным) немного левее среднего. Вы также можете выполнить простой расчет (поскольку представлено ровно 100 значений) и увидеть, что максимальное значение в 99-м процентиле равно 148, а не 137. Теперь это может показаться не большой разницей, но это может быть разница между прибылью и банкротство (если вы написали SLA на основе этого значения, например).
Где мы ошиблись? Давайте снова внимательно посмотрим на правило трех сигм (выделение добавлено):
почти все значения лежат в пределах трех стандартных отклонений от среднего в нормальном распределении .
Наша проблема в том, что у нас нет нормального распределения. Возможно, у нас есть мультимодальное распределение (как упоминалось ранее), но для безопасности мы должны использовать способы интерпретации результатов, которые не зависят от характера распределения.
Из этого примера мы можем извлечь пару рекомендаций:
- Убедитесь, что ваш тестовый фреймворк / генератор нагрузки / тест не является узким местом — запустите его с «нулевой конечной точкой» (той, которая ничего не делает) и убедитесь, что вы можете получить на порядок лучшие числа
- Примите во внимание такие вещи, как JITing (периоды прогрева) и GC, если вы тестируете систему на основе JVM (или другие системы, основанные на тех же принципах — .NET, luajit и т. Д.).
- Используйте процентили . Сказать что-то вроде «среднее (50-й процентиль) время отклика нашей системы…», «латентность 99,99-го процентиля…», «максимальная латентность (100-й процентиль)…» — все в порядке
- Не рассчитывайте среднее (среднее). Не используйте стандартное отклонение. Фактически, если вы видите это значение в отчете об испытаниях, вы можете предположить, что люди, составляющие отчет (а), не знают, о чем они говорят, или (б) намеренно пытаются ввести вас в заблуждение (я бы поставил на первое, но это только мой оптимизм говорит).
- Удостоверьтесь, что каждый запрос меньше, чем интервал выборки, или используйте лучший инструмент для сравнения (я не знаю ни одного, который подходит для этого) или постобработайте данные с помощью библиотеки Gil HdrHistogram, которая содержит встроенные средства для учета скоординированного пропуска.
Ищите скоординированного упущения
Пропуск координат (фраза, придуманная Джилом Тене из Azul Fame) — это проблема, которая может возникнуть, если тестовый цикл выглядит примерно так:
|
1
2
3
4
5
6
|
start: t = time() do_request() record_time(time() - t) wait_until_next_second() jump start |
То есть мы пытаемся делать один запрос каждую секунду (возможно, каждые 100 мс было бы более реалистичным, но точка зрения остается в силе). Многие тестовые системы (включая JMeter и YCSB) имеют такие внутренние циклы.
Мы запускаем тест и (изучая из предыдущего обсуждения) отчет: 85% запросов будут обработаны менее чем за 0,5 секунды, если есть 1 запрос в секунду. И мы все еще можем ошибаться! Давайте посмотрим на диаграмму ниже, чтобы понять почему:
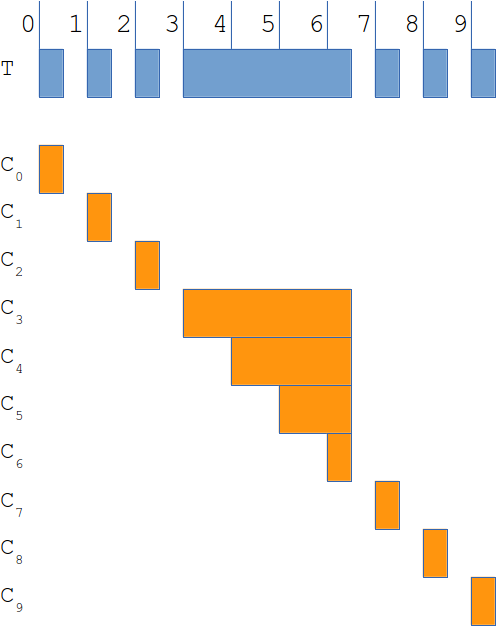
На первой строке у нас есть тестовый прогон (горизонтальная ось — время). Допустим, что между секундами 3 и 6 система (и, следовательно, все запросы к ней) блокируются (возможно, у нас длинная пауза GC). Если вы вычислите 85-й процентиль, вы получите 0,5 (отсюда и требование в предыдущем абзаце). Однако ниже вы можете увидеть 10 независимых клиентов, каждый из которых выполняет запрос в разную секунду (поэтому мы выполняем наши критерии одного запроса в секунду). Но если мы сократим числа, мы увидим, что фактический 85-й процентиль в этом случае равен 1,5 (в три раза хуже, чем первоначальный расчет).
Где мы ошиблись? Проблема заключается в том, что тестовый цикл и тестируемая система работали вместе («скоординировано» — отсюда и название), чтобы скрыть (опустить) дополнительные запросы, которые происходят во время блокировки сервера. Это приводит к недооценке задержек (как показано в примере).
| Ссылка: | Как (НЕ) измерять задержку от нашего партнера JCG Аттилы Михали Балаза в блоге Java Advent Calendar . |