PredictionIO — это сервер машинного обучения с открытым исходным кодом, а также недавнее дополнение к семейству Apache. PredictionIO позволяет:
- Быстрое создание и развертывание движка в виде веб-службы на производстве с помощью настраиваемых шаблонов.
- Отвечать на динамические запросы в режиме реального времени после развертывания в качестве веб-службы
- Систематически оценивать и настраивать несколько вариантов двигателей
- Унификация данных с нескольких платформ в пакетном режиме или в режиме реального времени для комплексной аналитической аналитики
- Ускорение моделирования машинного обучения с помощью систематических процессов и заранее подготовленных мер оценки
- Поддержка машинного обучения и библиотек обработки данных, таких как Spark MLlib и OpenNLP
- Реализуйте свои собственные модели машинного обучения и без проблем включите их в свой движок
- Упростите управление инфраструктурой данных
PredictionIO поставляется с HBase и используется в качестве хранилища данных о событиях для управления инфраструктурой данных для моделей машинного обучения. В этой задаче интеграции мы будем использовать MapR-DB на платформе конвергентных данных MapR для замены HBase. MapR-DB реализована непосредственно в файловой системе MapR. Получающиеся преимущества состоят в том, что MapR-DB не имеет промежуточных слоев при выполнении операций с данными. MapR-DB работает в рамках процесса MapR-FS и читает / записывает на диск напрямую. Принимая во внимание, что HBase в основном работает на HDFS, с которой ему необходимо обмениваться данными через JVM и HDFS, а также взаимодействует с файловой системой Linux для выполнения операций чтения / записи. Дополнительные преимущества можно найти здесь в документации MapR .
В PredictionIO необходимо изменить несколько строк кода для работы с MapR-DB. Я создал разветвленную версию, которая работает с MapR 5.1 и Spark 1.6.1. Ссылка на Github здесь .
подготовка
Обязательным условием является наличие кластера MapR 5.1 с установленным Spark 1.6.1 и сервером ElasticSearch. Мы используем MapR-DB (1.1.1) для хранения данных о событиях, ElasticSearch для хранения метаданных и MapR-FS для хранения данных модели. В MapR-DB отсутствует концепция пространства имен HBase, поэтому иерархия таблиц основана на иерархии файловой системы MapR. Но MapR поддерживает отображение пространства имен для HBase (подробная ссылка здесь ). Обратите внимание, что файл core-site.xml находится по адресу «/opt/mapr/hadoop/hadoop-2.7.0/etc/hadoop/» начиная с MapR 5.1, и вам следует изменить файл core-site.xml и добавить конфигурацию, как показано ниже. Также, пожалуйста, создайте выделенный том MapR по выбранному вами пути.
|
1
2
3
4
|
<property> <name>hbase.table.namespace.mappings</name> <value>*:/hbase_tables</value> </property> |
Затем мы загружаем и компилируем PredictionIO:
|
1
2
3
4
|
git clone https://github.com/mengdong/mapr-predictionio.gitcd mapr-predictionio git checkout mapr./make-distribution.sh |
После компиляции должен быть создан файл «PredictionIO-0.10.0-SNAPSHOT.tar.gz». Скопируйте его во временный путь и извлеките его туда, а затем скопируйте обратно файл jar «pio-assembly-0.10.0-SNAPSHOT.jar» в каталог «lib» в папке «mapr -pretionio».
Поскольку мы хотим работать с MapR 5.1, мы хотим убедиться, что включен правильный путь к классам. Я изменил «bin / pio-class» в своем репо, чтобы включить необходимые изменения, но ваша среда может отличаться, поэтому, пожалуйста, отредактируйте соответственно. «Conf / pio-env.sh» также необходимо создать. У меня есть шаблон для справки:
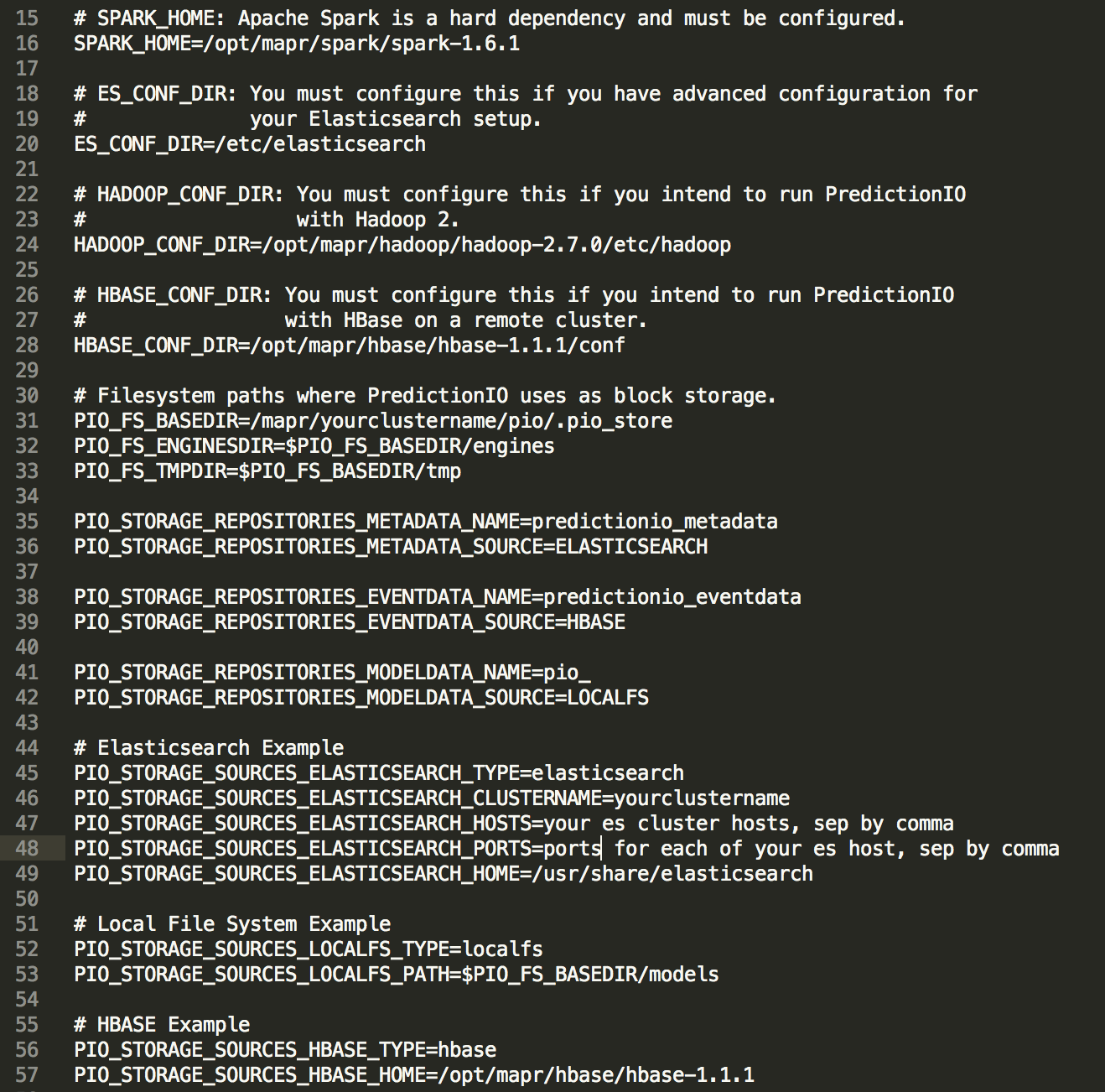
На данный момент, подготовка почти завершена. Мы должны добавить папку «bin» вашего PredictionIO к вашему пути. Просто запустите «pio status», чтобы узнать, успешна ли ваша настройка. Если все работает, вы должны увидеть следующий журнал:
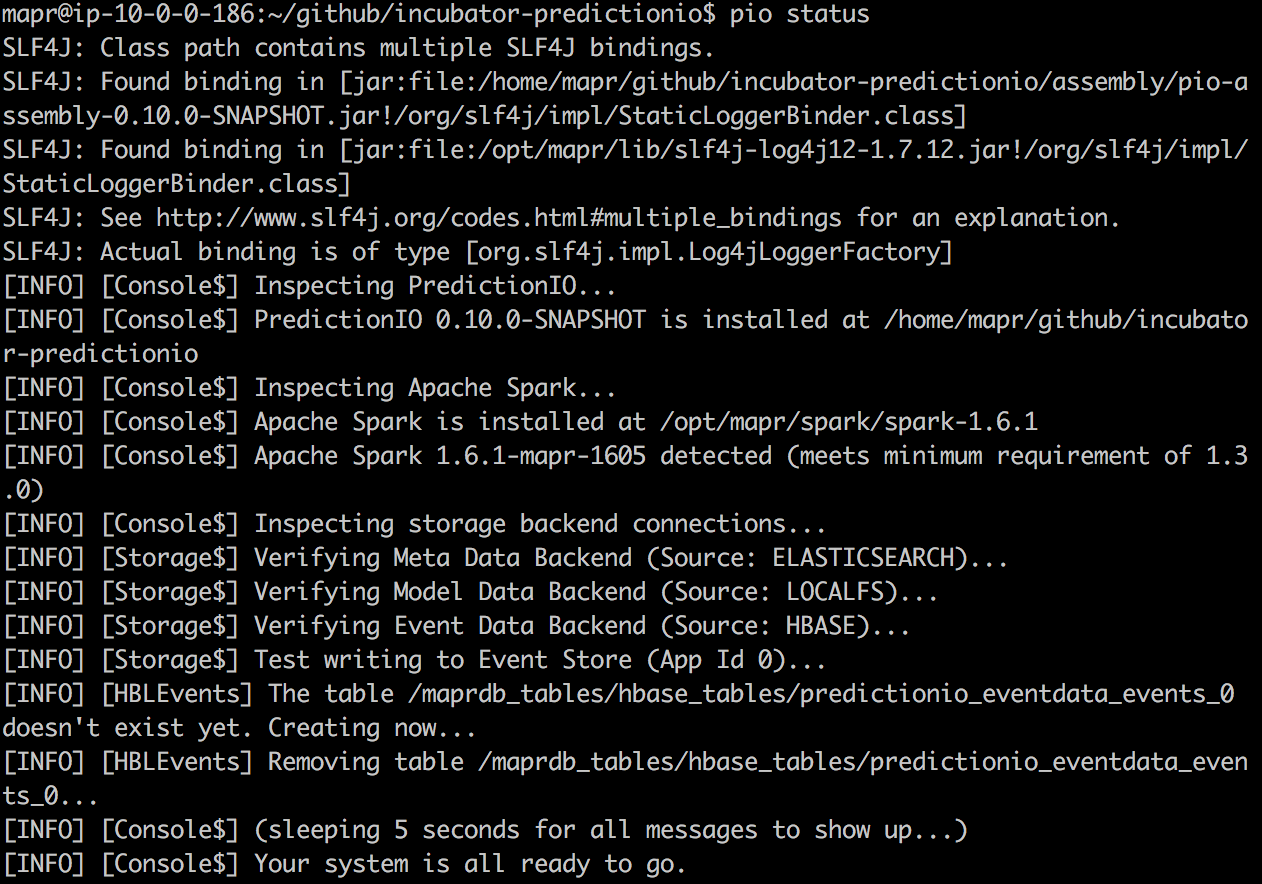
Это означает, что он готов запустить «bin / pio-start-all», чтобы запустить консоль PredictionIO. Если он работает успешно, вы можете просто запустить «jps» и вы должны увидеть «console» jvm.
Развернуть машинное обучение
Отличной особенностью PredictionIO является простота разработки / обучения / развертывания приложения для машинного обучения, а также обновление модели и управление моделью. Для демонстрации доступно множество шаблонов; например: http://predictionio.incubator.apache.org/demo/textclassification/ .
Однако из-за недавнего перехода на семейство Apache ссылки не работают. Я создал раздвоенный репо, чтобы заставить работать несколько шаблонов. Один https://github.com/mengdong/template-scala-parallel-classification предназначен для http://predictionio.incubator.apache.org/demo/textclassification/ , который представляет собой логистическую регрессию, обученную выполнять бинарную классификацию спама в электронной почте.
Еще один https://github.com/mengdong/template-scala-parallel-s Similarproduct предназначен для http://predictionio.incubator.apache.org/templates/similproduct/quickstart/ , который является механизмом рекомендаций для пользователей и элементов. Вы можете либо клонировать мое разветвленное репо вместо использования «pio template get», либо вы можете скопировать папку «src» и «build.sbt» в папку «pio template get». Пожалуйста, измените имя пакета в вашем коде Scala, чтобы оно соответствовало вашему вводу во время получения шаблона, если вы делаете копию.
Все остальное работает в руководстве по предсказанию. Я считаю, что ссылки будут исправлены очень скоро. Просто следуйте инструкциям, чтобы зарегистрировать свой движок в приложении PredictionIO. Затем обучите модель машинного обучения, а затем разверните модель и используйте ее через службу REST или SDK (в настоящее время поддерживает python / java / php / ruby). Вы также можете использовать Spark и PredictionIO для разработки собственной модели использования MapR-DB в качестве бэкэнда. ![]()
| Ссылка: | Как интегрировать Apache PredictionIO с MapR для практического машинного обучения от нашего партнера JCG Донга Менга в блоге Mapr . |