Разве мы все не задавались вопросом:
Как я могу это сделать? У меня есть эти данные в Excel, и я хочу сгруппировать / отсортировать / назначить / объединить …
Хотя вы, возможно, могли бы запустить скрипт Visual Basic, выполняющий эту работу, или экспортировать данные в Java или любой другой процедурный язык по вашему выбору, почему бы просто не использовать SQL?
Вариант использования: Подсчет соседних цветов в хореографии стадиона
Для многих из вас это может не быть повседневным вариантом использования, но для наших друзей из офиса в FanPictor это так. Они создают программное обеспечение для рисования фанатов хореографии прямо на стадионе. Вот пример использования на высоком уровне:
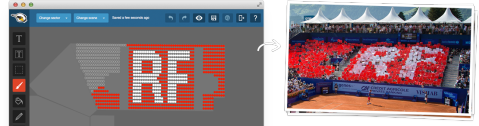
Нарисуйте фанатскую хореографию с FanPictor. В этом случае дань уважения Роджеру Федереру
Сразу понятно, что делает эта забавная программа, верно?
- Вы отправляете предложение по хореографии
- Организаторы мероприятия выбирают лучшую подачу
- Организаторы мероприятия экспортируют хореографию в файл Excel
- Файл Excel подается в типографию, печатая красные / красные, красные / белые, белые / красные, белые / белые панели (или любые другие цвета)
- Помощники мероприятия распределяют цветные панели на соответствующие места
- Фанаты все взволнованы
Посмотрите на электронную таблицу Excel
Вот как выглядит таблица Excel:
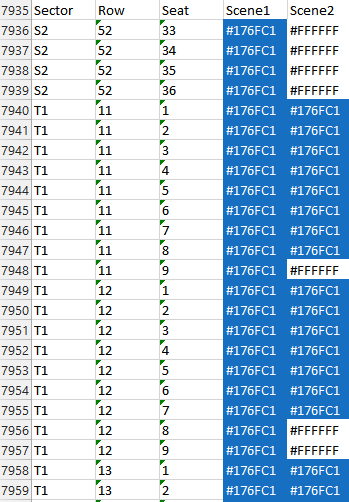
Распечатать инструкцию магазина
Теперь раздавать эти панели — глупая, повторяющаяся работа. Исходя из опыта, наши друзья в FanPictor хотели иметь что-то вроде этого, вместо этого:
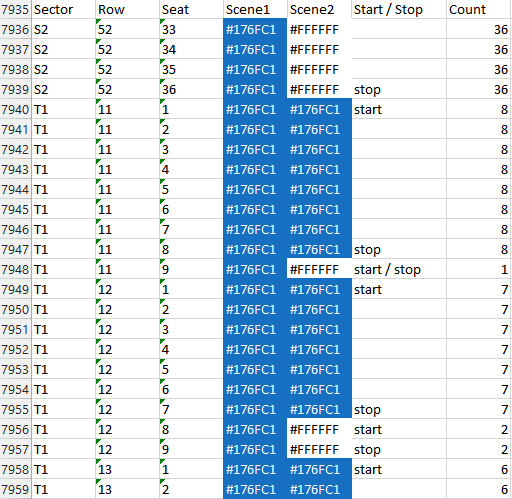
Распечатать инструкцию магазина для чайников
Обратите внимание, что есть инструкции, связанные с каждой панелью, чтобы указать:
- … Начинается или заканчивается последовательный ряд идентичных панелей
- … Сколько одинаковых панелей в таком ряду
«Последовательный» означает, что внутри сектора и ряда стадиона есть смежные места с одинаковым (Scene1, Scene2) кортежем.
Как мы решаем эту проблему?
Конечно, мы решаем эту проблему с помощью SQL — и приличной базы данных, которая поддерживает оконные функции , например PostgreSQL , или любую коммерческую базу данных по вашему выбору! ( вы не найдете такого рода функции в MySQL ).
Вот запрос:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
with dataas ( select d.*, row(sektor, row, scene1, scene2) block from d)select sektor, row, seat, scene1, scene2, case when lag (block) over(o) is distinct from block and lead(block) over(o) is distinct from block then 'start / stop' when lag (block) over(o) is distinct from block then 'start' when lead(block) over(o) is distinct from block then 'stop' else '' end start_stop, count(*) over( partition by sektor, row, scene1, scene2 ) cntfrom datawindow o as ( order by sektor, row, seat)order by sektor, row, seat; |
Это оно! Не слишком сложно, не так ли?
Давайте рассмотрим пару деталей. Мы используем довольно много классных концепций SQL / PostgreSQL, которые заслуживают пояснения:
Конструктор значений строк
Конструктор значений ROW() — это очень мощная функция, которую можно использовать для объединения нескольких столбцов (или строк) в один тип ROW / RECORD :
|
1
|
row(sektor, row, scene1, scene2) block |
Этот тип затем можно использовать для сравнения значений строк , что позволяет сэкономить много времени при сравнении столбцов за столбцами.
Предикат DISTINCT
|
1
|
lag (block) over(o) is distinct from block |
Результат описанной выше оконной функции сравнивается с ранее созданным ROW с помощью предиката DISTINCT , который является отличным способом сравнения «нулевых» в SQL. Помните, что SQL NULL — одни из самых сложных вещей в SQL .
Оконные функции
Оконные функции — очень крутая концепция. Без какого-либо предложения GROUP BY вы можете вычислять агрегатные функции, оконные функции, функции ранжирования и т. Д. В контексте текущей строки, пока вы проецируете предложение SELECT . Например:
|
1
2
3
|
count(*) over( partition by sektor, row, scene1, scene2) cnt |
Приведенная выше оконная функция считает все строки, которые находятся в том же разделе («группе»), что и текущая строка, с учетом критериев разделения. Другими словами, все места, которые имеют одинаковую (scene1, scene2) окраску и расположены в одном и том же (sector, row) .
Другими оконными функциями являются lead и lag , которые возвращают значение из предыдущей или последующей строки при заданном порядке:
|
1
2
3
4
5
6
|
lag (block) over(o),lead(block) over(o)-- ...window o as ( order by sektor, row, seat) |
Обратите внимание также на использование стандартного предложения SQL WINDOW , которое поддерживается только PostgreSQL и Sybase SQL Anywhere.
В вышеприведенном фрагменте lag() возвращает значение block предыдущей строки с учетом порядка o , тогда как lead() возвращает значение следующей строки для block — или NULL , в случае чего мы рады, что использовали DISTINCT. предикат, раньше.
Обратите внимание, что вы также можете дополнительно указать дополнительный числовой параметр, чтобы указать, что вы хотите получить доступ ко второму, третьему, пятому или восьмому ряду назад или вперед.
SQL ваш самый мощный и недооцененный инструмент
В Data Geekery мы всегда говорим, что
SQL — это устройство, тайна которого превосходит только его мощь
Если вы следили за нашим блогом, вы, возможно, заметили, что мы пытаемся пропагандировать SQL как замечательного первоклассного гражданина для разработчиков Java. Большинство вышеперечисленных функций поддерживаются jOOQ и переводятся на ваш родной диалект SQL, если они недоступны.
Итак, если вы еще этого не сделали, послушайте Питера Копфлера, который был так взволнован после наших недавних выступлений в jOOQ / SQL в Вене, что теперь он все изучает стандарты и использует PostgreSQL:
дальнейшее чтение
Был SQL перед оконными функциями и SQL после оконных функций
| Ссылка: | Как я могу это сделать? — С SQL конечно! от нашего партнера JCG Лукаса Эдера в блоге JAVA, SQL и JOOQ . |