Некоторые базы данных достаточно MEDIAN() для реализации агрегатной функции MEDIAN() . Помните, что MEDIAN() слегка отличается от (и часто более полезен, чем) MEAN() или AVG() (в среднем).
В то время как среднее значение рассчитывается как SUM(exp) / COUNT(exp) , MEDIAN() сообщает, что 50% всех значений в выборке выше, чем MEDIAN() тогда как остальные 50% набора ниже, чем MEDIAN() .
Итак, другими словами, если вы берете следующий запрос:
|
01
02
03
04
05
06
07
08
09
10
|
WITH t(value) AS ( SELECT 1 FROM DUAL UNION ALL SELECT 2 FROM DUAL UNION ALL SELECT 3 FROM DUAL)SELECT avg(value), median(value)FROM t; |
… Тогда и среднее, и среднее значение одинаковы:
|
1
2
|
avg median2 2 |
Но если вы сильно искажаете свои данные следующим образом:
|
01
02
03
04
05
06
07
08
09
10
|
WITH t(value) AS ( SELECT 1 FROM DUAL UNION ALL SELECT 2 FROM DUAL UNION ALL SELECT 100 FROM DUAL)SELECT avg(value), median(value)FROM t; |
Тогда ваше среднее значение также будет искажено, в то время как медиана все равно будет указывать, где находится большинство значений в вашей выборке.
|
1
2
|
avg median34.333 2 |
Приведенный выше пример, конечно, статистически незначим, но вы можете легко увидеть, что эффект может быть существенным и значительным, если у вас есть больше данных:
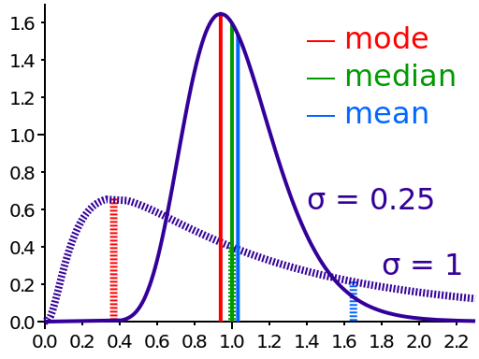
Изображение лицензии CC-BY-SA 3.0. Загружено в Википедию Cmglee
Эффект асимметрии очень важен в статистике, и для того, чтобы сделать что-либо интересное, использование процентилей чаще всего более полезно, чем использование средних значений. Возьмем, к примеру, средний доход по сравнению со средним доходом в стране. В то время как средний доход в США (и во многих других странах) неуклонно растет, средний доход за последнее десятилетие снизился . Это связано с тем, что богатство все больше и больше склоняется к сверхбогатым.
Этот блог не о политике, а о Java и SQL, поэтому давайте вернемся к подсчету фактов.
Использование прецентилей в SQL
Как мы уже видели, MEDIAN() делит выборку на две группы одинакового размера и принимает значение «между» этими двумя группами. Это конкретное значение также называется 50-й процентиль, потому что 50% всех значений в выборке ниже, чем MEDIAN() . Таким образом, мы можем установить:
-
MIN(exp): 0-процентиль -
MEDIAN(exp): 50-й процентиль -
MAX(exp): сотый процентиль
Все вышеперечисленное является частным случаем процентилей, и хотя MIN() и MAX() поддерживаются во всех базах данных SQL (и стандарте SQL), MEDIAN() не входит в стандарт SQL и поддерживается только следующими базами данных jOOQ :
- CUBRID
- HSQLDB
- оракул
- Sybase SQL Anywhere
Существует другой способ вычисления MEDIAN() в частности и любого вида процентиля в целом в стандарте SQL, и, поскольку PostgreSQL 9.4 также в PostgreSQL, используя…
Упорядоченно-заданные агрегатные функции
Интересно, что помимо оконных функций вы также можете указать предложения ORDER BY для определенных агрегатных функций, которые агрегируют данные на основе упорядоченных наборов.
Одной из таких функций является стандартная функция percentile_cont в SQL, которая принимает процентиль в качестве аргумента, а затем принимает дополнительное предложение WITHIN GROUP , которое принимает предложение ORDER BY в качестве аргумента. Эти конкретные функции упорядоченного набора также называют обратными функциями распределения , потому что мы хотим найти, где находится конкретный процентиль в распределении всех значений в образце ( если вас не пугает математика, ознакомьтесь со статьей в Википедии )
Итак, в PostgreSQL 9.4+ функцию MEDIAN MEDIAN() можно эмулировать так:
|
01
02
03
04
05
06
07
08
09
10
|
WITH t(value) AS ( SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 100)SELECT avg(value), percentile_cont(0.5) WITHIN GROUP (ORDER BY value)FROM t; |
Этот интересный синтаксис стандартизирован и может быть известен некоторым из вас из Oracle LISTAGG () , который позволяет объединять значения в объединенные строки:
|
1
2
3
4
5
6
7
8
9
|
WITH t(value) AS ( SELECT 1 FROM DUAL UNION ALL SELECT 2 FROM DUAL UNION ALL SELECT 100 FROM DUAL)SELECT listagg(value, ', ') WITHIN GROUP (ORDER BY value)FROM t; |
Этот запрос дает просто:
|
1
2
3
|
listagg---------1, 2, 100 |
С другой стороны: LISTAGG() , конечно, совершенно бесполезен, потому что он возвращает VARCHAR2 , который снова имеет максимальную длину 4000 в Oracle. Бесполезный…
Эмуляция из коробки с JOOQ
Как всегда, JOOQ будет эмулировать подобные вещи из коробки. Вы можете использовать либо DSL.median() , либо с выходом jOOQ 3.6 новую DSL.percentileCont() для получения того же значения:
|
1
2
3
4
5
6
7
|
DSL.using(configuration) .select( median(T.VALUE), percentileCont(0.5).withinGroupOrderBy(T.VALUE) ) .from(T) .fetch(); |
| Ссылка: | Как эмулировать агрегатную функцию MEDIAN () с использованием функций обратного распределения от нашего партнера по JCG Лукаса Эдера из блога JAVA, SQL и AND JOOQ . |