С недавно выпущенной версией MapR 5.0 клиенты MapR получили еще одну мощную функцию без дополнительных затрат на лицензирование: Аудит! В этом двухступенчатом сообщении в блоге я опишу различные варианты использования для аудита, а также инструкции по их развертыванию в среде MapR.
Функции аудита в MapR позволяют регистрировать записи аудита операций администрирования кластера, а также операций с каталогами, файлами и таблицами. Помимо очевидного варианта использования для определения того, кто чем занимается в вашем кластере, данные аудита также позволяют использовать другие варианты использования, которые я опишу в этом сообщении в блоге. В следующем посте я опишу, как настроить Apache Drill для запросов к журналам аудита.
Темы, рассматриваемые в этом блоге, касаются следующих пяти вариантов использования, включая добавленную стоимость, которую они предоставляют, а также практические описания их развертывания. Давайте начнем с обобщения вариантов использования:
- Несанкционированные изменения кластера и доступ к данным
- Соблюдение нормативно-правовой базы и законодательства
- Тепловые карты использования данных на холодных, теплых и горячих данных
- Аналитика доступа к данным и улучшения производительности
- Политики защиты данных для данных, которые имеют значение с использованием моментальных снимков и зеркалирования
Представляем аудит
Новые мощные возможности аудита в MapR 5.0 позволяют регистрировать использование кластера и изменения на разных уровнях. Прежде всего, любые административные задачи, выполняемые в кластере, могут регистрироваться независимо от методологии, используемой для администрирования кластера. Во-вторых, доступ к данным на уровне тома, каталога, файла и таблицы можно включить, чтобы обеспечить аудит доступа к данным на детальном уровне.
Включая аудит на уровне администрирования кластера, каждое действие, выполняемое с помощью службы управления MapR (MCS), интерфейса командной строки MapR (maprcli) и REST API, регистрируется. Кроме того, каждая попытка аутентификации в MCS, будь то успешная или неудачная, регистрируется.
Поскольку все журналы аудита записываются в формате файла JSON, мощь Apache Drill позволяет запрашивать эту информацию с помощью ANSI SQL, что означает, что вы можете использовать любой из ваших любимых инструментов Business Intelligence для визуализации информации аудита. В следующем блоге я опишу настройку Apache Drill для запроса журналов аудита.
В этом блоге я объясню, как включить различные уровни аудита. Но сначала давайте взглянем на мощные сценарии использования, которые обеспечивает функция аудита MapR:
Аудит в MapR: 5 вариантов использования бизнеса
- Несанкционированные изменения кластера и доступ к данным
Включение ведения журнала аудита на уровне кластера дает большую ценность, когда речь заходит о том, кто что меняет с административной точки зрения в кластере MapR. Так как он также регистрирует как успешные, так и неудачные попытки входа в систему в кластере MapR, он дает представление о людях, пытающихся получить несанкционированный доступ к кластеру, на основе количества неудачных попыток входа в систему. Параллельно операции ведения журналов на уровне файловой системы и таблиц позволяют администраторам кластера отвечать на следующие важные вопросы:
- Кто касался записей клиентов в нерабочее время?
- Какие действия предприняли пользователи за несколько дней до ухода из компании?
- Какие операции были выполнены без последующего контроля изменений?
- Получают ли пользователи доступ к конфиденциальным файлам с защищенных или защищенных IP-адресов?
- Соблюдение нормативно-правовой базы и законодательства
Информация об аудите очень полезна, когда вашей компании необходимо соблюдать строгие правила и законы. В случае аудита соответствия независимой независимой бухгалтерской фирмой файлы журнала аудита предоставляют всю необходимую информацию о том, кто что сделал в кластере. Это значительно сокращает время внешнего аудита и, следовательно, экономит ваше время и деньги. Это также повышает уровень зрелости вашей организации, одновременно защищая ваш бренд от ущерба репутации из-за несанкционированного доступа к данным. - Тепловые карты использования данных для большинства и наименее часто используемых данных
Поскольку журналы аудита доступа к данным записываются в формате файла JSON, легко создавать тепловые карты использования данных с помощью вашего любимого инструмента Business Intelligence и Apache Drill. Создание таких тепловых карт для холодных, теплых и горячих данных позволяет вам консультировать пользователей по важным и ценным данным, а также по редко используемым и неисследованным данным. - Аналитика доступа к данным и улучшения производительности
Описанные выше тепловые карты также являются важной информацией для планирования размещения данных кластера. Одним из вариантов использования может быть то, что конечные пользователи испытывают снижение производительности на томе данных. При создании первоначальной структуры кластера администратор мог установить уровень репликации тома в соответствии со стандартом трех реплик (это означает, что есть три узла кластера, которые могут обслуживать данные в случае запроса конечного пользователя). Хотя база данных местоположения контейнера MapR (CLDB) распределяет нагрузку по кластеру для удаления горячих точек, количество запросов данных может быть слишком высоким для установленного уровня репликации. Исходя из фактического использования данных, как показано в тепловых картах (конечным пользователем, заданиями mapreduce, приложениями Spark Streaming или другими), может быть полезно повысить уровень репликации для увеличения локальности данных и иметь больше узлов, способных обслуживать эти конкретные данные. объем. Это значительно улучшит взаимодействие с конечным пользователем по производительности доступа к данным. - Политики защиты данных для данных, которые имеют значение с использованием моментальных снимков и зеркалирования
Чтобы обеспечить безопасность важных данных вашей компании, тепловые карты могут оказать большую помощь при рассмотрении ваших снимков и политик зеркального отображения, которые в настоящее время развернуты в кластере. Тома данных, которые выполняют множество действий по обновлению и удалению, являются кандидатами в высокочастотную политику снимков. Это необходимо для того, чтобы избежать катастрофы в случае, если важные данные будут случайно перезаписаны или удалены из-за ошибок конечного пользователя. Кроме того, необходимо проверить зеркальное отображение этих часто используемых томов данных, чтобы убедиться, что эти данные доступны во вторичном расположении. Таким образом, ваша компания сможет продолжить работу, даже если вы столкнулись с аварией в своем основном центре обработки данных.
Включение аудита вариантов использования в вашем кластере MapR
В этом разделе я покажу вам, как извлечь выгоду из использования приведенных выше вариантов использования в вашем кластере MapR. Сначала мы начнем с включения ведения журнала аудита на уровне кластера MapR. После этого мы включим аудит на уровне тома, каталога, файла и таблицы, чтобы получить доступ ко всем данным. Обратите внимание, что для включения аудита используется емкость вашего кластера (как хранилища Linux, так и хранилища файловой системы MapR) для записи журналов аудита. Используя параметры ‘retention’ и ‘maxSize’, вы можете ограничить максимальное количество файлов журнала аудита, хранящихся на диске.
Во-первых, давайте проверим, включена ли функция аудита, выполнив следующую команду maprcli, которая должна вернуть «1»:
|
1
2
3
4
5
|
maprcli config load -json | grep "mfs.feature.audit.support"output example:auditing enabled: "mfs.feature.audit.support":"1"auditing disabled: "mfs.feature.audit.support":"0" |
Если вы обновили предыдущие версии MapR до версии 5.0, обратите внимание, что аудит еще не включен. Вы можете включить аудит с помощью следующей команды:
|
1
|
maprcli config save -values {"mfs.feature.audit.support":"1"} |
Включение аудита на уровне администрирования кластера
Начнем с включения аудита на уровне кластера для сбора всех административных задач, выполняемых в кластере. Выполните следующую команду CLI, чтобы включить аудит администрирования кластера:
|
1
|
maprcli audit cluster -enabled true |
Сразу после включения аудита на уровне кластера действия по управлению кластером, включая команды MCS и MapR CLI, записываются в следующие файлы журнала:
|
1
2
3
|
/opt/mapr/logs/initaudit.log.json/opt/mapr/logs/cldbaudit.log.json/opt/mapr/mapr-cli-audit-log/audit.log.json |
Чтобы просмотреть настройки аудита кластера, взгляните на объект ‘cluster’ в выводе следующей команды:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
maprcli audit info -jsonoutput example:{ "timestamp":1437568253988, "timeofday":"2015-07-22 12:30:53.988 GMT+0000", "status":"OK", "total":1, "data":[ { "data":{ "enabled":"1", "maxSizeGB":"500", "retentionDays":"180" }, "cluster":{ "enabled":"1", "maxSizeGB":"NA", "retentionDays":"NA" } } ]} |
Помимо использования CLI MapR, вы можете использовать MCS для включения аудита управления кластером. После входа в MCS используйте навигацию по меню слева, чтобы перейти к «Системные настройки> Аудит» и включить «Настроить аудит кластера» на экране, как показано:
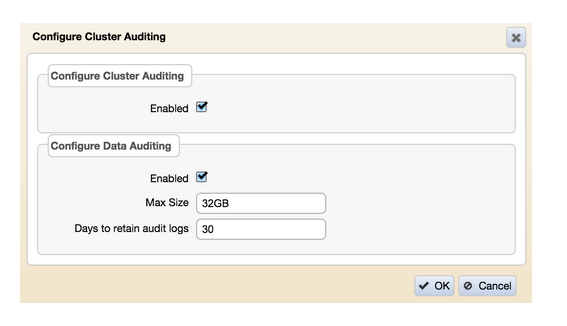
Включение аудита операций с каталогами, файлами и таблицами
В отличие от аудита операций на уровне кластера, аудит файловой системы и табличных операций должен быть включен на трех отдельных уровнях. Если аудит не включен ни на одном из этих уровней, операции над объектом файловой системы не регистрируются.
Аудит данных должен быть включен на трех уровнях: уровень кластера (с помощью команды аудита данных maprcli), уровень громкости (с помощью любой из трех команд тома maprcli) и уровень отдельного каталога, файла или таблицы. Ниже показана иерархия включения или отключения аудита на любом уровне кластера. Аудит на уровне каталогов, файлов или таблиц (элемент 3) будет включен только в том случае, если включен аудит на уровне томов (элемент 2) и на уровне кластера (элемент 1):
|
1
2
3
|
Cluster level auditing (enabled/disabled) - Volume level auditing (enabled/disabled) - Directory, file, table level auditing (enabled/disabled) |
Аудит данных — Шаг 1: уровень кластера
Начнем с включения аудита данных на уровне кластера (пункт 1). Параметр аудита данных можно рассматривать как главный переключатель для включения или отключения ведения журнала аудита на уровне данных для всего кластера:
|
1
2
3
4
5
6
|
maprcli audit data -enabled true-maxsize -retention example:maprcli audit data -enabled true -maxsize 500 -retention 180 |
Используя один или оба параметра («maxSize» и / или «retention»), можно максимизировать размер файла журнала аудита. При настройке обоих параметров это зависит от того, какой лимит стоит первым (например, размер журнала аудита в ГБ или период хранения в днях), который вызывает автоматическую очистку журнала кластером MapR.
Чтобы просмотреть настройки аудита данных, взгляните на объект «data» в выводе следующей команды:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
maprcli audit info -jsonoutput example:{ "timestamp":1437568253988, "timeofday":"2015-07-22 12:30:53.988 GMT+0000", "status":"OK", "total":1, "data":[ { "data":{ "enabled":"1", "maxSizeGB":"500", "retentionDays":"180" }, "cluster":{ "enabled":"1", "maxSizeGB":"NA", "retentionDays":"NA" } } ]} |
Помимо использования CLI MapR, вы можете использовать MCS для включения аудита данных на уровне кластера. После входа в MCS используйте навигацию по меню слева, чтобы перейти к «Системным настройкам> Аудит» и включить «Настроить аудит данных» на экране, как показано:
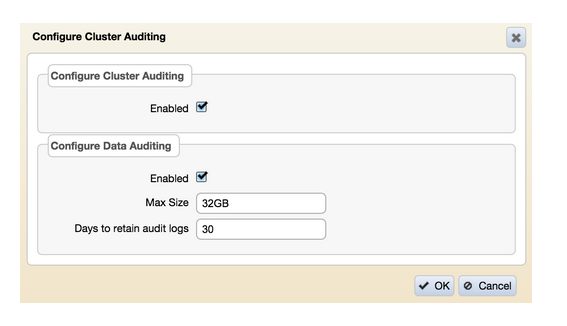
Аудит данных — Шаг 2: уровень громкости
Теперь, когда у нас включен аудит данных на уровне кластера (элемент 1), давайте сделаем следующий шаг, включив аудит на уровне тома (элемент 2). Существует три различных способа включить аудит на уровне тома, в зависимости от того, существует ли уже том или нет. Помимо команд «maprcli volume create» и «mapcli volume modify», есть команда «maprcli volume аудит», которую я буду использовать в этом блоге. Все три команды maprcli имеют одинаковый эффект.
|
1
2
3
4
5
6
7
8
9
|
maprcli volume audit[ -cluster cluster_name ]-name volumeName [ -enabled ][ -coalesce interval in mins ]example for volume finance-project1:maprcli volume audit -name finance-project1 -enabled true -coalesce 5 |
С помощью команды CLI MapR аудита тома вы можете включать и отключать аудит на существующих томах. Кроме того, вы можете указать параметр coalesce, который позволяет настроить, чтобы идентичные действия, происходящие в указанный интервал времени, были сохранены как одна запись в журнале аудита. Например, если установить коалесцирование на 60 минут (по умолчанию), все идентичные действия, выполняемые в течение этого периода времени, приведут только к одной записи в журналах аудита.
Включение аудита на уровне громкости также можно выполнить с помощью MCS. Перейдите к «MapR-FS> Тома» и либо отредактируйте существующий том, либо создайте новый том, чтобы установить аудит:
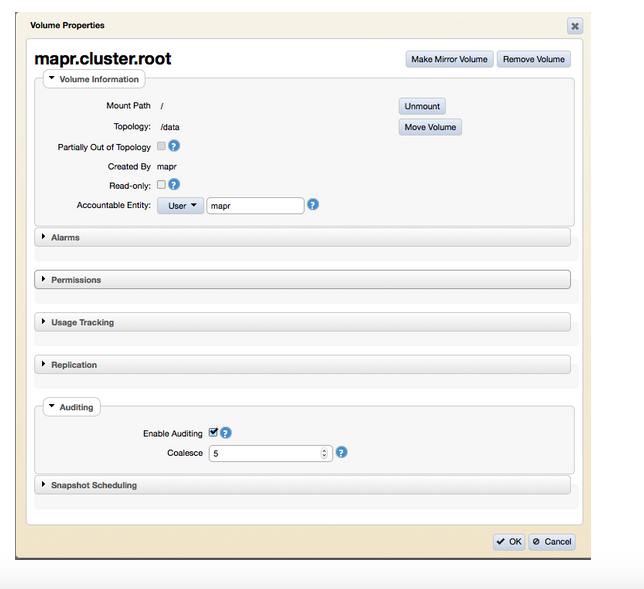
Аудит данных — Шаг 3: уровень каталога, файла или таблицы
Когда аудит данных включен как на уровне кластера, так и на уровне томов, пришло время включить аудит для определенных каталогов, файлов или таблиц. Это можно сделать только с помощью команды hadoop mfs setaudit, как показано ниже:
|
1
2
3
4
5
6
|
hadoop mfs -setaudit on|off <dir|file|table>example to activate the auditing on a directory, file or table:hadoop mfs -setaudit on /full/path/to/directoryhadoop mfs -setaudit on /full/path/to/filehadoop mfs -setaudit on /full/path/to/table |
После включения аудита убедитесь, что бит аудита установлен в вашем каталоге, файле или таблице, используя:
|
1
2
3
4
|
hadoop mfs -ls /drwxr-xr-x Z U U < auditing disabled, last bit being ‘U’drwxr-xr-x Z U A < auditing enabled, last bit being ‘A’ |
После этого все готово, и все действия в вашем кластере проверяются и регистрируются в файловой системе MapR по адресу:
|
1
|
/var/mapr/local//audit/. |
Если у вас есть настроенная NFS и смонтированный кластер MapR, вы можете найти журналы по адресу:
|
1
|
/mapr//var/mapr/local//audit/. |
Когда операции выполняются для проверяемых каталогов, файлов или таблиц, полные имена этих объектов, а также текущий том и имя пользователя, выполняющего операцию, не сразу доступны для функции аудита. Сразу же доступны идентификаторы для этих объектов и пользователей. Преобразование идентификаторов в имена во время выполнения будет дорогостоящим для производительности. Поэтому журналы аудита содержат идентификаторы файлов (FID) для каталогов, файлов и таблиц; идентификаторы объема для объема; и идентификаторы пользователей (UID) для пользователей.
Вы можете преобразовать идентификаторы в имена с помощью утилиты ExpandAuditLogs. Эта утилита создает копию файлов журнала для указанного тома, и в этой копии содержатся имена объектов, пользователей и томов файловой системы, которые есть в записях журнала аудита. Затем вы можете запросить или обработать копию.
Вывод
Благодаря аудиту MapR, выпущенному в версии 5.0, у вас есть еще одна мощная функция для управления кластером и потребностями в данных. Помимо очевидных случаев, когда кто-то делает что-либо с точки зрения управления кластером и использования данных, аудит MapR также допускает различные другие случаи использования, когда речь идет о политиках соответствия, производительности и защиты данных.
В моем следующем сообщении в блоге я покажу вам, как настроить Apache Drill для запроса через генерируемые журналы аудита.
Если у вас есть какие-либо дополнительные вопросы, пожалуйста, задавайте их в разделе комментариев ниже.
| Ссылка: | Изменение игры, когда дело доходит до аудита больших данных — часть 1 от нашего партнера по JCG Мартина Киебума в блоге Mapr . |