Джанлука Борделло — технический директор в Sysdig, где он носит много шляп. Он является основным разработчиком sysdig, инструмента для устранения неполадок с открытым исходным кодом для Linux и контейнеров, и проводит дни, занимаясь бэкэнд-разработкой, анализом производительности и управлением облачной инфраструктурой.
Вступление
Что касается баз данных, я большой поклонник Cassandra: это невероятно мощная и гибкая база данных, которая может принимать огромное количество данных при масштабировании на произвольное количество узлов. По этим причинам моя команда очень часто использует его для наших внутренних приложений.
Но, как и в случае с любым другим программным обеспечением, у Cassandra есть свои особенности и привычки, которые вам необходимо понять, чтобы эффективно развиваться с ним. В этой статье я покажу вам проблему производительности Cassandra, с которой мы недавно столкнулись, и я хочу рассказать о том, как мы обнаружили проблему, какие способы устранения неполадок мы сделали, чтобы лучше понять их, и как мы в конечном итоге решили их.
Проблема
Одно из наших внутренних приложений требует хранения и последующей обработки нескольких тысяч потоков, каждый из которых состоит из примерно десятка двоичных двоичных объектов, поступающих периодически. Поскольку у нас много потоков, и каждый большой двоичный объект может быть довольно большим (в диапазоне 10 КБ), мы решили использовать Cassandra 2.1 (очень стабильная версия на момент написания) и эту очень простую таблицу:
|
1
2
3
4
5
6
7
8
9
|
CREATE TABLE streams ( stream_id int, timestamp int, column0 blob, column1 blob, column2 blob, ... column10 blob, primary key (stream_id, timestamp)); |
В этой модели данных все большие двоичные объекты (10 в приведенном выше примере) для определенной временной метки хранятся в одной строке в виде отдельных столбцов. Это позволило нам написать очень простой код приложения, состоящий по существу из одной записи на поток в течение каждого периода. Наш типичный вариант использования для чтения требует только одного или двух больших двоичных объектов в любой момент времени. С помощью этой модели данных мы можем гибко запрашивать произвольную часть данных одним запросом, например так:
|
1
|
SELECT columnX from streams where stream_id=STREAM |
Некоторое время эта схема работала хорошо для нас, и время отклика, которое мы испытывали для базы данных, было очень хорошим.
Недавно мы заметили ухудшение производительности при запросе потоков, содержащих особенно большие двоичные объекты. Интуитивно это может показаться очень разумным, поскольку обрабатываемые данные больше, но было еще кое-что, что казалось странным: несмотря на то, что в среднем большие двоичные объекты были большими, те, которые мы получали в наших запросах, всегда были примерно того же размера, что и раньше.
Другими словами, казалось, что Кассандра всегда обрабатывает все 10 столбцов (включая большие), несмотря на то, что мы просто просим конкретный маленький столбец, что приводит к снижению времени отклика. Поначалу в эту гипотезу казалось трудно поверить, потому что Cassandra хранит каждый отдельный столбец отдельно, и существует интенсивная индексация, которая позволяет эффективно искать определенные столбцы.
Чтобы подтвердить нашу гипотезу, мы написали отдельный тест: в таблице из N столбцов, подобных нашей, запрос одного столбца всегда должен занимать почти одинаковое время, независимо от количества и размера других столбцов. С помощью небольшого сценария (https://github.com/gianlucaborello/cassandra-benchmarks/blob/master/cassandra_benchmark_1.py) мы получили следующие результаты:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
$ python ./cassandra_benchmark_1.pyResponse time for querying a single column on a large table (column size 100 KB):10 columns: 185 ms20 columns: 400 ms30 columns: 613 ms40 columns: 668 ms50 columns: 800 ms60 columns: 1013 ms70 columns: 1205 ms80 columns: 1376 ms90 columns: 1604 ms100 columns: 1681 ms |
Мы не могли быть более неправильными! Тесты доказали полную противоположность нашему предположению, и фактически время отклика, казалось, занимало время, прямо пропорциональное количеству столбцов в таблице, даже если запрос запрашивал только один из них!
Копаться в Кассандре
Чтобы лучше понять проблему, я использовал sysdig , инструмент для устранения неполадок с открытым исходным кодом. Если вы не знакомы с sysdig, у него есть возможность фиксировать состояние и активность системы в работающем экземпляре Linux, а затем сохранять, фильтровать и анализировать его. Думайте о sysdig как о strace + tcpdump + htop + iftop + lsof в одном.
Возвращаясь к нашей истории: я взял файл трассировки sysdig, выполняя тот же запрос предыдущего теста для таблицы из 100 столбцов:
|
1
|
SELECT column7 from streams where stream_id=1 |
Этот запрос возвращает очень маленький объем данных по сравнению со всем набором данных (около 10 МБ), как sysdig может легко сказать мне, посмотрев сетевую активность, генерируемую базой данных:
|
1
2
3
4
|
$ sysdig -r trace.scap -c topprocs_netBytes Process PID--------------------------------------------------------------------------------9.82M java 34323 |
Несмотря на это, выполнение запроса занимает почти 4 секунды, что намного больше, чем мы ожидаем в аналогичном сценарии. Давайте посмотрим на операции ввода-вывода файла Cassandra при выполнении этого отдельного запроса:
|
01
02
03
04
05
06
07
08
09
10
|
$ sysdig -r trace.scap -c topfiles_bytesBytes Filename--------------------------------------------------------------------------------971.04M /var/lib/cassandra/data/benchmarks/test-23182450d5c011e5acecb7882d261790/benchmarks-test-ka-130-Data.db538.80KB /var/lib/cassandra/data/benchmarks/test-23182450d5c011e5acecb7882d261790/benchmarks-test-ka-130-Index.db… |
Ничего себе, Кассандра, кажется, прочитала почти 1 ГБ из файла, хранящего данные для моей таблицы, почти весь размер таблицы:
|
1
2
3
4
5
6
|
$ du -hs /var/lib/cassandra/data/benchmarks/test-23182450d5c011e5acecb7882d261790/*...972M /var/lib/cassandra/data/benchmarks/test-23182450d5c011e5acecb7882d261790/benchmarks-test-ka-130-Data.db… |
Это означает, что Кассандра по сути читает весь файл, и это, вероятно, объясняет, почему время отклика зависит от общего количества столбцов таблицы.
Чтобы глубже взглянуть, я использовал спектрограмму в csysdig для событий ввода / вывода за время файла трассировки, чтобы мы могли визуализировать задержку Кассандры и частоту операций ввода / вывода:
|
1
|
$ csysdig -d 100 -r trace.scap -v spectro_file |
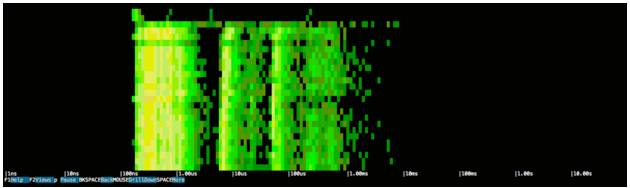
Если вы не знакомы со спектрограммой, вот высокий уровень:
- Он фиксирует каждый системный вызов (например, open, close, read, write, socket …) и измеряет задержку вызова
- Каждые 100 мс он организует звонки в ведра
- Спектрограмма использует цвет, чтобы указать, сколько вызовов в каждом сегменте
- Черный означает отсутствие звонков во время последнего образца
- Оттенки зеленого означают от 0 до 100 звонков
- Оттенки желтого означают сотни звонков
- Оттенки красного означают тысячи звонков или больше
Как следствие, левая сторона диаграммы имеет тенденцию показывать вещи, которые быстрые, в то время как правая сторона показывает вещи, которые медленны.
Это изображение ясно говорит нам о том, что, по-видимому, в течение всей продолжительности запроса наблюдается постоянная активность операций ввода-вывода, поэтому, как и предполагалось, доступ к этим 1 ГБ, вероятно, негативно влияет на время ответа. Кроме того, задержка активности ввода / вывода, по-видимому, сконцентрирована в двух диапазонах: один очень короткий (около 100 нс — 1 мкс) и один гораздо более значительный (около 10 мкс — 1 мс).
Давайте приблизимся к полосе справа, выбрав интересующую область:
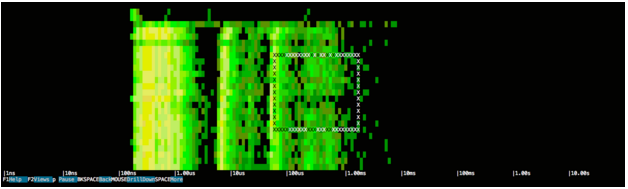
Этот выбор покажет список системных событий, которые соответствуют диапазону времени и спектру задержки:
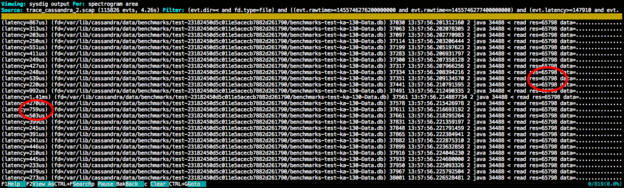
Операции чтения с табличного файла, тонны из них. Действительно, это, по сути, полное сканирование таблицы, выполненное путем чтения ее кусками по 64 КБ, и мы можем видеть, как все эти сотни заблокированных микросекунд, ожидающих ввода-вывода, складываются в конечном времени ответа.
Решение: Cassandra Schema Refactor
Мы были довольно озадачены, обнаружив такое поведение. Как я упоминал ранее, строки и столбцы в Cassandra сильно индексируются, поэтому мы знали, что для эффективного обслуживания запроса не было технических ограничений, считывая именно те 10 МБ с диска вместо полных 1 ГБ.
Проведя некоторое исследование, мы смогли найти проблему ( https://issues.apache.org/jira/browse/CASSANDRA-6586 ), описывающую эту проблему, и мы поняли, что такое поведение должно было быть таким, чтобы уважать некоторая семантика языка запросов CQL, принятая Cassandra (опущена здесь для краткости, но четко описана в проблеме), и разработчики согласились, что такое поведение может привести к значительному снижению производительности в таких случаях, как наш. Хотя эту проблему планируется решить в будущих версиях Cassandra, это оставило нам ошибку в рабочем приложении, которую нам пришлось каким-то образом решить.
Мы выбрали обходной путь: поскольку Cassandra всегда будет читать все столбцы строки CQL независимо от того, какие из них фактически запрашиваются в запросе, мы решили реорганизовать нашу схему, уменьшив размер каждой строки и вместо размещения всех двоичных объектов. в той же строке мы разбиваем их на несколько, например так:
|
1
2
3
4
5
6
|
CREATE TABLE streams ( stream_id int, column_no int, timestamp int, column blob, primary key (stream_id, column_no, timestamp)); |
С помощью этой новой схемы все наши строки стали намного меньше, но при этом мы можем эффективно запрашивать одну часть большого двоичного объекта с помощью запроса, такого как:
|
1
|
SELECT * from streams where stream_id=1 and column_no=7 |
Этот подход оказался довольно эффективным: приведенный выше запрос, который занимал 4 секунды со старой моделью данных в экстремальном тестовом случае, теперь занимал всего около 100 мс для того же набора данных! Также интересно проанализировать новый сценарий с помощью sysdig и проверить ввод-вывод Cassandra при обработке запроса:
|
1
2
3
4
5
6
7
|
$ sysdig -r trace.scap -c topfiles_bytesBytes Filename--------------------------------------------------------------------------------9.85M /var/lib/cassandra/data/benchmarks/test-55d49260d5cb11e5acecb7882d261790/benchmarks-test-ka-16-Data.db… |
Всего 10 МБ, точно такой же размер ожидаемого ответа. Мы также можем использовать sysdig, чтобы ответить на вопрос: как Cassandra узнала, как эффективно читать точное количество данных в джунглях размером более 1 ГБ? Конечно, мы можем посмотреть системные события, выполняемые процессом базы данных в файле:
|
01
02
03
04
05
06
07
08
09
10
|
$ sysdig -r trace.scap fd.filename=benchmarks-test-ka-16-Data.db11285 15:13:40.896875243 1 java (34482) < openfd=59(<f>/var/lib/cassandra/data/benchmarks/test-55d49260d5cb11e5acecb7882d261790/benchmarks-test-ka-16-Data.db) name=/var/lib/cassandra/data/benchmarks/test-55d49260d5cb11e5acecb7882d261790/benchmarks-test-ka-16-Data.db flags=1(O_RDONLY) mode=011295 15:13:40.896926004 1 java (34482) > lseek fd=59(<f>/var/lib/cassandra/data/benchmarks/test-55d49260d5cb11e5acecb7882d261790/benchmarks-test-ka-16-Data.db) offset=71986679 whence=0(SEEK_SET)11296 15:13:40.896926200 1 java (34482) < lseek res=71986679 |
Здесь мы видим, как Кассандра открывает файл таблицы, но заметила, что сразу же происходит операция lseek, которая, по существу, пропускает в одной операции 70 МБ данных, устанавливая смещение дескриптора файла с SEEK_SET равным 71986679. По сути, это типично «индексация файла». ”Работает, если смотреть с точки зрения системного вызова: Cassandra в значительной степени полагается на структуры данных для индексации различного содержимого таблицы, чтобы она могла быстро и эффективно перемещаться в произвольные и значимые места. В этом случае индекс содержал информацию о том, что столбцы с «stream_id = 1» и «column_no = 7» начинаются со смещения 71986679.
|
1
2
3
4
5
|
11400 15:13:40.898199496 1 java (34482) > readfd=59(<f>/var/lib/cassandra/data/benchmarks/test-55d49260d5cb11e5acecb7882d261790/benchmarks-test-ka-16-Data.db) size=6579811477 15:13:40.899058641 1 java (34482) < read res=65798 data=................................................................................ |
Сразу после перехода к правильному положению файла мы видим обычное последовательное чтение 64 КБ, чтобы перенести все данные в память и обработать их. Этот цикл перехода в правильное положение и чтения с него продолжается до тех пор, пока все данные (10 МБ) не будут полностью прочитаны.
Также довольно интересно посмотреть, как этот второй случай выглядит на спектрограмме:
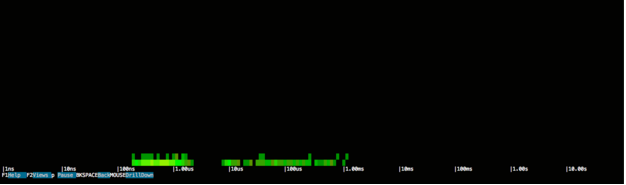
Спектр операций ввода-вывода почти такой же, как и раньше, а задержки сконцентрированы вокруг предыдущих значений, но обратите внимание на то, что высота диаграммы совершенно другая. Это связано с тем, что каждая горизонтальная линия представляет 100 мс времени, а поскольку весь запрос занимал около 100 мс, вся деятельность может быть представлена на гораздо более короткой диаграмме. Другими словами, высота диаграммы прямо пропорциональна времени отклика Кассандры, поэтому короткий значит быстрее.
Выводы
Эта история содержит два важных сообщения, посвященных мониторингу и устранению неполадок:
- Мониторинг: мониторинг всех уровней вашей инфраструктуры очень важен. В этом случае простое сопоставление объема данных, запрашиваемых у Cassandra, с объемом активности ввода-вывода, фактически сгенерированным базой данных, помогло нам найти причину проблемы, которую мы заметили, в первую очередь, еще раз проверив время отклика запросы.
- Устранение неполадок: с помощью sysdig я смог разобраться в специфическом поведении Cassandra (например, подтвердить, что индексирование действительно использовалось, наблюдая за действием lseek ()), даже не читая его код и не понимая его внутренности, что наверняка заняло бы у меня больше времени. Эта концепция очень эффективна: если у вас уже есть некоторые ожидания того, как определенное приложение должно вести себя, наблюдение за его активностью с точки зрения системного вызова во многих случаях может быть чрезвычайно эффективным способом устранения неполадок, не тратя много времени понимание менее важных деталей.
| Ссылка: | Рассказ об устранении неполадок с производительностью базы данных, с Cassandra и sysdig от нашего партнера по JCG Джанлуки Борелло в блоге Planet Cassandra . |