Эта статья была первоначально опубликована TeamSQL . Спасибо за поддержку партнеров, которые делают возможным использование SitePoint.
Импортировать большой объем данных в Redshift легко с помощью команды COPY. Чтобы продемонстрировать это, мы импортируем общедоступный набор данных «Данные Twitter для анализа настроений» (дополнительную информацию см. В Sentiment140 ).
Примечание . Вы можете подключиться к AWS Redshift с помощью TeamSQL, многоплатформенного клиента БД, который работает с Redshift, PostgreSQL, MySQL и Microsoft SQL Server и работает на Mac, Linux и Windows. Вы можете скачать TeamSQL бесплатно .
Загрузите ZIP-файл, содержащий данные обучения, здесь .
Группа красных смещений
Для целей этого примера спецификации конфигурации Redshift Cluster следующие:
- Тип кластера : один узел
- Тип узла : dc1.large
- Зона : мы-восток-1а
Создать базу данных в Redshift
Выполните следующую команду, чтобы создать новую базу данных в вашем кластере:
CREATE DATABASE sentiment;
Создать схему в базе данных настроений
Выполните следующую команду, чтобы создать схему в вашей только что созданной базе данных:
CREATE SCHEMA tweets;
Схема (структура) обучающих данных
Файл CSV содержит данные Twitter со всеми удаленными смайликами. Есть шесть столбцов:
- Полярность твита (ключ: 0 = отрицательный, 2 = нейтральный, 4 = положительный)
- Идентификатор твита (например, 2087)
- Дата твита (напр. Сб 16 мая 23:58:44 UTC 2009)
- Запрос (напр. Lyx). Если нет запроса, то это значение NO_QUERY.
- Пользователь, который твитнул (напр. Robotickilldozr)
- Текст твита (напр. Lyx это круто)
Создать таблицу для данных обучения
Начните с создания таблицы в вашей базе данных для хранения данных обучения. Вы можете использовать следующую команду:
CREATE TABLE tweets.training (
polarity int,
id BIGINT,
date_of_tweet varchar,
query varchar,
user_id varchar,
tweet varchar(max)
)
Загрузка файла CSV на S3
Чтобы использовать команду COPY от Redshift, вы должны загрузить свой источник данных (если это файл) на S3.
Чтобы загрузить файл CSV на S3:
- Разархивируйте файл, который вы скачали . Вы увидите 2 файла CSV: один представляет собой тестовые данные (используются для отображения структуры исходного набора данных), а другой (имя файла: training.1600000.processed.noemoticon) содержит исходные данные. Мы загрузим и используем последний файл.
- Сожмите файл . Если вы используете macOS или Linux, вы можете сжать файл с помощью GZIP, выполнив в терминале следующую команду:
gzip training.1600000.processed.noemoticon.csv - Загрузите файл с помощью панели инструментов AWS S3.
Кроме того, вы можете использовать терминал / командную строку для загрузки вашего файла. Для этого вы должны установить AWS CLI и после установки сконфигурировать его (запустите aws configure
Подключите TeamSQL к кластеру Redshift и создайте схему
Откройте TeamSQL (если у вас нет клиента TeamSQL, скачайте его с teamql.io ) и добавьте новое соединение.
- Нажмите Создать соединение, чтобы открыть окно Добавить соединение.

- Выберите Redshift и предоставьте запрашиваемую информацию для настройки вашего нового соединения.
- Не забудьте ввести имя базы данных по умолчанию !
- Проверьте соединение и сохраните, если проверка прошла успешно.
- По умолчанию TeamSQL отображает добавленные вами соединения в левой навигационной панели. Чтобы включить соединение, нажмите на значок сокета .
- Щелкните правой кнопкой мыши базу данных по умолчанию, чтобы открыть новую вкладку.

- Запустите эту команду, чтобы создать новую схему в вашей базе данных.
CREATE SCHEMA tweets;
- Обновите список базы данных в левой навигационной панели, щелкнув правой кнопкой мыши элемент подключения.
- Создайте новую таблицу для тренировочных данных.
CREATE TABLE tweets.training (
polarity int,
id int,
date_of_tweet varchar,
query varchar,
user_id varchar,
tweet varchar
)
- Обновите соединение, и ваша таблица должна появиться в левом списке.
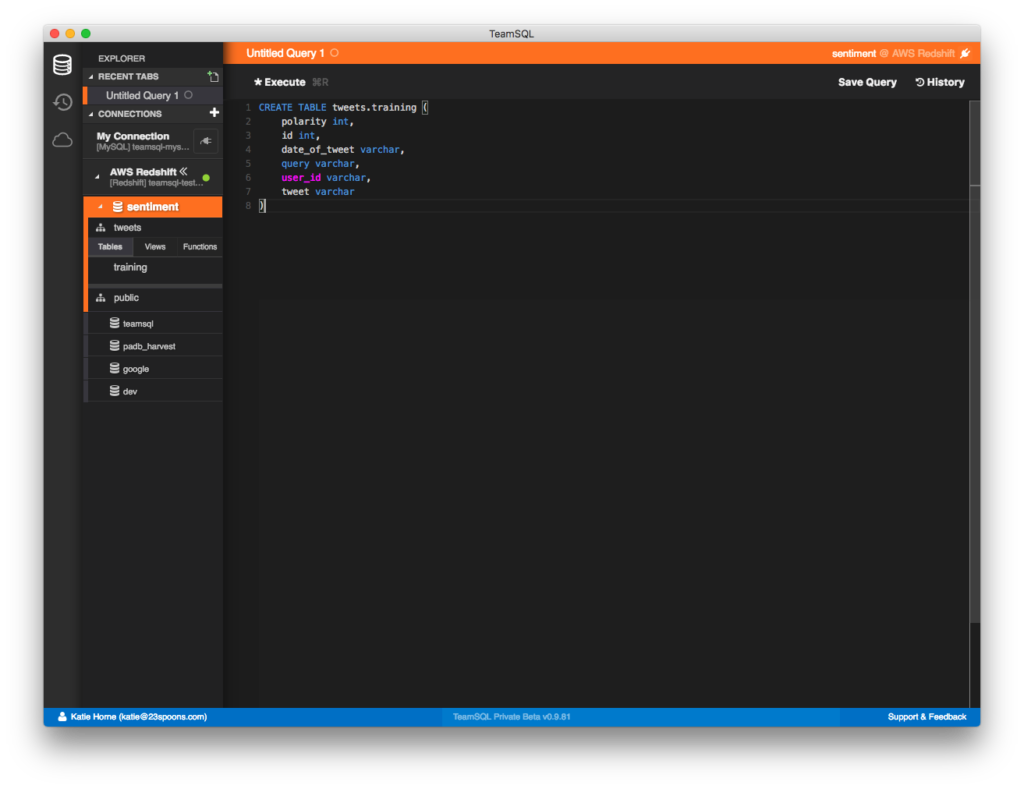
Использование команды COPY для импорта данных
Чтобы скопировать данные из исходного файла в таблицу данных, выполните следующую команду:
COPY tweets.training from 's3://MY_BUCKET/training.1600000.processed.noemoticon.csv.gz'
credentials 'aws_access_key_id=MY_ACCESS_KEY;aws_secret_access_key=MY_SECRET_KEY'
CSV GZIP ACCEPTINVCHARS
Эта команда загружает файл CSV и импортирует данные в нашу таблицу tweets.training
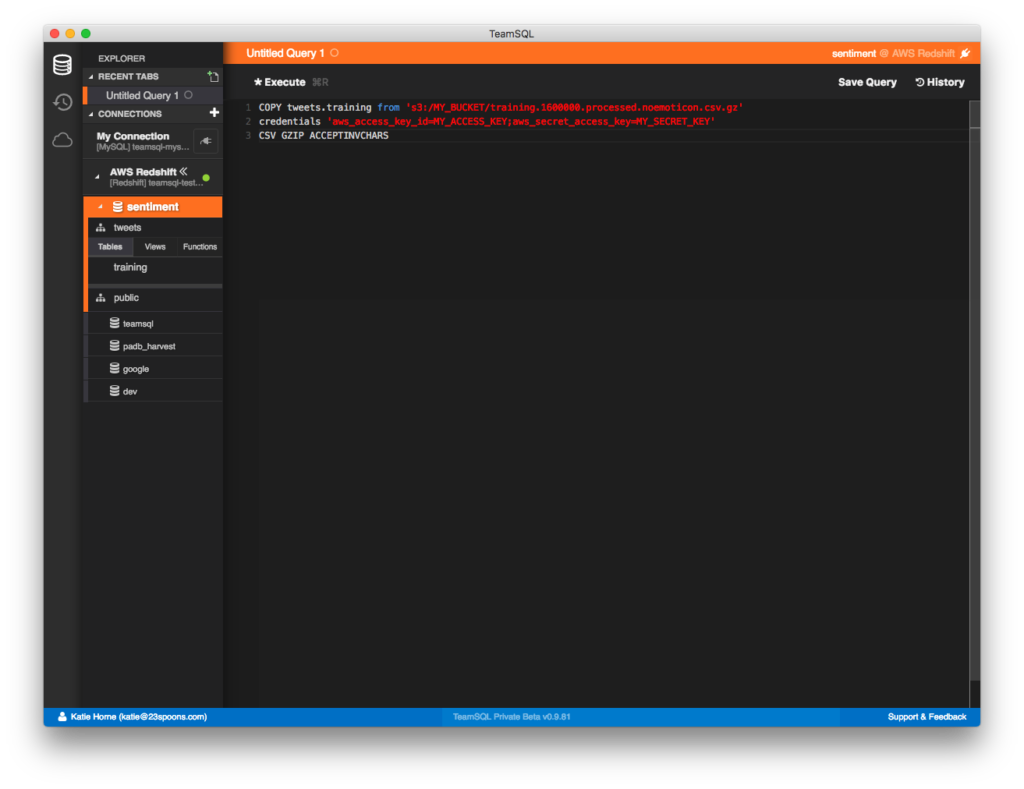
Определения параметров команды
CSV : позволяет использовать формат CSV во входных данных.
DELIMITER : Указывает один символ ASCII, который используется для разделения полей во входном файле, таких как символ канала (|), запятая (,) или табуляция (\ t).
GZIP : значение, указывающее, что входной файл или файлы имеют сжатый формат gzip (файлы .gz). Операция COPY читает каждый сжатый файл и распаковывает данные при загрузке.
ACCEPTINVCHARS : разрешает загрузку данных в столбцы VARCHAR, даже если данные содержат недопустимые символы UTF-8. Когда указано ACCEPTINVCHARS, COPY заменяет каждый недопустимый символ UTF-8 строкой равной длины, состоящей из символа, указанного для replace_char . Например, если заменяющий символ равен « ^^^^
Символ замены может быть любым символом ASCII, кроме NULL. По умолчанию используется знак вопроса (?). Для получения информации о недопустимых символах UTF-8 см. Ошибки загрузки многобайтовых символов .
COPY возвращает количество строк, содержащих недопустимые символы UTF-8, и добавляет запись в системную таблицу STL_REPLACEMENTS для каждой затронутой строки, максимум до 100 строк для каждого среза узла. Дополнительные недопустимые символы UTF-8 также заменяются, но эти события замены не записываются.
Если ACCEPTINVCHARS не указан, COPY возвращает ошибку всякий раз, когда встречается недопустимый символ UTF-8.
ACCEPTINVCHARS действителен только для столбцов VARCHAR.
Для получения дополнительной информации см. Параметры копирования Redshift и Формат данных .
Доступ к импортированным данным
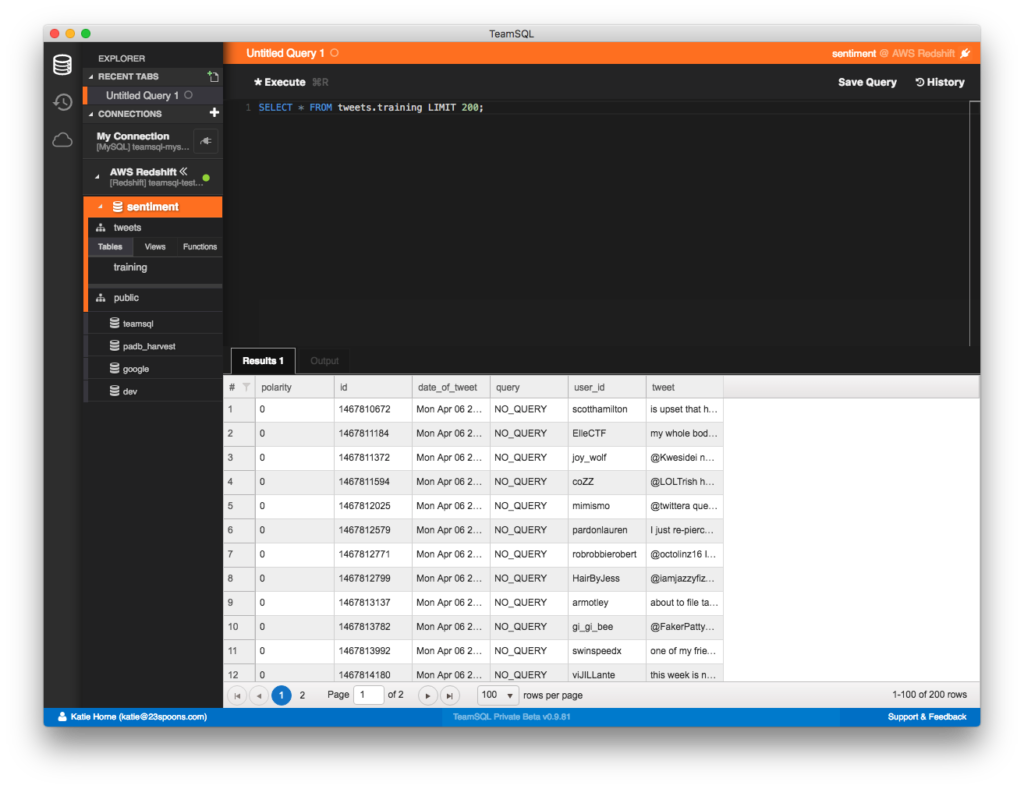
После завершения процесса COPY выполните запрос SELECT, чтобы убедиться, что все импортировано правильно:
SELECT * FROM tweets.training LIMIT 200;
Исправление проблем
Если вы получили ошибку при выполнении команды COPY, вы можете проверить журналы Redshift, выполнив следующее:
SELECT * FROM stl_load_errors;
Вы можете скачать TeamSQL бесплатно .