Git, без сомнения, самая популярная система контроля версий. По иронии судьбы, существуют и другие системы контроля версий, которые легче изучать и использовать, но, несмотря на это, Git — излюбленный вариант для разработчиков, который довольно ясно объясняет мощь Git.
В этом руководстве будут рассмотрены все темы, которые необходимо знать для правильного использования Git, от объяснения, что это такое и чем оно отличается от других инструментов, до его использования, а также расширенные темы и практики, которые могут добавить дополнительную ценность процессу контроль версий.
Содержание
- 1. Что такое контроль версий? Что такое Git?
- 2. Git против SVN (DVCS против CVCS)
- 3. Скачайте и установите Git
- 3.1. Linux
- 3.2. Windows
- 4. Использование Git
- 4.1. Создание хранилища
- 4.2. Создание истории: коммиты
- 4,3. Просмотр истории
- 4.4. Независимые направления развития: филиалы
- 4,5. Объединение историй: объединение ветвей
- 4,6. Конфликтующие слияния
- 4,7. Проверка различий
- 4.8. Пометка важных моментов
- 4.9. Отмена и удаление вещей
- 5. Ветвящиеся стратегии
- 5.1. Длинные ветки
- 5.2. Одна версия, одна ветка
- 5.3. Независимо от стратегии ветвления: одна ветвь для каждой ошибки
- 6. Удаленные репозитории
- 6.1. Запись изменений в пульт
- 6.2. Клонирование репозитория
- 6.3. Обновление удаленных ссылок: выборка
- 6.4. Получение и объединение пультов одновременно: вытягивание
- 6,5. Конфликты при обновлении удаленного репозитория
- 6.6. Удаление вещей в удаленном хранилище
- 7. Патчи
- 7.1. Создание патчей
- 7.2. Применение патчей
- 8. Сбор вишни
- 9. Крючки
- 9.1. Клиентские крючки
- 9.2. Крюки на стороне сервера
- 9.3. Крючки не входят в историю
- 10. Подход к непрерывной интеграции
- 11. Заключение
- 12. Ресурсы
1. Что такое контроль версий? Что такое Git?
Контроль версий — это управление изменениями, внесенными в систему, которые не обязательно должны быть программными.
Даже если вы никогда не использовали Git или подобные инструменты, вы, вероятно, когда-либо выполняли контроль версий. Очень используемая и плохая практика в разработке программного обеспечения — когда программное обеспечение достигло стабильной ситуации, сохранив его локальную копию, идентифицировав ее как стабильную, а затем следуя изменениям в другой копии.
Это то, что каждый разработчик программного обеспечения делал перед использованием определенных инструментов контроля версий, поэтому не расстраивайтесь, если вы это сделали. На самом деле, это намного лучше, чем прокомментировать код вроде:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
/* First versionpublic void foo(int bar) { return bar + 1;}*//* Second versionpublic void foo(int bar) { return bar - 1;}*/public void foo(int bar) { return bar * 2;} |
Который должен быть объявлен незаконным.
Системы контроля версий (VCS) предназначены для надлежащего управления изменениями. Эти инструменты предоставляют следующие функции:
- Обратимость.
- Параллелизм.
- Аннотация.
Обратимость — это основная возможность VCS, позволяющая вернуться к любой точке истории исходного кода, например, когда была введена ошибка и код должен вернуться к устойчивой точке.
Параллелизм позволяет нескольким людям вносить изменения в один и тот же проект, облегчая процесс интеграции фрагментов кода, разработанных двумя или более разработчиками.
Аннотация — это функция, которая позволяет добавлять дополнительные пояснения и размышления о внесенных изменениях, например, резюме выполненных изменений, причина, вызвавшая эти изменения, общее описание стабильности и т. Д.
С этим VCSs решают одну из наиболее распространенных проблем разработки программного обеспечения: страх перед изменением программного обеспечения . Возможно, вы будете знакомы со знаменитой поговоркой «если что-то работает, не меняйте это». Это почти шутка, но на самом деле мы действуем много раз. VCS поможет вам избавиться от страха перед изменением кода .
Существует несколько моделей для систем контроля версий. Тот, который мы упомянули, ручной процесс, можно рассматривать как локальную систему контроля версий, поскольку изменения сохраняются только локально.
Git — это распределенная система контроля версий (DVCS), также известная как децентрализованная. Это означает, что у каждого разработчика есть полная копия репозитория , которая размещается в облаке.
Мы подробнее рассмотрим функции DVCS в следующей главе.
2. Git против SVN (DVCS против CVCS)
До того, как DVCS проникли в мир контроля версий, самой популярной VCS был, вероятно, Apache Subversion (также известный как SVN). Эта VCS была централизованной (CVCS). Централизованная VCS — это система, разработанная так, чтобы иметь единственную полную копию хранилища, размещенную на каком-либо сервере, где разработчики сохраняют внесенные изменения .
Конечно, лучше использовать CVCS, чем локальный контроль версий, который несовместим с командной работой. Но наличие системы контроля версий, которая полностью зависит от централизованного сервера, имеет очевидное следствие: если сервер или соединение с ним обрывается, разработчики не смогут сохранить изменения. Или, что еще хуже, если центральное хранилище повреждено и резервная копия не существует, история хранилища будет потеряна.
CVCS также могут быть медленными . Запись изменений в хранилище означает эффективную смену удаленного хранилища, поэтому она зависит от скорости соединения с сервером.
Возвращаясь к Git и DVCSs, каждый разработчик имеет полный репозиторий локально. Таким образом, разработчики могут сохранять изменения в любое время . Если в определенный момент сервер, на котором размещено хранилище, не работает, разработчики могут продолжить работу без каких-либо проблем. И изменения могут быть записаны в общий репозиторий позже.
Другое отличие от CVCS состоит в том, что DVCS, особенно Git, работают намного быстрее , поскольку изменения вносятся локально, а доступ к диску быстрее, чем доступ к сети, по крайней мере в обычной ситуации.
Различия между обеими системами могут быть сведены к следующему: с CVCS вы вынуждены полностью зависеть от удаленного сервера для контроля версий, тогда как с DVCS удаленный сервер — это всего лишь вариант для обмена изменениями. ,
3. Скачайте и установите Git
3.1. Linux
Как вы, наверное, догадались, Git можно установить в Linux, выполнив следующие команды:
|
1
2
|
sudo apt-get updatesudo apt-get install git |
3.2. Windows
Во-первых, мы должны загрузить последний стабильный релиз с официальной страницы .
Запустите исполняемый файл и нажимайте кнопку «Далее», пока не перейдете к следующему шагу:
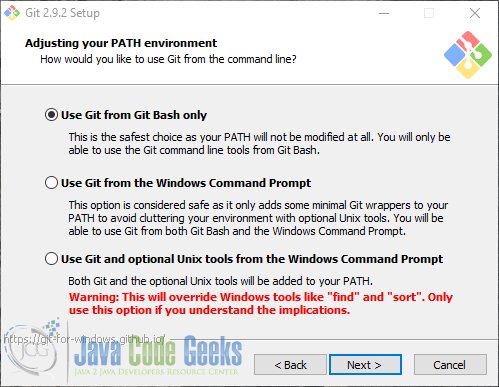
1. Настройка Git в Windows для использования только через Git Bash.
Проверьте первый вариант. Следующие параметры можно оставить по умолчанию. Вам около четырех или пяти лет назад следовало установить Git.
Теперь, если вы откроете контекстное меню (щелкните правой кнопкой мыши), вы увидите две новые опции:
- «Git GUI здесь».
- «Git Bash здесь».
В этом руководстве мы будем использовать bash. Все показанные команды будут для их выполнения в этом bash.
4. Использование Git
В этой главе мы увидим, как использовать Git для управления нашей версией.
4.1. Создание хранилища
Чтобы начать использовать Git, нам нужно сначала создать репозиторий, также известный как «репо». Для этого в каталоге, где мы хотим иметь хранилище, мы должны выполнить:
|
1
|
git init |
У нас есть Git-репозиторий! Обратите внимание, что папка с именем .git была создана. Хранилище будет каталогом, в котором находится папка .git . Эта папка представляет собой метаданные репозитория, встроенную базу данных. Лучше не трогать ничего внутри, пока вы не знакомы с Git.
4.2. Создание истории: коммиты
Git создает историю хранилища с коммитами. Фиксация — это полный снимок репозитория, который сохраняется в базе данных . Каждое состояние сохраненных файлов будет восстановлено позже в любой момент.
При выполнении фиксации мы должны выбрать, какие файлы будут зафиксированы; не все хранилище должно быть обязательно зафиксировано. Этот процесс называется этапом , когда файлы добавляются в индекс . Индекс Git — это место, где данные, которые будут сохранены в коммите, временно хранятся , пока коммит не будет выполнен.
Посмотрим, как это работает.
Мы собираемся создать файл и добавить к нему некоторый контент, например:
|
1
|
echo 'My first commit!' > README.txt |
При добавлении этого файла состояние хранилища изменилось, поскольку в рабочем каталоге был создан новый файл. Мы можем проверить состояние хранилища с помощью опции status :
|
1
|
git status |
Который в этом случае будет генерировать следующий вывод:
|
01
02
03
04
05
06
07
08
09
10
|
On branch masterInitial commitUntracked files: (use "git add <file>..." to include in what will be committed) README.txtnothing added to commit but untracked files present (use "git add" to track) |
Git говорит: «у вас есть новый файл в каталоге хранилища, но этот файл еще не выбран для фиксации ».
Если мы хотим включить этот файл в коммит, помните, что он должен быть добавлен в индекс. Это делается с помощью команды add , как Git предлагает в выводе status :
|
1
|
git add README.txt |
Опять же, состояние хранилища изменилось:
|
1
2
3
4
5
6
7
8
|
On branch masterInitial commitChanges to be committed: (use "git rm --cached <file>..." to unstage) new file: README.txt |
Теперь мы можем сделать коммит!
|
1
|
git commit |
Теперь будет показан текстовый редактор по умолчанию, где мы должны напечатать сообщение о коммите и затем сохранить. Если мы оставим сообщение пустым, фиксация будет прервана .
Кроме того, мы можем использовать сокращенную версию с флагом -m , указав встроенное сообщение коммита:
|
1
|
git commit -m 'Commit message for first commit!' |
Мы можем добавить все файлы текущего каталога, рекурсивно, в индекс с помощью . :
|
1
|
git add . |
Обратите внимание, что следующее:
|
1
2
3
4
|
echo 'Second commit!' > README.txtgit add README.txtecho 'Or is it the third?' > README.txtgit commit -m 'Another commit' |
Зафиксирует файл с помощью 'Second commit!' содержимое, потому что это был тот, который был добавлен в индекс, а затем мы изменили файл рабочего каталога , а не тот, который был добавлен в промежуточную область. Чтобы зафиксировать последнее изменение, мы должны были бы снова добавить файл в индекс, будучи первым перезаписанным файлом.
Git идентифицирует каждый коммит уникально, используя хеш-функцию SHA1, основываясь на содержимом зафиксированных файлов. Таким образом, каждый коммит идентифицируется шестнадцатеричной строкой длиной в 40 символов, например, следующим: de5aeb426b3773ee3f1f25a85f471750d127edfe . Примите во внимание, что сообщение фиксации, дата фиксации или любая другая переменная, а не содержимое (и размер) зафиксированных файлов, не включаются в вычисление хэша.
Итак, для наших первых двух коммитов история будет следующей:
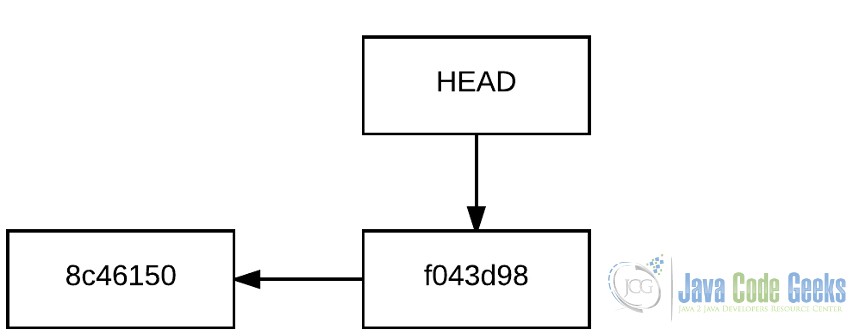
2. История хранилища, с двумя коммитами.
Git сокращает контрольную сумму каждого коммита до 7 символов (когда это возможно), чтобы сделать их более разборчивыми.
Каждый коммит указывает на коммит, из которого он был создан, будучи так называемым «предком».
Обратите внимание, что элемент HEAD . Это один из самых важных элементов в Git. HEAD — это элемент, который указывает на текущую точку в истории хранилища. Содержимое рабочего каталога будет соответствовать снимку, на который указывает HEAD .
Мы увидим эту HEAD более подробно позже.
4.2.1. Советы по созданию хороших коммитов
Содержание сообщения о коммите более важно, чем может показаться на первый взгляд. Git позволяет добавлять любые пояснения к любым внесенным нами изменениям, не затрагивая исходный код, и мы всегда должны этим пользоваться.
Для форматирования сообщения существует неписанное правило, известное как правило 50/72 , которое очень просто:
- Одна первая строка с кратким изложением не более 50 символов.
- Оберните последующие объяснения в строки не более 72 символов.
Это основано на том, как Git форматирует вывод, когда мы просматриваем историю.
Но, что более важно, это содержание самого сообщения. Первое, что приходит на ум, — это внесенные изменения, что совсем неплохо. Но сам объект фиксации является описанием изменений, которые были сделаны в исходном коде. Чтобы сделать сообщения коммита полезными, вы всегда должны указывать причину, по которой произошли изменения .
4,3. Просмотр истории
Конечно, Git умеет показывать историю хранилища. Для этого используется команда log :
|
1
|
git log |
Если вы попробуете это, вы увидите, что вывод не очень хороший. Команда log имеет много доступных флагов для рисования симпатичных графиков. Вот совет по использованию этой команды в этом руководстве, даже если для каждого сценария показаны графики:
|
1
|
git log --all --graph --decorate --oneline |
Если вы хотите, вы можете опустить флаг --oneline для отображения полной информации о каждом коммите.
4.4. Независимые направления развития: филиалы
Ветвление, вероятно, самая мощная особенность Git. Филиал представляет собой независимый путь развития . Ветви сосуществуют в одном и том же хранилище, но у каждой своя история. В предыдущем разделе мы работали с веткой, веткой Git по умолчанию, которая называется master .
Принимая это во внимание, правильный способ выразить историю будет следующим, учитывая ветви.
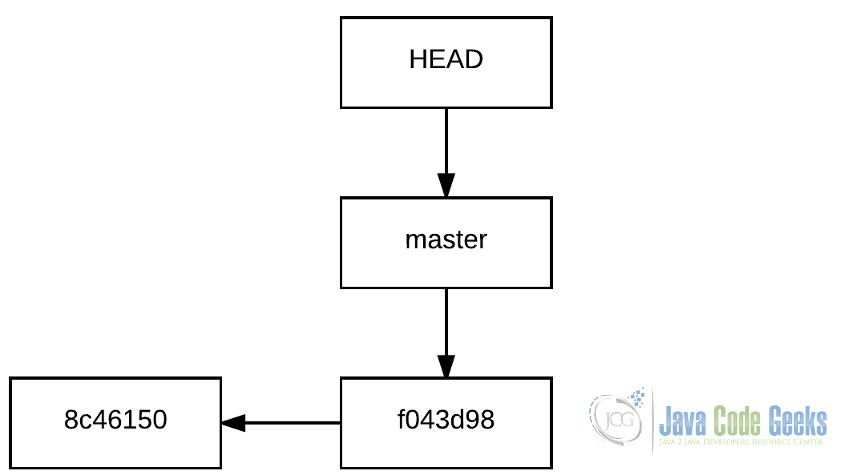
3. История репозитория, показывающая указатель ветки.
Создать ветку с помощью Git так просто:
|
1
|
git branch <branch-name> |
Например:
|
1
|
git branch second-branch |
Вот и все.
Но что на самом деле делает Git, когда создает ветку? Он просто создает указатель с тем именем ветви, которое указывает на коммит, в котором была создана ветка:
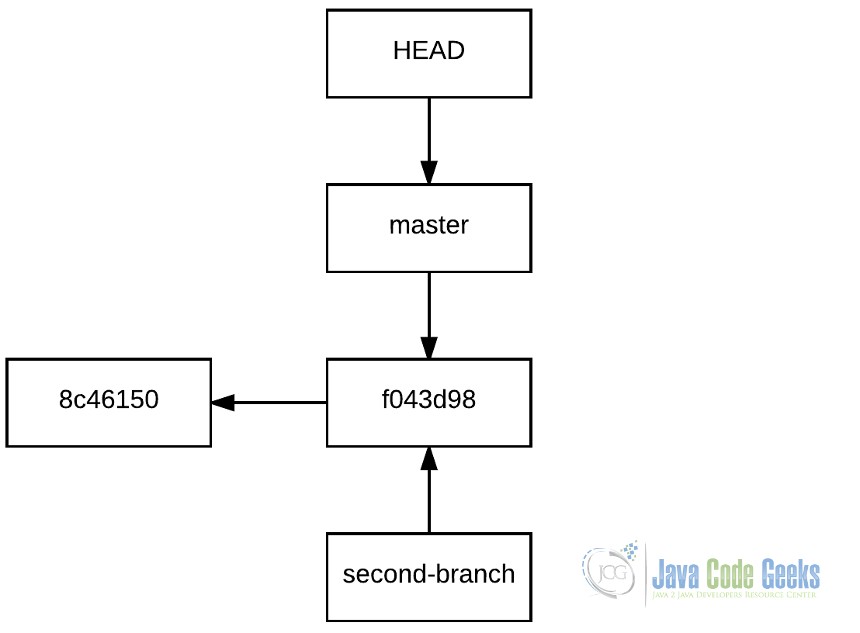
4. История хранилища с новой веткой.
Это одна из наиболее заметных особенностей Git: скорость создания веток, практически мгновенная, независимо от размера хранилища.
Чтобы начать работать в этой ветке, мы должны checkout :
|
1
|
git checkout second-branch |
Теперь коммиты будут существовать только во second-branch . Почему? Поскольку HEAD сейчас указывает на second-branch , то история, созданная с этого момента, будет иметь независимый путь от master .
Мы видим, что он делает пару коммитов, находящихся во second-branch :
|
1
2
3
4
5
6
|
echo 'The changes made in this branch...' >> README.txt git add README.txt git commit -m 'Start changes in second-branch'echo '... Only exist in this branch' >> README.txt git add README.txt git commit -m 'End changes in second-branch' |
Если мы проверим содержимое файла, который мы изменяем, мы увидим следующее:
|
1
2
3
|
Second commit!The changes made in this branch...... Only exist in this branch |
Но что, если мы вернемся к master ?
|
1
|
git checkout master |
Содержимое файла будет:
|
1
|
Second commit! |
Это потому, что после создания истории second-branch мы поместили HEAD указывающий на master :
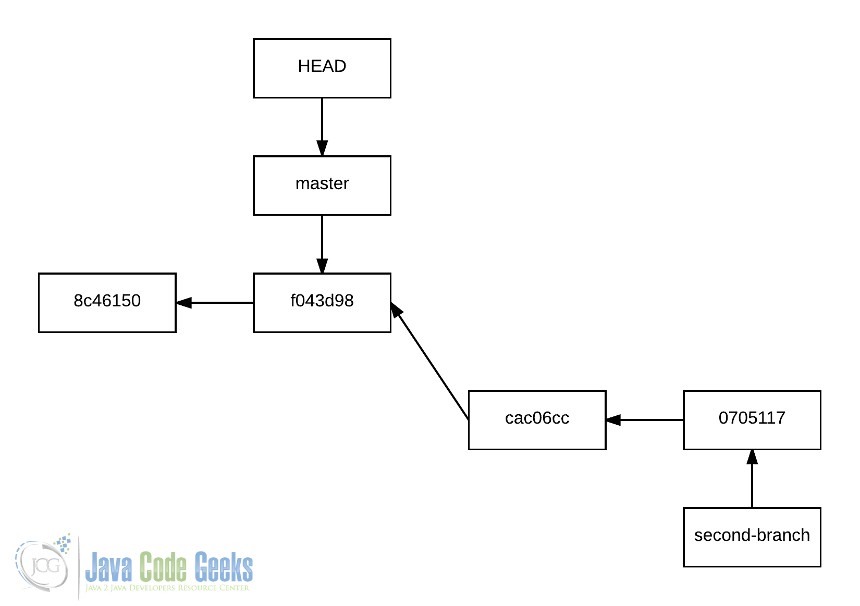
5. Независимая история для второй ветви.
4,5. Объединение историй: объединение ветвей
В предыдущем подразделе мы увидели, как мы можем создать разные пути для истории нашего хранилища. Теперь мы посмотрим, как их объединить, что Git называет слиянием .
Предположим, что после изменений, внесенных во second-branch , готов вернуться к master . Для этого мы должны поместить HEAD в целевую ветвь ( master ) и указать ветвь, которая будет объединена с этой целевой ветвью ( second-branch ), с помощью команды merge :
|
1
2
|
git checkout mastergit merge second-branch |
И Git выдаст следующий вывод:
|
1
2
3
4
|
Updating f043d98..0705117Fast-forward README.txt | 2 ++ 1 file changed, 2 insertions(+) |
Теперь история second-branch была объединена с master , поэтому все изменения, сделанные в этой первой ветви, были применены ко второй.
В этом случае вся история второго филиала теперь является частью истории мастера, имея график, подобный следующему:
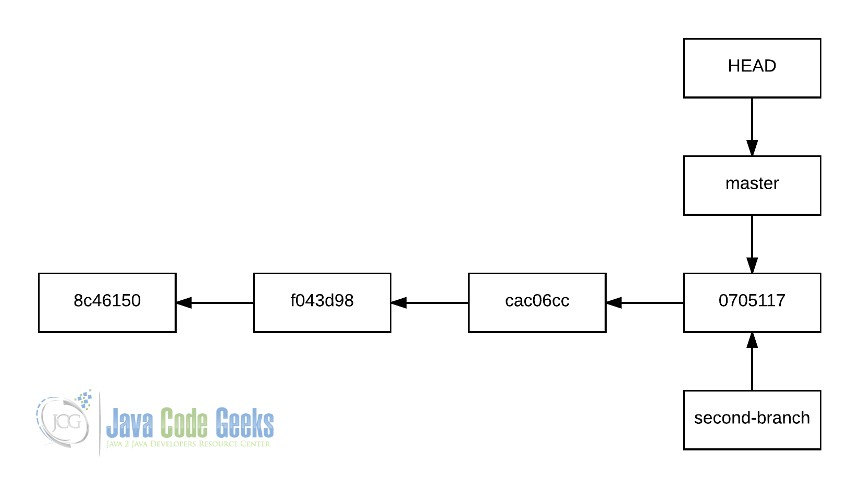
6. История после слияния второй ветки с мастером.
Как видите, ни один трек жизни second-branch не был сохранен, когда вы, вероятно, ожидали красивое дерево.
Это потому, что Git слил ветку, используя режим fast-forward . Обратите внимание, что это сказано в выводе слияния, показанном выше. Почему Git сделал это? Поскольку master и second-branch общего предка , f043d98 .
Когда мы объединяем ветки, всегда желательно не использовать режим fast-forward . Это достигается передачей флага --no-ff при объединении:
|
1
|
git merge --no-ff second-branch |
Что это действительно делает? Что ж, он просто создает промежуточный третий коммит между HEAD и последним коммитом ветви from.
После сохранения сообщения коммита (конечно, редактируемого), ветка будет объединена, имея следующую историю:
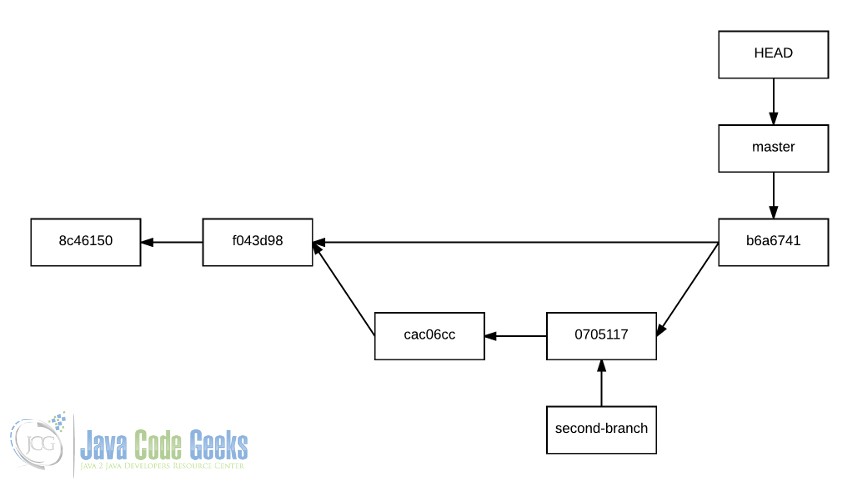
7. История после слияния второй ветви с мастером без использования режима ускоренной перемотки.
Что гораздо более выразительно, так как история отражается так, как она есть на самом деле. Режим ускоренной перемотки не должен использоваться всегда .
Слияние ветви предполагает конец жизни этого. Итак, его следует удалить:
|
1
|
git branch -d second-branch |
Конечно, в будущем вы можете снова создать second-branch именем branch.
4,6. Конфликтующие слияния
В предыдущем разделе мы видели «автоматическое» слияние, т. Е. Git смог объединить обе истории. Почему? Из-за ранее упомянутого общего предка . То есть ветвь возвращается к точке, с которой она началась.
Но когда ветвь, от которой страдает другая ветвь, претерпевает изменения, возникают проблемы.
Чтобы понять это, давайте создадим новую историю, которая будет иметь следующий график:
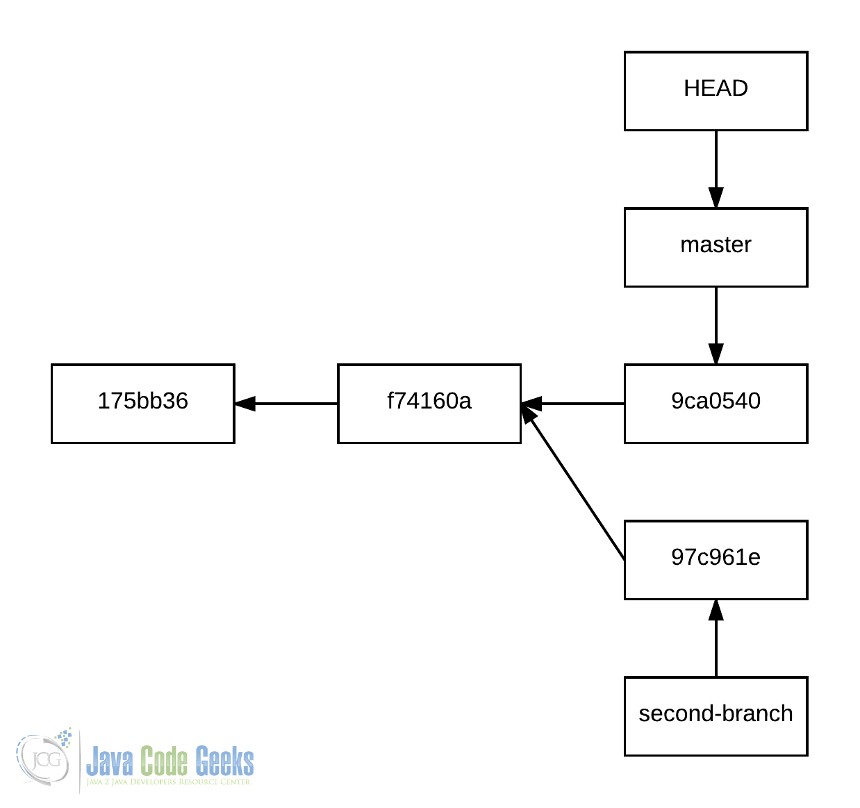
8. Продолжаем историю мастера, после создания второй ветки.
С помощью следующих команд:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
echo 'one' >> file.txtgit add file.txtgit commit -m 'first'echo 'two' >> file.txtgit add file.txt git commit -m 'second'git checkout -b second-branchecho 'three (from second-branch)' >> file.txt git add file.txt git commit -m 'third from second branch'git checkout masterecho 'three' >> file.txt git add file.txt git commit -m 'third' |
Что будет, если мы попытаемся объединить second-branch с master ?
|
1
2
|
git checkout mastergit merge second-branch |
Git не сможет это сделать:
|
1
2
|
CONFLICT (content): Merge conflict in file.txtAutomatic merge failed; fix conflicts and then commit the result. |
Git не знает, как это сделать, потому что изменения, сделанные во second-branch , напрямую не применимы к master , так как он изменился с момента создания первой ветви . Что Git сделал, так это указал, в каких частях существуют эти несовместимости.
Обратите внимание, что мы не использовали флаг --no-ff , так как теперь мы заранее знаем, что ускоренная перемотка вперед невозможна.
Если мы проверим status , мы увидим следующее:
|
1
2
3
4
5
6
7
8
|
On branch masterYou have unmerged paths. (fix conflicts and run "git commit")Unmerged paths: (use "git add <file>..." to mark resolution) both modified: file.txt |
Показаны конфликтующие файлы. Если мы откроем его, то увидим, что Git добавил несколько странных строк:
|
1
2
3
4
5
6
7
|
onetwo<<<<<<< HEADthree=======three (from second-branch)>>>>>>> second-branch |
Git указал, какие несовместимые изменения. И как это узнать? Несовместимые изменения — это те изменения, которые были внесены в объединяющую ветвь «to» ( master ) с момента создания объединяющей ветки «from» ( second-branch ) .
Теперь мы должны решить, как объединить изменения. С одной стороны, показаны изменения, внесенные в текущий HEAD (между <<<<<<< HEAD и ======= ), а с другой — ветвь, которую мы пытаемся объединить (между ======= и >>>>>>> second-branch ). Для разрешения конфликта есть три варианта:
- Используйте версию
HEAD. - Используйте версию
second-branch. - Сочетание двух версий.
Независимо от этой опции файл должен заканчиваться без метасимволов, добавленных Git для выявления конфликтов.
После разрешения конфликтов мы должны добавить файл в индекс и продолжить слияние с помощью команды commit :
|
1
2
|
git add file.txtgit commit |
После сохранения коммита слияние будет выполнено, и Git создаст третий коммит для этого слияния, как, например, когда мы использовали --no-ff в предыдущем разделе.
4.6.1. Зная заранее, с какой версией остаться
Может случиться так, что мы заранее знаем, какую версию мы хотим выбрать в случае конфликтов. В этих случаях мы можем указать Git, какую версию использовать, чтобы она применялась напрямую.
Чтобы сделать это, мы должны передать параметр -X для merge , указывая, какую версию использовать:
|
1
|
git merge -X <ours|theirs> <branch-name> |
Таким образом, для использования версии HEAD мы должны использовать ours опцию; вместо этого, для использования версии, не являющейся HEAD , необходимо передать theirs версию.
То есть следующее:
|
1
|
git merge -X ours second-branch |
Оставил бы файл как показано:
|
1
2
3
|
onetwothree |
И, следующее:
|
1
|
git merge -X theirs second-branch |
Как следует:
|
1
2
3
|
onetwothree (from second-branch) |
4,7. Проверка различий
Git позволяет проверить различия между точками в истории. Это делается с помощью параметра diff .
4.7.1. Интерпретация различий
Прежде чем увидеть, на какие различия мы можем смотреть, сначала мы должны понять, как эти различия показаны.
Давайте посмотрим пример вывода разницы между одним и тем же файлом:
|
1
2
3
4
5
6
7
8
9
|
diff --git a/README.txt b/README.txtindex 31325b6..55e8d58 100644--- a/README.txt+++ b/README.txt@@ -1,2 +1,2 @@-This is-the original file+This file+has been modified |
Здесь a — предыдущая версия файла, а b — текущая версия.
Третья и четвертая строка обозначают каждую букву символом - или + .
Это @@ -1,2 +1,2 @@ называется «заголовок @@ -1,2 +1,2 @@ ». Это идентифицирует части кода, которые фактически изменились, не показывая общие части для обеих версий.
Формат следующий:
|
1
|
@@ <previous><from-line>,<number-of-lines> <current>,<from-line><number-of-lines> |
В таком случае:
- «Предыдущий»: идентифицируется с
-, соответствующийa. - «From-line»: номер строки, с которой начинаются изменения.
- «Количество строк»: количество отображаемых строк.
- «Текущий»: обозначен знаком «
+, что соответствует значениюb.
Наконец, какие строки вычитаются, а какие добавляются, отображаются. В этом случае две строки были вычтены из строки (с предшествующими - ), а две другие были добавлены (с предшествующими + ).
4.7.2. Различия между рабочим каталогом и последним коммитом
Одним из распространенных применений является проверка различий между рабочим каталогом и последним коммитом. Для этого достаточно выполнить:
|
1
|
git diff |
Который покажет разницу для каждого файла. Мы можем указать также конкретные файлы:
|
1
|
git diff <file1> <file2> |
4.7.3. Различия между точными точками в истории
Мы можем искать различия с:
- Идентификатор SHA1
- Названия филиалов
-
HEAD - Теги
Быть совместимым между ними.
Синтаксис следующий:
|
1
|
git diff <original>..<modified> |
Например, следующее будет показывать изменения, которые были применены к ветви dev , по сравнению с тегом v1.0 :
|
1
|
git diff v1.0..dev |
4.8. Пометка важных моментов
Пометка является одной из самых приятных особенностей Git, поскольку позволяет очень просто отмечать важные моменты в истории хранилища. Обычно теги используются для обозначения выпусков, не только для стабильных выпусков, но также для недоразвитых или неполных выпусков, таких как:
- Альфа
- Бета
- Освободить кандидата (RC)
Создать тег очень просто, нам просто нужно поместить HEAD в точку, которую мы хотим пометить, и просто указать имя tag опцией tag :
|
1
|
git tag -a <tag-name> |
Например:
|
1
|
git tag -a v0.1-beta1 |
Затем нас попросят напечатать сообщение для тега. Как правило, изменения, сделанные в последнем теге, указываются .
Как и при фиксации, мы можем указать встроенное сообщение тега с флагом -m :
|
1
|
git tag -a v0.1 -m 'v0.1 stable release, changes from...' |
Учтите, что имена тегов не могут повторяться в репозитории.
4.9. Отмена и удаление вещей
Git также позволяет отменять и изменять некоторые вещи в истории. В этом разделе мы увидим, что можно сделать и как.
4.9.1. Изменение последнего коммита
Довольно часто требуется изменить последний коммит, например, когда нужно добавить только строку кода; или даже изменить сообщение об обновлении, не меняя файл.
Для этого у Git есть флаг --amend для команды commit :
|
1
|
git commit --amend |
Это то же самое, что и фиксация, но вместо нового объекта фиксации последний из этой ветви будет перезаписан.
4.9.2. Отмена незафиксированных изменений
Это потому, что после коммита, когда мы продолжаем разработку, мы думаем, что выбрали неверный путь, и мы хотим сбросить изменения, вернувшись к состоянию последнего коммита.
Для этого используется команда checkout , как для перемещения между ветвями. Но при указании файла это сбрасывается до состояния последнего коммита.
Например:
|
1
2
3
4
5
|
echo 'one' > test.txtgit add test.txt git commit -m 'commit one'echo 'two' > test.txt git checkout test.txt # The content of test.txt is now 'one'. |
4.9.3. Удаление коммитов
Обычно мы хотим удалять коммиты, когда не хотим оставлять записи о смущающем коммите или просто для удаления бесполезных изменений.
Это достигается путем перемещения указателей ветки или HEAD . Перемещение указателей на предыдущие коммиты делает оставшиеся впереди коммиты «потерянными», не связанными из связанного списка. Для их перемещения используется команда reset .
Есть два способа сделать сброс: не касаясь рабочего каталога (программный сброс, флаг --soft ), или сбросить его тоже (жесткий сброс, флаг --hard ). То есть, если вы сделаете программный сброс, фиксация будет удалена, но изменения, сохраненные в этой / этой фиксации, останутся; и полный сброс, не оставит изменений, внесенных в коммит (ы) . Если флаг не указан, сброс будет выполнен мягко.
Давайте начнем сбрасывать вещи. Следующая команда удалит последний коммит, т. Е. HEAD который указывает HEAD :
|
1
|
git reset --hard HEAD~ |
Символ ~ предназначен для обозначения предка. Используется один раз, указывает на непосредственного родителя; дважды дедушка; и так далее. Но вместо того, чтобы набирать ~ n раз, мы можем указать n предков, которых мы хотим удалить:
|
1
|
git reset --hard HEAD~3 |
Что бы удалить последние 3 коммитов.
Возможно, вы заметили, что это может вызвать конфликты с этими коммитами с более чем одним предком, т. Е. Результат не-быстрого пересылки слияния. Ну, это не вызывает никаких проблем: следующий родитель, использующий HEAD~ , всегда первый. Но есть способ решить, кто из общих родителей следует: ^ , за которым следует номер родителя. Итак, следующее:
|
1
|
git reset --hard HEAD~2^2 |
Убрал бы два предыдущих коммита, но по пути второго предка.
Даже если можно указать, какой путь предка следует, рекомендуется всегда использовать синтаксис для первого предка (только ~ ), так как это проще, даже если потребуется больше команд (так как для обновления HEAD вам придется извлекать различные ветви позиция).
4.9.4. Удаление тегов
Удалить теги так просто:
|
1
|
git tag -d <tag-name> |
5. Ветвящиеся стратегии
Достигнув этой точки, вы, возможно, уже спросили себя: « Хорошо, ветки — это круто, но когда мне их создавать и объединять? »
Когда мы хотим осуществлять контроль версий, нам нужно знать, какой стратегии мы будем следовать. Использование Git без четкой политики ветвления — полная чушь .
Рабочий процесс ветвления зависит, главным образом, от того, как мы хотим поддерживать код . В этом разделе мы рассмотрим две основные стратегии ветвления.
5.1. Длинные ветки
Эта стратегия используется, когда мы хотим поддерживать единую версию нашего программного обеспечения одновременно . То есть, когда мы предлагаем последнюю версию нашего программного обеспечения как доступную, вместо того, чтобы иметь много версий (которые все еще могут быть доступны, но считаются старыми или не поддерживаемыми).
Ключом этой стратегии является наличие ветки только для стабильных версий, где отмечены выпуски, для которых используется ветвь по умолчанию, master ; и наличие других ветвей для разработки, где функции разрабатываются, тестируются и интегрируются.
В этой стратегии master ветвь является производственной, поэтому здесь должны быть только проверенные, должным образом интегрированные, окончательные версии. Либо также могут быть версии в стадии разработки или не полностью протестированные, но они должны быть правильно помечены .
На следующем графике показан пример истории репозитория, следующей этой стратегии:
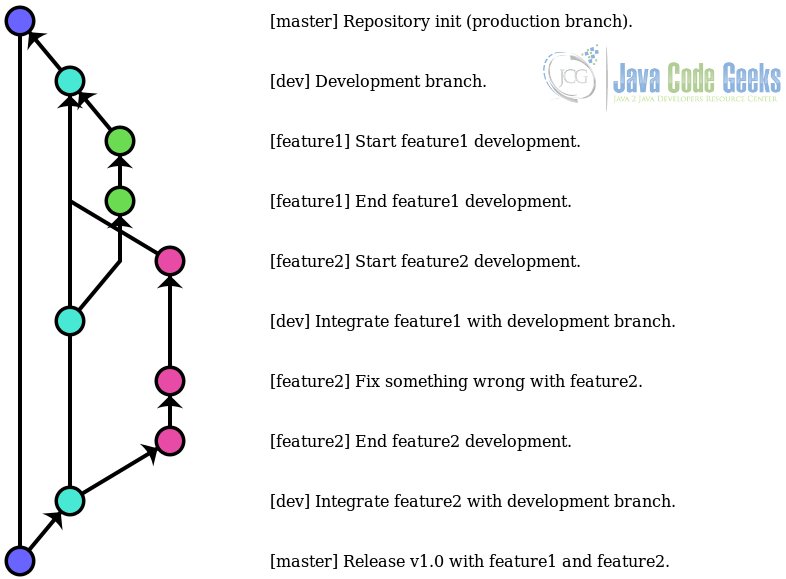
9. Пример истории хранилища с использованием долгосрочной стратегии ветвей.
Просто и понятно. Состояние производства изменяется только для тех изменений, которые были интегрированы с веткой разработки, где ничего не происходит, если что-то ломается. Изменения, которые должны быть сделаны для каждой функции, полностью изолированы, способствуя разделению задач среди товарищей по команде.
5.2. Одна версия, одна ветка
Этот рабочий процесс предназначен для создания программного обеспечения, которое будет доступно и поддерживается для нескольких версий . Другими словами, релиз не «перезаписывает» все предыдущие выпуски, он «перезаписывает» только выпуск той ветки, для которой он был создан.
Чтобы достичь этого, каждая поддерживаемая версия должна иметь свою основную версию, но с общим путем разработки для всех из них.
Это делается с помощью ветви для каждой версии (обычно называемой PROJECT_NAME_XX_STABLE или аналогичной) для стабильного выпуска, «master» каждой версии; и наличие основной ветви (и ее дочерних ветвей), где осуществляется разработка, для которой может использоваться основная ветвь по умолчанию. Когда каждая функция разработана и протестирована, master ветвь может быть объединена с любой требуемой стабильной версией.
Эта стратегия ветвления основана на долгосрочной перспективе, но, в данном случае, имеет много «мастеров» вместо одного.
Примите во внимание, что каждая функция должна быть протестирована с каждой версией проекта, к которому мы хотим применить эту функцию. Подумайте об использовании непрерывной интеграции при работе с этой стратегией.
Давайте рассмотрим пример графика истории, для которой была применена эта стратегия.
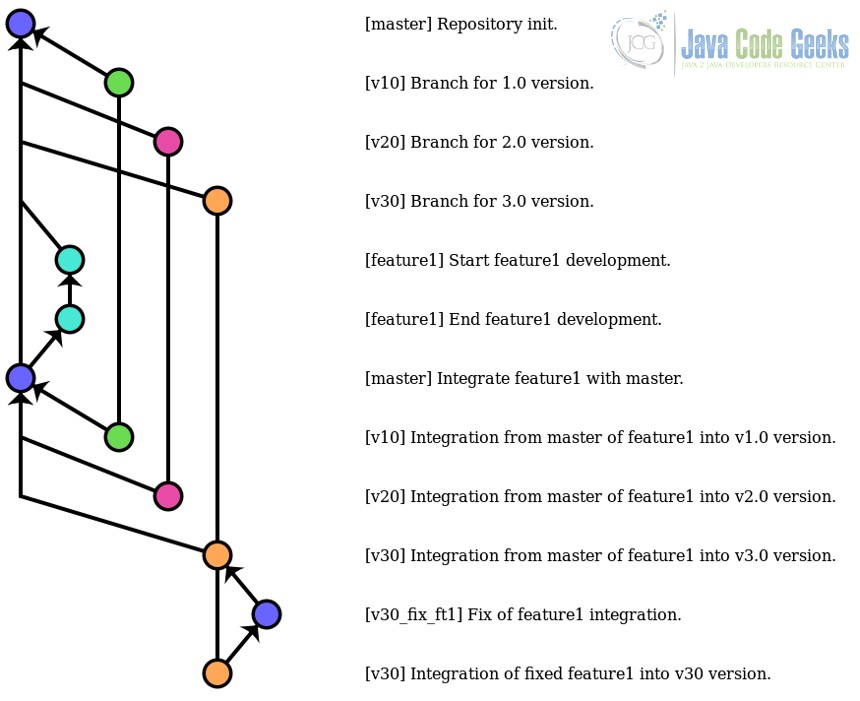
10. Пример истории репозитория с использованием одной версии, одной стратегии ветвления.
Как мы видим, здесь ветка master используется как основная ветка разработки.
В версии v3.0 мы смоделировали ошибку для feature1 . Это не обязательно должна быть ошибка, появившаяся во время интеграции, это может быть ошибка, обнаруженная позже. В любом случае, мы уверены, что ошибка feature1 существует только для версии v3.0. В этих случаях мы не должны исправлять эти ошибки в master ветке, потому что это не то, что влияет на все версии. Мы должны создать ветку из уязвимой версии, исправить ошибку и выполнить слияние с конкретной веткой. И, если в будущем такая же ошибка не исчезнет для новых выпусков, мы можем рассмотреть возможность объединения ее с master .
Основным преимуществом этой стратегии является то, что общие функции следуют общему пути, и конкретные изменения могут быть полностью изолированы для уязвимых версий.
5.3. Независимо от стратегии ветвления: одна ветвь для каждой ошибки
Независимо от стратегии ветвления, которую вы используете, рекомендуется создавать независимую ветвь для каждой ошибки, так же, как об этом сообщалось в вашем трекере ошибок (потому что вы используете систему отслеживания ошибок, верно?). На самом деле, мы видели эту практику в предыдущем примере, при интеграции функции в ветку для версии v3.0. Наличие независимой ветки для каждой ошибки позволяет идеально локализовать и идентифицировать проблемы, а исправленные изменения связаны с другими .
Идентификация этой ветви с помощью номера идентификатора, сгенерированного системой отслеживания ошибок для данной ошибки, с присвоением имен веткам, например, как issue-X , позволяет отслеживать изменения, внесенные для исправления этой ошибки, в комментарии, сделанные в соответствующий тикет отслеживания ошибок, который действительно полезен, так как вы можете объяснить возможные решения для ошибок, прикрепить изображения и т. д.
6. Удаленные репозитории
Git, как мы видели во введении, является распределенной VCS. Это означает, что, помимо локального, у нас может быть копия репозитория, размещенная на удаленном сервере, которая, помимо публикации исходного кода проекта, используется для совместной разработки.
Наиболее популярной платформой для размещения Git-репозиториев является GitHub . К сожалению, GitHub не предлагает частные репозитории в своем бесплатном плане. Если вам нужна хостинговая платформа с неограниченным количеством частных репозиториев, вы можете использовать Bitbucket . И, если вы ищете размещение своих репозиториев на своем собственном сервере, доступным вариантом будет GitLab .
Для этого раздела нам нужно будет использовать один из вариантов, упомянутых выше.
6.1. Запись изменений в пульт
Первое, что нам нужно сделать на удаленном хостинге, — это создать репозиторий, для которого будет создан URL в следующем формате:
|
1
|
https://hosting-service.com/username/repository-name |
Имея удаленный репозиторий, мы должны связать его с нашим локальным репозиторием. Это делается с помощью команды remote add <remote-name> <repo-url> :
|
1
|
git remote add origin https://hosting-service.com/username/repository-name |
origin — это имя, которое Git по умолчанию называет аналогично master ветке, но это необязательно.
Теперь в нашем локальном репозитории удаленный репозиторий идентифицирован как origin . Теперь мы можем начать «отправлять» на него информацию, что делается с помощью функции push :
|
1
|
git push [remote-name] [branch-name | --all] [--tags] |
Давайте посмотрим несколько примеров того, как это работает:
|
1
2
3
|
git push origin --all # Updates the remote with all the local branchesgit push origin master dev # Updates remote's mater and dev branchesgit push origin --tags # Sends tags to remotes |
Это пример вывода успешного обновления главной ветки:
|
1
2
3
4
5
|
Counting objects: 3, done.Writing objects: 100% (3/3), 235 bytes | 0 bytes/s, done.Total 3 (delta 0), reused 0 (delta 0)To https://hosting-service.com/username/repository-name.git * [new branch] master -> master |
Что Git внутренне с этим?
Итак, теперь был создан каталог .git/refs/remotes , а внутри него — другой каталог origin (потому что это имя мы дали удаленному). Здесь Git создает файл для каждой ветви, выходящей из удаленного репозитория, со ссылкой на него. Эта ссылка является просто идентификатором SHA1 последнего коммита данной ветви удаленного репозитория . Это используется Git, чтобы знать, есть ли в удаленном репо какие-либо изменения, которые можно применить к локальному репозиторию. Мы рассмотрим это подробно позже в следующих разделах.
Примечание : в репозитории может быть столько пультов, сколько мы хотим. Например, у нас может быть пульт одного и того же хранилища в GitHub и Bitbucket:
|
1
2
|
git remote add github https://github.com/username/repository-namegit remote add bitbucket https://bitbucket.org/username/repository-name |
6.2. Клонирование репозитория
Клонирование репозитория фактически производится один раз, когда мы собираемся начать работу с удаленным репозиторием.
Для клонирования удаленных репозиториев нет ничего загадочного, мы просто должны использовать опцию clone , указав URL-адрес репозитория:
|
1
|
git clone https://hosting-service.com/username/repository-name |
Который будет создавать локальный каталог с хранилищем, со ссылкой на удаленный, из которого он был клонирован.
По умолчанию при клонировании репозитория создается только ветвь по умолчанию (обычно master ). Способ создать другие филиалы локально — оформить заказ.
Удаленные ветви могут быть показаны с параметром branch с флагом -r :
|
1
|
git branch -r |
Они будут показаны в формате <remote-name>/<branch-name> . Чтобы создать локальную ветку, достаточно оформить заказ на <branch-name> .
6.3. Обновление удаленных ссылок: выборка
Извлечение удаленного репозитория означает обновление ссылки на локальную ветку, чтобы поместить ее даже в удаленную ветку .
Давайте рассмотрим совместный сценарий, в котором два разработчика вносят изменения в один репозиторий. В какой-то момент один из разработчиков хочет обновить свою ссылку на master до последнего нажатия другого разработчика, как показано на следующем рисунке.
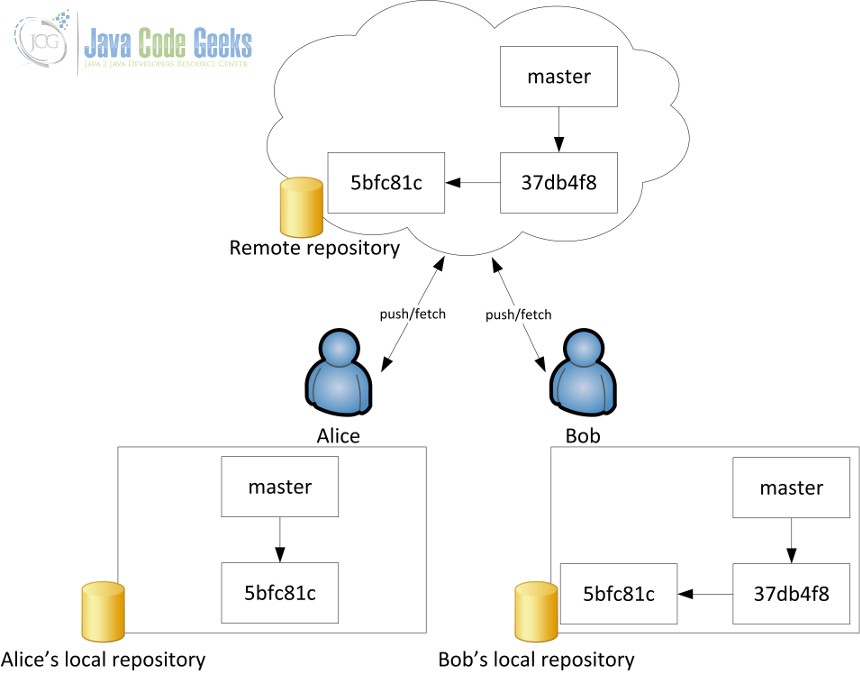
11. Совместная разработка с удаленным репозиторием.
Содержимое файла .git/refs/remotes/origin/master хранилища Алисы перед любым обновлением будет следующим:
|
1
|
5bfc81ce5f7a0b26b493be0c99f1966a1896c972 |
Боб, однако, будет обновлен, поскольку именно он последний обновил удаленный репозиторий:
|
1
|
37db4f82e346665f6048cc9e4b7cd48c83c6ebcb |
Теперь Алиса хочет иметь в своем локальном хранилище изменения, сделанные Бобом. Для этого она должна fetch ветку master :
|
1
|
git fetch origin master |
(В качестве альтернативы она может выбрать каждую ветку с флагом --all ):
|
1
|
git fetch --all |
Вывод fetch будет выглядеть примерно так:
|
1
2
3
4
5
6
|
remote: Counting objects: 3, done.remote: Total 3 (delta 0), reused 0 (delta 0)Unpacking objects: 100% (3/3), done.From https://hosting-service.com/alice/repository-name * branch master -> FETCH_HEAD 5bfc81c..37db4f8 master -> origin/master |
И теперь содержимое файла Алисы .git/refs/remotes/origin/master будет таким же, как и у remote:
|
1
|
37db4f82e346665f6048cc9e4b7cd48c83c6ebcb |
Благодаря этому Алиса обновила ссылку на master ветку удаленного компьютера, но изменения не были применены в хранилище .
fetch не применяет изменения напрямую к локальному хранилищу. Это первый из двух шагов, которые должны быть сделаны. Другой шаг — объединить удаленную ветку, которая только что была обновлена; с местным отделением . Это просто слияние, как и любое другое, но где должно быть указано удаленное имя:
|
1
|
git merge origin/master |
После завершения слияния Алиса получит последнюю версию master ветки.
Примечание : в этом слиянии мы не применили ускоренную перемотку вперед. В этом случае не было бы много смысла применять его, так как мы объединяем по сути одну и ту же ветку, но она находится где-то еще.
6.4. Получение и объединение пультов одновременно: вытягивание
Git имеет возможность применять удаленные изменения сразу, то есть извлекать и объединять ветки в одной команде. Эта опция — pull .
Учитывая тот же сценарий, который мы видели выше, мы могли бы просто выполнить:
|
1
|
git pull origin master |
И будет делать выборку, а затем слияние.
Используйте способ, которым вы чувствовали себя более комфортно. Там нет лучшего способа; на самом деле они делают то же самое, но выражаются по-разному.
6,5. Конфликты при обновлении удаленного репозитория
Вернемся к сценарию, показанному выше. Что произойдет, если без обновления своего локального репозитория Алиса создаст коммит и отправит его в удаленный репозиторий? Ну, она получит ужасное сообщение от Git:
|
1
2
3
4
5
6
7
|
! [rejected] master -> master (fetch first)error: failed to push some refs to 'https://hosting-service.com/alice/repository-name.git'hint: Updates were rejected because the remote contains work that you dohint: not have locally. This is usually caused by another repository pushinghint: to the same ref. You may want to first integrate the remote changeshint: (e.g., 'git pull ...') before pushing again.hint: See the 'Note about fast-forwards' in 'git push --help' for details. |
Подтверждение будет отклонено, поскольку Алиса не продолжила историю хранилища с точки, которая уже была зарегистрирована на удаленном компьютере . Таким образом, перед записью изменений в удаленном репозитории ей нужно будет сначала извлечь и объединить или вытащить пульт с изменениями.
6.5.1. Плохой способ разрешения конфликтов
Есть еще один способ, который нельзя точно считать решающим . О форсировании толчков с флагом --force .
Форсирование push — это, по сути, одно: перезаписать ветку удаленного репозитория (или весь репозиторий) той, которую вы толкаете. Таким образом, в приведенном выше сценарии, если Алиса 37db4f8 свой репозиторий, коммит 37db4f8 исчезнет. В результате Боб будет работать в чем-то похожем на «параллельную вселенную», которая не может сосуществовать с текущей реальностью проекта , поскольку его работа основана на состоянии, которого больше нет в проекте.
В заключение, не форсируйте толчки, когда вы работаете с другими разработчиками , по крайней мере, если вы не хотите иметь с ними интенсивные споры.
Если вы воспользуетесь Google для «git force push» в разделе изображений, вы увидите несколько мемов, которые наглядно объясняют, что такое принудительный толчок.
6.6. Удаление вещей в удаленном хранилище
Как и в случае с принудительными изменениями, вещи в удаленных репозиториях должны быть удалены с особой осторожностью. Прежде чем удалять что-либо, каждый сотрудник должен быть проинформирован об этом .
На самом деле, когда мы отправляем коммиты, ветки и т. Д., Мы отправляем их в пункт назначения ref, но нам не нужно явно указывать пункт назначения.
Явный синтаксис следующий:
|
1
|
git push origin <source>:<destination> |
Таким образом, способ удаления удаленных объектов заключается в обновлении ссылок до предыдущих состояний или нажатии «ничего».
Давайте посмотрим, как это сделать для каждого случая.
6.6.1. Удаление коммитов
Это то же самое, что локальное удаление коммитов, например, удаление двух последних коммитов:
|
1
|
git push origin HEAD~2:master --force |
Если мы используем HEADссылки для удаления коммитов, мы должны убедиться, что они расположены в той же ветке, что и удаленная.
Обратите внимание, что эти толчки тоже должны быть принудительными.
6.6.2. Удаление веток
Это довольно просто, это просто толкание «ничего», как было сказано ранее. Следующее удалит devветку из удаленного репозитория:
|
1
|
git push origin :dev |
Удаленные ветви должны быть удалены при удалении локальной ветви .
6.6.3. Удаление тегов
Как и в случае с ветками, мы должны нажимать «ничего», например:
|
1
|
git push origin --tags :v1.0 |
7. Патчи
Вы, вероятно, когда-либо видели обновление программного обеспечения с помощью патча . Патч — это просто файл, который описывает изменения, которые должны быть внесены в программу, указывая, какие строки кода необходимо удалить, а какие добавить. В Git путь — это просто вывод diffсохраненного в файл.
Примите во внимание, что патч является обновлением, но обновление не обязательно должно быть патчем. Патчи предназначены для исправлений или критических функций, которые необходимо исправить или реализовать прямо сейчас , а не для того, чтобы быть общей стратегией обновления и развертывания.
7.1. Создание патчей
Как уже говорилось, патч для Git — это просто вывод diff. Таким образом, мы должны перенаправить этот вывод в файл:
|
1
|
git diff <expression> > <patch-name>.patch # The extension is not important. |
Например:
|
1
|
git diff master..issue-1 > issue-1-fix.patch |
Примечание : патч нельзя изменить. Если файл патча подвергается какой-либо модификации, Git помечает его как поврежденный и не применяет его.
7.2. Применение патчей
Патчи применяются с applyкомандой. Это так же просто, как указать путь к файлу пути:
|
1
|
git apply <patch-file> |
Если исправление прошло успешно, сообщение не будет отображаться (если вы не использовали --verboseфлаг). Если исправление не применимо, Git покажет, какие файлы вызывают проблемы.
Часто встречаются ошибки из-за различий в пробелах. Эти ошибки можно игнорировать с помощью --ignore-space-changeи --ignore-whitespaceфлагов.
8. Сбор вишни
Могут быть некоторые сценарии, когда мы заинтересованы в портировании в ветку только определенного набора изменений, сделанных в другой ветке, вместо того, чтобы объединять его.
Чтобы сделать это, Git позволяет черри выбирать коммиты из веток с помощью cherry-pickкоманды. Механизм аналогичен слиянию, но в этом случае указывается идентификатор SHA1 коммита, например:
|
1
|
git cherry-pick -x aba6c1b # Several commits can be cherry picked. |
Выбор вишни создает новый коммит с тем же сообщением, что и у оригинала. -xОпция для добавления к тому , что сообщение фиксации линия , указывающая , что является вишневым выбором, и из которого фиксации была выбрана:
(вишня выбрана из коммита aba6c1bf9a0a7d6d9ccceeab2b5dfc64f6c115c2)
Сбор вишни не должен быть повторяющейся практикой в вашем рабочем процессе, поскольку он не оставляет следа в истории , а представляет собой строку, указывающую, откуда он был выбран.
9. Крючки
Git-хуки — это пользовательские скрипты, которые запускаются, когда происходят важные события , например, коммит или слияние.
Допустим, вы хотите уведомить кого-либо по электронной почте об обновлении вашей производственной ветви или запустить тестовый набор; но в автоматическом режиме. Крючки могут сделать это для вас.
Скрипты находятся в .git/hooksкаталоге. По умолчанию предоставляются некоторые примеры хуков. У каждого крючка должно быть конкретное имя, которое мы увидим позже, без расширения; и должен быть помечен как исполняемый. Вы можете использовать другие языки сценариев, такие как PHP или Python, кроме шелл-кода.
Существует два вида хуков: на стороне клиента и на стороне сервера.
9.1. Клиентские крючки
Хуки на стороне клиента — это те, которые запускаются, когда локальный репозиторий претерпевает изменения. Это наиболее распространенные:
-
pre-commit: вызываетсяgit commitкомандой до сохранения коммита. Коммит может быть прерван с этим хуком, выходящим с ненулевым статусом. -
post-commit: вызываетсяgit commitтоже, но на этот раз, когда коммит был сохранен. На этом этапе фиксация не может быть прервана. -
post-merge: так же, как сpost-commit, но будучи этим уволенgit merge. -
pre-push: срабатываетgit pushдо того, как удаленный объект будет передан.
Следующий скрипт показывает пример, применимый для обоих post-commitи post-commitловушек, в целях уведомления:
|
1
2
3
4
5
6
7
8
|
#!/bin/shbranch=$(git rev-parse --abbrev-ref HEAD)if [ "$branch" = "master" ]; then echo "Notifying release to everyone..." # Send the notification...fi |
Чтобы использовать его в обоих случаях, вам нужно создать оба хука.
9.2. Крюки на стороне сервера
Эти хуки находятся на сервере, где размещен удаленный репозиторий. Очевидно, что если вы используете такие сервисы, как GitHub, для размещения своих репозиториев, вам не разрешат выполнять произвольный код. В случае GitHub у вас есть доступные сторонние сервисы, но вы никогда не подключитесь к своему коду. Для использования вашего кода вам понадобится собственный сервер для хостинга.
Наиболее используемые крючки:
-
pre-receive: это срабатывает после того, как кто-то делает push, и до того, как ссылки обновляются в удаленном режиме. Таким образом, с этим крюком, вы можете отрицать любой толчок. -
update: почти точно к предыдущему, но это выполняется для каждой отправленной ссылки. То есть, если было выдвинуто 5 ссылок, этот хук будет выполнен 5 раз, в отличие от тогоpre-receive, который выполняется для толчка в целом. -
post-receive: этот выполняется после того, как отправка прошла успешно, поэтому его можно использовать и в целях уведомления.
9.3. Крючки не входят в историю
Хуки существуют только в локальном хранилище. Если вы создадите push-репозиторий с пользовательскими хуками, они не будут отправлены на удаленный компьютер. Таким образом, если каждый разработчик должен использовать одни и те же хуки, они должны быть включены в рабочий каталог и устанавливать их вручную.
10. Подход к непрерывной интеграции
Непрерывная интеграция (CI) — это практика разработки программного обеспечения, тесно связанная с управлением версиями, и о ней стоит упомянуть, по крайней мере, концептуально.
CI состоит в создании нескольких интеграций кода (по крайней мере, один раз в день) полностью автоматизированным способом с целью выявления ошибок на ранних этапах разработки .
Концепция почти такая же, как и у хуков, но гораздо более масштабируемая и удобная в обслуживании .
Вот некоторые из действий, которые выполняются в каждой интеграции:
- Выполнение теста: юнит, приемка, интеграция, регрессия, а также большое и т. Д.
- Обеспечение качества, с проверкой метрик программного обеспечения: цикломатическая сложность, охват кода и другие большие и т. Д.
- Проверка соответствия стандарту кодирования программного обеспечения.
Непрерывная интеграция позволяет выполнять эти действия, и более того, автоматически, без необходимости выполнять его вручную, просто нажатием или фиксацией . Интересно, не правда ли?
Вероятно, наиболее используемые параметры CI следующие:
- Travis CI: облачный, который позволяет запускать интеграции с толчками, без необходимости иметь свой собственный сервер.
- Jenkins: хостинг, для которого нужен сервер, но который полностью настраивается. Совместим со многими инструментами сборки, такими как Ant, Gradle, Maven, Phing, Grunt…
11. Заключение
Системы контроля версий помогают исполнить мечту каждого разработчика: определив каждую точку всей истории проекта, можно вернуться к любой точке в любое время. VCS, которую мы видели в этом руководстве, — Git, предпочитаемый сообществом разработчиков программного обеспечения.
После прочтения этого руководства, если вы впервые работаете с Git, вы, вероятно, подумаете, как бы вы не жили без Git до сегодняшнего дня.
12. Ресурсы
Лучший возможный ресурс — это Pro Git (2-е издание) Скотта Чакона и Бена Штрауба, который охватывает почти все темы о Git. Вы можете прочитать его бесплатно на официальной странице Git .