OptaPlanner наконец-то поддерживает многопоточное пошаговое решение . Ускорение впечатляет. Даже с несколькими ядрами процессора, он в три раза быстрее вычисляет счет. Смотрите результаты ниже. Для его активации достаточно одной дополнительной строки в конфигурации.
Первоначальный запрос на функциональность был сделан в 2007 году. На протяжении многих лет мы шаг за шагом усердно готовили для него внутреннюю архитектуру. Так что теперь, спустя 10 лет, мы полностью поддерживаем его с 7.9.0.Final . 7.9.0.Final .
Но почему это заняло так много времени?
Требования
Давайте посмотрим на требования для многопоточного пошагового решения:
- Горизонтальное масштабирование алгоритма между процессорами.
- Не нарушайте ускорение расчета дополнительных очков.
- Прогоны должны быть воспроизводимыми.
Горизонтальное масштабирование алгоритма между процессорами
Есть несколько способов использовать несколько потоков без реального многопоточного решения:
- Многопрофильность : решение нескольких наборов данных, по одному на поток.
- Работает с первой версии OptaPlanner.
- Не делает горизонтальное масштабирование на 1 наборе данных.
- Решение нескольких ставок : решить один набор данных несколькими способами, полностью независимо друг от друга. Возьми лучший результат.
- Работает с первой версии OptaPlanner.
- Обычно это пустая трата ресурсов: используйте Benchmarker во время разработки, чтобы заранее найти лучший алгоритм.
- Не масштабируется по горизонтали: лучший результат незначительно лучше однопоточного и занимает столько же времени.
- Поиск по разделам : разделите один набор данных и решите каждый отдельно.
- Полностью поддерживается начиная с OptaPlanner 7.0.
- Горизонтальное масштабирование при дорогостоящем компромиссе качества решения, поскольку разбиение исключает оптимальные решения .
Но ни одна из них не является реальной параллельной эвристикой, как показано в правом нижнем углу ниже:
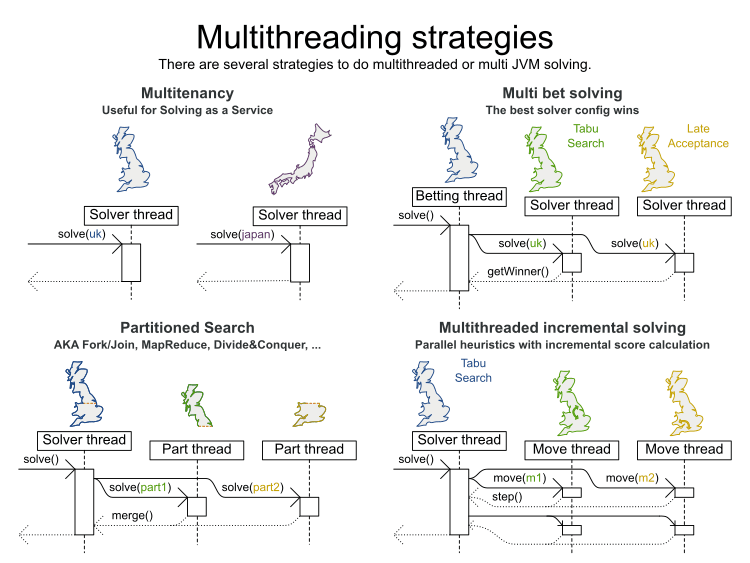
В реальном многопоточном решении мы решаем 1 набор данных без разбиения путем разгрузки тяжелых вычислений 1 алгоритма (который может представлять собой совокупность нескольких алгоритмов) в несколько потоков на отдельных ядрах ЦП.
В строительной эвристике и локальном поиске OptaPlanner самая дорогостоящая работа процессора — это подсчет очков за ход. Например, в Tabu Search каждый шаг (внешняя итерация) оценивается в 1000 ходов. Это измеряется как скорость расчета баллов . Обычно она варьируется между 1 000 оцененных ходов в секунду и 500 000 оцененных ходов в секунду.
Многопоточное решение — это просто вопрос распределения оценок шага по нескольким потокам. Это просто. Есть даже несколько пользователей, которые сделали это (особенно поставщик космического агентства), взломав наш код. Но они не увидели прироста производительности. Совсем наоборот (за исключением простого калькулятора). Эти изменения нарушили расчет дополнительных баллов. Многопоточное решение легко. Но многопоточное пошаговое решение — это сложно.
Не нарушайте ускорение расчета дополнительных очков
Ах, это подводит нас к инкрементальному подсчету баллов. Ключ к производительности. Именно ракетостроение в основе OptaPlanner обеспечивает огромную масштабируемость. И — для немногих, кто их видел — причина пресловутого исключения из коррупции.
Что такое расчет дополнительных баллов? Для каждого хода мы вычисляем оценку состояния решения после применения этого хода. При неинкрементном вычислении баллов весь балл рассчитывается с нуля. Но при вычислении добавочной оценки мы вычисляем только дельту, как показано ниже. Это гораздо эффективнее.

Чтобы представить это в перспективе: калькулятор инкрементной оценки для задачи о маршруте транспортного средства с 1000 местоположениями теоретически примерно в 500 раз быстрее, чем калькулятор без инкрементной оценки. Чтобы компенсировать потерю инкрементного решателя в наборе данных из 1000 объектов планирования, многопоточному неинкрементному решателю потребуется около 500 ядер ЦП (теоретически). На практике числа различаются, но выигрыш от пошагового решения всегда перевешивает выигрыш от многопоточного решения.
Конечно, теперь мы можем съесть наш пирог и съесть его тоже.
Каждый калькулятор добавочных баллов по своей природе является однопоточным, поэтому у каждого потока перемещения есть свой калькулятор баллов и собственное состояние решения. Клонирование либо слишком дорого. Чтобы оценить ход в потоке ходов, с вычислением добавочной оценки, мы должны повторно использовать калькулятор оценок предыдущей оценки. Это подразумевает, что для начала рабочее решение должно быть в точно таком же состоянии. Но поскольку итерации внешнего шага постоянно изменяют состояние решения, потоки перемещения должны синхронизироваться с основным потоком решателя после каждого шага.
Это похоже на любую многопользовательскую игру в реальном времени (например, StarCraft), в которой несколько хостов должны синхронизироваться, чтобы показать одно и то же игровое состояние, но не могут позволить передавать все игровое состояние для каждого изменения.
Как только один поток не синхронизируется, все вычисления этого потока будут повреждены, и вся система будет затронута. Но с помощью хорошо спроектированной комбинации одновременных компонентов (и многодневных тестовых прогонов) мы предотвращаем гонки. И это работает. Как магия.
Кроме того, потоки должны иметь возможность отправлять ходы друг другу, даже если это только для того, чтобы делиться выигрышным ходом. Это тоже представляло собой проблему. OptaPlanner — это объектно-ориентированный решатель ограничений , поэтому его переменными решения могут быть любые допустимые типы Java (не только логические, числа и числа с плавающей запятой), например Employee или Foo . Эти переменные могут находиться в любом классе домена (называемом объектами планирования), например, Shift или Bar . Экземпляры перемещения ссылаются на эти экземпляры класса. Когда решение клонируется для инициирования потока перемещения, клонируются и такие объекты планирования, как Shift . Таким образом, когда перемещение из потока A отправляется в поток B, OptaPlanner отменяет перемещение в состоянии решения потока B. Это заменяет ссылки из экземпляра перемещения на состояние решения потока A эквивалентными ссылками на состояние решения потока B. Довольно изящно.
Прогоны должны быть воспроизводимыми
Воспроизводимость является королем. Возможность дважды запускать один и тот же набор данных через OptaPlanner и получать одинаковый результат после одинакового количества шагов (и на каждом шаге) на вес золота. Потерять это очень затруднило бы отладку, отслеживание проблем и производственный аудит.
Непредсказуемая природа порядка выполнения потоков на многоядерных компьютерах делает воспроизводимость интересным требованием. Объедините это с опорой многих алгоритмов оптимизации на генератор случайных чисел (который не является поточно-ориентированным) для реальной задачи.
Но мы сделали это. У нас 100% воспроизводимость. Это включает в себя несколько гениальных механизмов, таких как использование отобранных мастером случайных чисел для генерации отобранных случайных чисел на поток, генерация предсказуемого количества выбранных буферизованных ходов (поскольку генерация ходов часто зависит и от генератора случайных чисел) и переупорядочивание оцененных ходов в их первоначально выбранных порядок, когда они возвращаются с ходу темы.
Конфигурация
Многопоточное пошаговое решение легко активировать. Просто добавьте <moveThreadCount> в конфигурацию вашего решателя:
|
1
2
3
4
|
<solver> <moveThreadCount>4</moveThreadCount> ...</solver> |
Это в основном жертвует 4 дополнительных ядра процессора. Используйте AUTO для автоматического вывода OptaPlanner. При желании укажите <threadFactoryClass> для сред, которым не нравится создание произвольных потоков.
Он объединяется с любой другой функцией, включая другие стратегии многопоточности (например, многопользовательская работа, секционированный поиск и т. Д.), Если у вас достаточно ядер ЦП, чтобы справиться с этим.
Тесты
методология
Используя optaplanner-benchmark, я запустил набор макро-тестов:
- На 64-разрядном 8- ядерном рабочем столе Intel i7-4790 с 32 ГБ физической оперативной памяти.
- Использование OpenJDK 1.8.0_171 в Linux.
- Если максимальная куча JVM (
-Xmx) установлена в 4 ГБ.- Я также попробовал 2 ГБ, и эти результаты были хуже, особенно для большего количества потоков перемещения.
- Поэтому при увеличении количества перемещаемых потоков важно также увеличить максимальное количество памяти.
- При ведении журнала установлено
infoведение журнала.- Я также пробовал вести журнал
debugи эти результаты были явно хуже (потому что чем быстрее он работает, тем больше он делает отладки). - В любом случае, рекомендуется избегать отладочной регистрации в производственной среде.
- Я также пробовал вести журнал
- С оценкой ДХО.
- Я также попробовал использовать инкрементный калькулятор Java, и эти результаты имели больше ходов в секунду, но более низкий относительный выигрыш на поток ходов (из-за более высокой загруженности).
- 5 минут на набор данных.
Результаты по проблеме маршрутизации транспортных средств (VRP)
Ниже приведены результаты для различных наборов данных VRP для уменьшения первой подгонки (эвристика построения), за которым следует поиск по табу (локальный поиск). Чем выше, тем лучше.
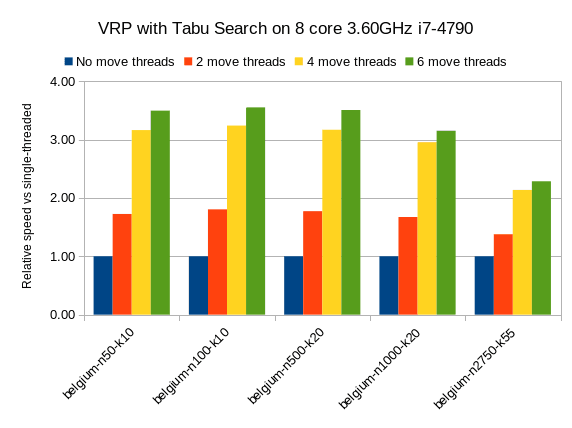
Синяя полоса — это традиционный однопоточный OptaPlanner. Он имеет среднюю скорость расчета 26,947 ходов в секунду. Это до 45,565 с 2 45,565 , до 80,757 с 4 88,410 и до 88,410 с 6 88,410 .
Таким образом, пожертвовав больше процессорных ядер OptaPlanner, он использует долю времени для достижения того же результата.
На других алгоритмах локального поиска, таких как Late Acceptance, мы видим похожие результаты:
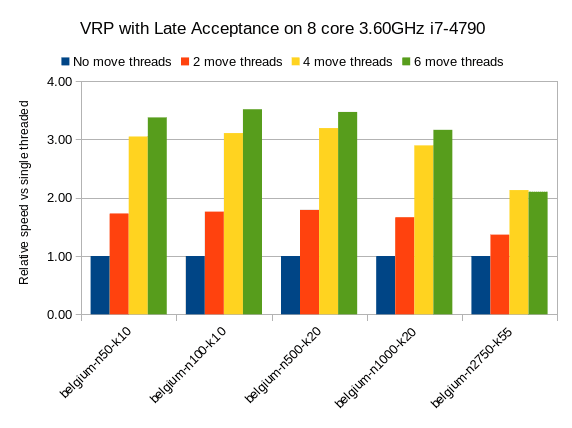
Позднее принятие — это быстрый алгоритм пошагового выполнения (особенно в начале), который подразумевает, что у него меньше ходов на шаг. Тем не менее, он имеет аналогичное относительное увеличение скорости для проблемы маршрутизации транспортного средства.
Мы также видим небольшое уменьшение относительного прироста скорости в самом большом наборе данных с 2750 местоположениями VRP, но я подозреваю, что это может быть связано с тем, что максимальная кучная память 4 ГБ слишком мала, чтобы она могла функционировать с полной эффективностью. Я буду исследовать это дальше.
Результаты по составлению списков медсестер
Я также провел тесты для случая использования медсестры, но с максимальной кучей JVM ( -Xmx ), установленной на 2 ГБ. Здесь я попробовал Табу Поиск, Имитация отжига и Позднее принятие:
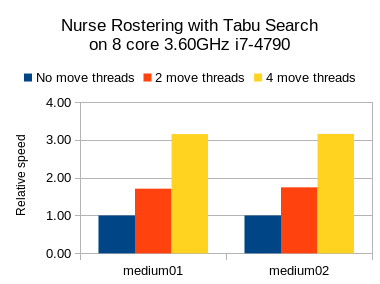
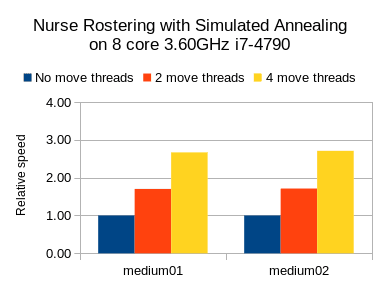
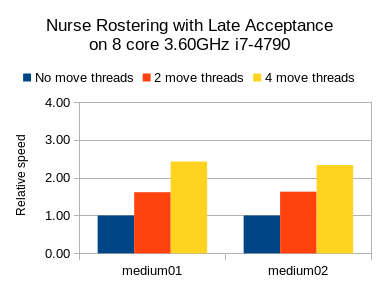
Во всех трех случаях мы видим желаемое увеличение скорости, но поиск Tabu (алгоритмы медленного шагания) имеет больший относительный выигрыш, чем другие (которые являются алгоритмами быстрого шагания).
В любом случае ясно, что ваш пробег может варьироваться в зависимости от варианта использования и других факторов.
Будущие улучшения
По мере того как мы увеличиваем количество потоков перемещений или уменьшаем время для оценки одного перемещения в одном потоке, мы видим более высокую загруженность в очередях связи между потоками, что приводит к более низкому относительному выигрышу в масштабируемости. Есть несколько способов справиться с этим, и мы будем исследовать такие внутренние улучшения в будущем.
Вывод
Все ваши процессоры принадлежат OptaPlanner. [1]
С помощью одной дополнительной линии конфигурации, OptaPlanner может достичь того же высококачественного решения в кратчайшие сроки. Если у вас есть запасные ядра процессора, конечно.
| Смотрите оригинальную статью здесь: гигантский скачок вперед с многопоточным пошаговым решением
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |