Два типа структуры
Историк Бенедикт Андерсон однажды написал, что «все сообщества, более крупные, чем исконные деревни непосредственного контакта … воображаются».
В некотором смысле, и классовые зависимости, и пакетные зависимости тоже воображаются. Их на самом деле нет. И все же мы тратим огромные энергии на управление ими. Что побуждает нас бороться с галлюцинаторными монстрами?
Ну, основное предположение этого блога состоит в том, что структура исходного кода имеет значение из-за денег. В частности, плохо структурированное программное обеспечение сильно страдает от волновых эффектов, в результате чего изменение кода в одном месте вызывает изменения во многих других, что увеличивает затраты на обновление. Более того, плохо структурированное программное обеспечение настолько запутано, что даже прогнозировать стоимость обновления сложно, потому что эти волновые эффекты распространяются повсюду.
Например, на рисунке 1 слева показана хорошая структура пакета, где четкие зависимости делают анализ затрат на обновление беспроблемным, а справа — нечестивую рутину структуры пакета.
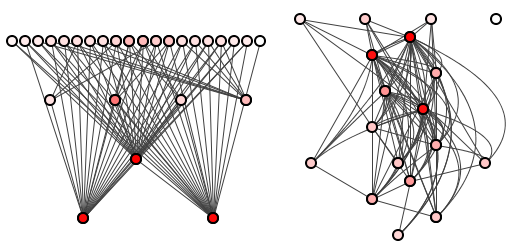
Рисунок 1: Две системы, две структуры пакета.
Если мы хотим изучить потенциальные волновые эффекты этих образцов, мы должны понять, как волновые эффекты вспыхивают от одного места до другого. Рассмотрим цепочку методов Java следующим образом: a () вызывает b () , b (), вызывает c () и т. Д.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
private int a(int value) { return b(value) * 2; } private int b(int value) { return c(value) * 3; } private int c(int value) { return d(value) * 5; } private int d(int value) { int startValue = 7; return value - startValue; } |
Эффект ряби возникает, когда кто-то решает изменить startValue на 13,5, удваивается , и решает, что эта точность должна быть сохранена, что требует обновления a () , b () и c () с int s до удвоенного s.
|
1
2
3
4
|
private double d(double value) { double startValue = 13.5; return value - startValue; } |
Программисты избегают длительных переходных зависимостей, потому что у них есть больше методов для любого случайного изменения, к которому можно вернуться.
Старые новости. Trivial. Здесь ничего нет.
Меняется ли это, однако, когда мы исследуем зависимости классов? Давайте прижмем a () и b () в один класс, а c () и d () — в другой, сохранив транзитивную зависимость на уровне метода: a () -> b () -> c () -> d () ,
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
class Here { There there = new There(); private int a(int value) { return b(value) * 2; } private int b(int value) { return there.c(value) * 3; } } class There { int c(int value) { return d(value) * 5; } private int d(int value) { int startValue = 7; return value - startValue; } } |
Опять же, учтите, что d () изменяется, вызывая обновления во всех остальных. Отличается ли этот пример от предыдущего?
Мы знаем, что длина транзитивной зависимости является врагом, и в этом втором примере на уровне класса мы имеем более короткую транзитивную зависимость всего из двух классов. Так менее ли вероятны волновые эффекты среди этих двух классов, чем среди четырех методов первого примера?
Нет, они не. Потому что четыре метода все еще там. Вероятность волновых эффектов по этим четырем методам остается неизменной. ( МакБейн- голос) «Классы ничего не делают!»
Что из пакета зависимостей? Давайте обернем этих щенков в отдельные пакеты: поможет ли это снизить потенциальную стоимость волновых эффектов?
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
package x; class Here { There there = new There(); private int a(int value) { return b(value) * 2; } private int b(int value) { return there.c(value) * 3; } } package y; public class There { public int c(int value) { return d(value) * 5; } private int d(int value) { int startValue = 7; return value - startValue; } } |
Вы видите, куда это идет. Несмотря на инкапсуляцию классов в двух пакетах, остается неприятная транзитивная зависимость длиной четыре метода, и волновые эффекты в основном распространяются на зависимости метода.
Да, классы также страдают от волновых эффектов. Выше класс Here сбивается из-за изменения класса There , но это является следствием базовых зависимостей уровня метода. Никакая зависимость на уровне класса (и, следовательно, никакой волновой эффект на уровне класса) не может существовать без базовой зависимости на уровне метода (при условии, что у вас нет прямого доступа к переменным поля, что не так, верно?).
С точки зрения волнового эффекта зависимости на уровне класса и пакета являются просто показательными совокупностями базовых зависимостей уровня метода. Именно в этом смысле они не существуют, по крайней мере, как независимые конструкции.
Таким образом, структура исходного кода уровня метода может рассматриваться как фундаментальная структура , в то время как структура уровня класса и пакета может рассматриваться как производная структура в том смысле, что она вытекает из базовой структуры уровня метода.
Так можем ли мы просто игнорировать эту производную структуру и пойти на пиво?
Нет. Это просто служит другой и не менее важной цели из фундаментальной структуры.
Рассмотрим снова хорошие и плохие структуры пакетов на рисунке 1, воспроизведенные здесь на рисунке 2 … потому что прокрутка.
Рисунок 2: снова рисунок 1
Если наша теория верна, то ни одна из этих производных структур пакетов не говорит нам о том, сколько будет стоить обновление любой из этих систем, эта информация встраивается в структуру уровня метода.
Однако, если мы предполагаем типичное распределение методов по пакетам (то есть, ни один пакет не содержит, скажем, 99% всех методов), то рисунок 2 говорит нам кое-что важное: он говорит нам, что мы можем предсказать относительные затраты на обновление для красоты слева лучше чем для зверя справа.
Мы можем предсказать, что изменение самого верхнего пакета левой системы должно стоить меньше, чем изменение нижнего пакета, поскольку от этих более низких пакетов намного больше зависимостей. Это огромное преимущество по сравнению с карандашом, в котором изменение любого пакета может повлиять практически на все остальные.
Именно производная структура, а не фундаментальная структура, обеспечивает эту грубую предсказуемость, необходимую для любого крупного коммерческого проекта программного обеспечения.
Вы можете заподозрить, что эта предсказуемость также проистекает из фундаментальной структуры метода, что система слева должна иметь лучшую структуру метода, чем система справа. Но нет. Фактически, обе структуры пакета на рисунке 2 происходят из идентичных структур методов: они фактически являются одной и той же системой.
На рисунке 3 показано, как злые хакеры пытали систему слева с помощью 182 рефакторингов (используя алгоритм сокращения связывания пакетов методом грубой силы из предыдущего поста ). Детали не важны, но алгоритм просто перемещает классы между пакетами, переводы, которые никак не влияют на t a () -> b () -> c () -> d () ; эта транзитивная зависимость остается неизменной независимо от того, все ли четыре метода смешиваются в одном классе или резвятся в двух, трех или четырех классах или пакетах).
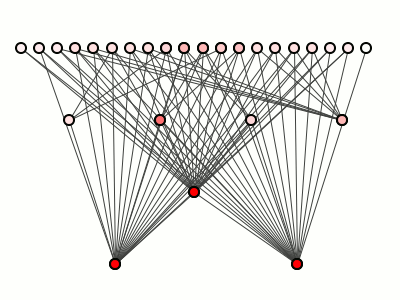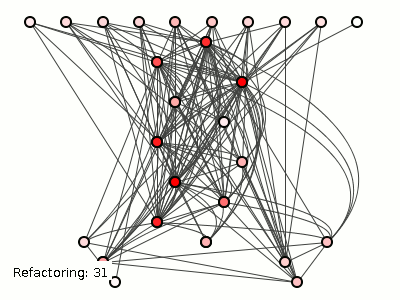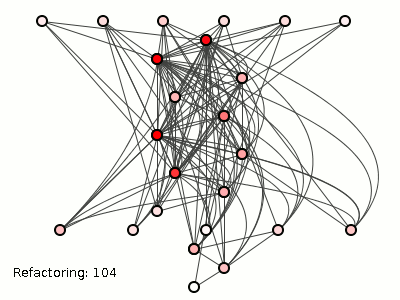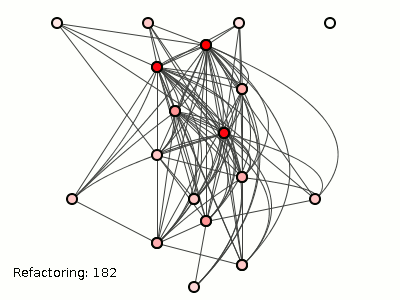
Рисунок 3: Хорошая структура, разбитая до смерти.
Два типа рефакторинга
Учитывая эти две разные структуры и учитывая, что рефакторинг — это просто реструктуризация с сохранением поведения, из этого следует, что должно быть два типа рефакторинга.
Если вы изменяете фундаментальную структуру программы — скажем, добавляете или объединяете методы или сокращаете транзитивные зависимости длинных методов — тогда вы делаете первый тип рефакторинга, назовем его фундаментальным рефакторингом . Цель фундаментального рефакторинга — сделать программы дешевле в обновлении.
Если вы изменяете производную структуру программы — например, если вы разделяете класс на две части или перемещаете некоторые классы в новый пакет — тогда вы делаете второй тип рефакторинга, давайте назовем его: сложный рефакторинг . Цель сложного рефакторинга состоит не в том, чтобы удешевить обновление программ, а в том, чтобы сделать затраты на обновление более предсказуемыми («разработав» грубую природу системы).
Так уж получилось, что способ улучшения обеих структур одинаков: минимизировать длину транзитивных зависимостей, будь то на уровне метода, класса или пакета.
Так что, в некотором смысле, все это довольно философски.
Так что … да … извините за это.
Резюме
В течение некоторого времени в блоге говорилось, что хорошая структура может помочь сократить расходы на обновление и повысить предсказуемость затрат.
Теперь ты знаешь как.
| Ссылка: | Фундаментальный рефакторинг против сложного рефакторинга от нашего партнера JCG Эдмунда Кирвана в блоге о программном обеспечении. блог. |