Часть вторая из двух частей серии: Переосмысление дизайна базы данных с помощью Apache Drill
В первой части этой серии, Drilling to Healthy Choices, мы рассмотрели использование Drill для создания таблиц Parquet, а также настройку Drill для чтения форматов данных, которые не являются стандартными. Мы также изучили Национальную базу данных по питательным веществам Министерства сельского хозяйства США, написав несколько различных запросов в Drill.
Во второй части этой серии мы собираемся использовать эту же базу данных, чтобы выйти за рамки традиционного проектирования баз данных.
Традиционный дизайн базы данных
В течение последних 30 лет программные приложения использовали СУРБД для сохранения своих данных. Некоторое время так было, потому что СУБД обычно поддерживается ИТ-организациями, что значительно упрощает внедрение программного обеспечения в производственную среду. Обычно инженеры создают структуры данных на языке программирования, который они используют, а затем выясняют, как сопоставить эти структуры данных с серией таблиц базы данных. В мире Java было много разных «решений» для постоянства. Самыми последними были Java Persistence API и Hibernate. Они предназначались для предоставления абстракции от базовой технологии баз данных для обеспечения некоторого уровня переносимости. Основная проблема заключается в том, что переносимость действительно была только от одной СУБД к другой. Вторичная проблема заключается в том, что создание этих сопоставлений было непростой задачей, и потребовалось много работы, чтобы проверить, что они работают так, как задумано.
Кажется, что было бы намного разумнее сохранить всю структуру данных как есть. Это сделало бы его действительно портативным, а также проще в разработке и тестировании. Давайте не будем забывать, что это также значительно упростит запрос данных. Это своего рода кошмар для написания SQL-запросов к сложным схемам базы данных. Трудно написать не только SQL-запросы к крупным схемам, но и барьер для людей, исследующих данные, хранящиеся в этих сложных схемах баз данных. Исследователи должны выяснить, какие столбцы в каких таблицах означают то, что находится в пределах вопросов, на которые они ищут ответы. Все может быть проще для всех участников на каждом этапе процесса.
Время развиваться
Давайте вернемся к схеме базы данных из последней статьи, посвященной Национальной базе данных по питательным веществам, предоставленной Министерством сельского хозяйства США.
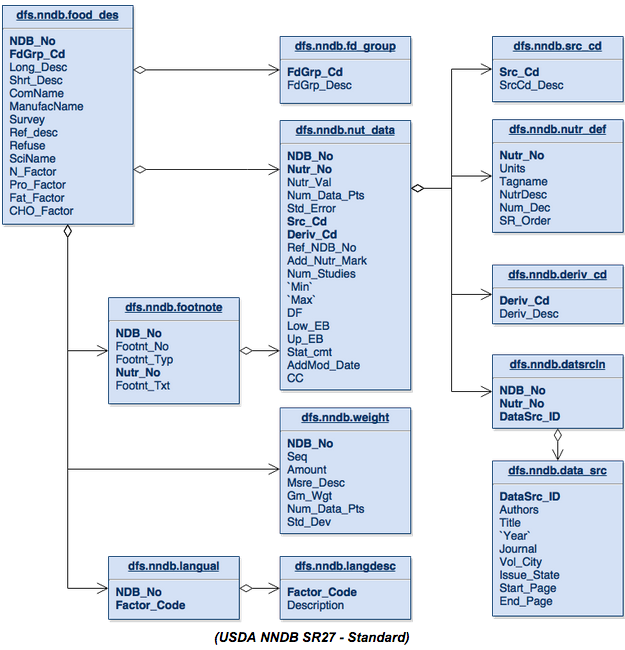
Начиная с верхней части этой схемы, мы видим, что таблица fd_group является не чем иным, как таблицей подробностей, которая дает максимум одну запись на запись в таблице food_des . Мы также видим те же отношения с src_cd , nutr_def и Derve_cd в таблице Nut_Data .
Каждая из таблиц nut_data , footnote и weight может содержать ноль или более записей на элемент в таблице food_des и давать то, что мне нравится называть списками. Таблица datsrcln — это не что иное, как таблица соединения от nut_data до data_src , и то же самое относится к языковой таблице к таблице langdesc . Оба генерируют не что иное, как списки данных.
Эта структура таблиц построена так, чтобы поддерживать концепции списков простых или сложных данных. Преимущество, которое ранее существовало благодаря такой схеме таблиц, заключалось в том, что она экономила деньги на дисковой памяти. Затраты на хранение сейчас в тысячи раз меньше, чем 10–30 лет назад, поэтому мы не будем экономить на хранении.
Давайте начнем с упрощения схемы базы данных, чтобы посмотреть, сможем ли мы сделать ее лучше для всех участвующих сторон:
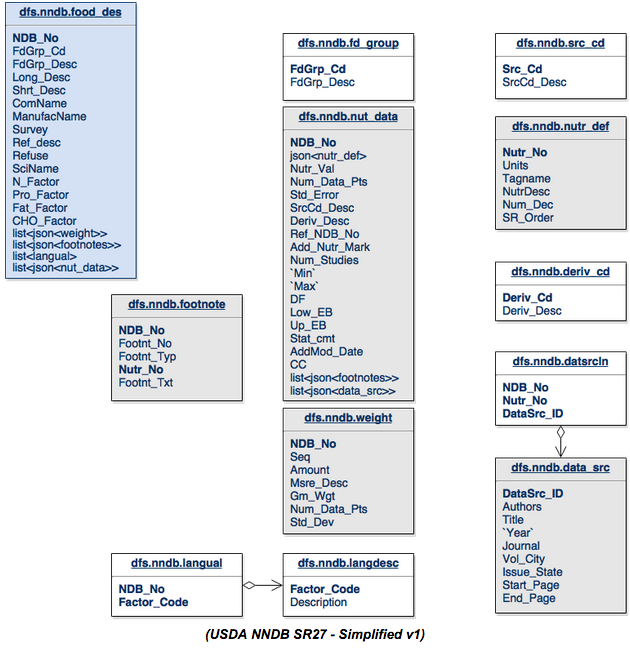
Посмотрите на изменения в таблице food_des . FdGrp_Desc из таблицы fd_group был объединен с таблицей food_des . Таблица весов объединяется с таблицей food_des в виде списков. Это список, потому что в таблицах может быть ноль или более элементов, относящихся к таблице food_des . Мы можем отогнать таблицы langual и langdesc до списка «описаний» из таблицы langdesc и сохранить их в таблице food_des . Таблица nut_data может стать списком элементов в таблице food-des .
Затем мы можем взять src_cd , nutr_def и производные_cd и просто объединить их непосредственно в структуру таблицы nut_data . Таблица datasrcln является таблицей соединений для data_src обратно к nut_data, поэтому мы просто объединяем ее как список элементов.
Более интересным случаем здесь является то, что после проверки таблицы сносок из исходной схемы кажется, что взаимосвязь между сноской и nut_data была записана неправильно. Стрелка, вероятно, должна указывать в противоположном направлении. Таблица сносок содержит два типа сносок. Он содержит сноски, относящиеся к food_des через ndb_no, но также относится к nut_data через комбинацию ndb_no и nutr_no. Чтобы поддержать это в новой схеме, мы разобьем таблицу сносок и создадим список сносок в nut_data и food_des .
Таблицы, которые теперь серые, представляют собой структуры данных в формате JSON в другой таблице. Белые таблицы в основном просто объединяются в родительские таблицы, либо напрямую, либо в виде списка.
«Потратив» немного места (по сравнению со стандартным дизайном), мы теперь получаем таблицу данных, которая внезапно может быть понятна любому. Вот более простое представление этой схемы данных:
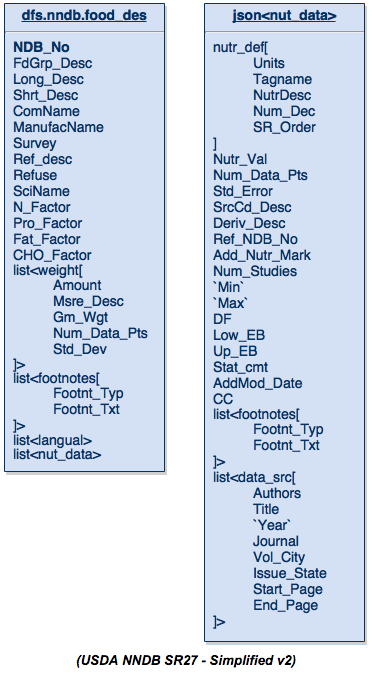
Таблица слева — это таблица food_des, а таблица справа — это просто структура данных JSON, которая ранее охватывала данные о питании ( nut_data ). Просматривая это, вы заметите, что он содержит все поля, которые были изначально определены в таблицах, за исключением некоторых полей, которые больше не имеют значения, таких как порядковые номера или коды факторов, или любых других полей, которые просто использовались для связь между таблицами.
Вот выдержка из некоторых данных из исходной базы данных и в этой структуре JSON для тестирования. Эти данные содержат одну запись food_des (я вручную добавил языковую запись, которой не было в исходной базе данных для этой записи). Скопируйте эти данные и поместите их в файл /tmp/food_des.json, и вы сможете выполнить остальные запросы самостоятельно.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
{ "ndb_no":"08613", "shrt_desc":"CEREALS RTE,KELLOGG'S SPL K MULTIGRAIN OATS & HONEY", "nut_data":[{ "nutr_no": "203", "nutr_val": "7.80", "nutr_def": {"num_dec":2,"tagname":"PROCNT","nutrdesc":"Protein"}, "data_src":[{ "datasrc_id": "S6941", "authors": "A Kellogg, Co.", "title": "Kellogg Company Data", "Year": "2011" }] }, { "nutr_no": "204", "nutr_val": "1.80", "nutr_def": {"num_dec":2,"tagname":"FAT","nutrdesc":"Total lipid (fat)"}, "data_src":[{ "datasrc_id": "S6941", "authors": "B Kellogg, Co.", "title": "Kellogg Company Data", "Year": "2011" }] }, { "nutr_no": "205", "nutr_val": "85.00", "nutr_def": {"num_dec":2,"tagname":"CHOCDF","nutrdesc":"Carbohydrate, by difference"}, "data_src":[{ "datasrc_id": "S6941", "authors": "C Kellogg, Co.", "title": "Kellogg Company Data", "Year": "2011" }] }], "langual":["ANISE","FRUIT","WHOLE, NATURAL SHAPE","NOT HEAT-TREATED","COOKING METHOD NOT APPLICABLE","WATER REMOVED","HEAT DRIED","HUMAN FOOD, NO AGE SPECIFICATION"]} |
Сложные возможности запроса структуры данных
Apache Drill был создан для того, чтобы иметь возможность запрашивать сложные структуры данных, такие как таблица, представленная выше. Мы можем начать с одного из самых простых вариантов использования — списка $ lt; langual>, который находится в таблице. Этот список является обычным способом описания элемента food_des . Чтобы найти информацию об общем языке для одного элемента в исходной схеме, нам нужно выполнить этот запрос:
|
1
2
3
4
|
SELECT fd.NDB_No, ld.Description FROM dfs.nndb.food_des fd LEFT JOIN dfs.nndb.langual lf ON (fd.NDB_No=lf.NDB_No) LEFT JOIN dfs.nndb.langdesc ld ON (lf.FACTOR_CODE=ld.FACTOR_CODE) where fd.NDB_No=02001; |
Это запрос в новой схеме, который использует функцию FLATTEN в Drill:
|
1
|
SELECT NDB_No, FLATTEN(langual) FROM dfs.tmp.`food_des.json` fd where fd.NDB_No=08613; |
Оба этих запроса возвращают одну строку для каждого описания в языковом списке. Второй запрос гораздо проще понять и написать. Это означает прямую экономию времени для тех, кто хочет проводить исследования, поскольку им будет намного легче работать с данными.
Давайте посмотрим на запрос, который значительно сложнее. Мы собираемся выбрать несколько полей из нескольких таблиц, чтобы узнать подробности об элементе питания и их источнике. Этот запрос не включает в себя все детали, которые могут быть извлечены, и ограничен тремя записями nutr_no :
|
1
2
3
4
5
6
7
8
9
|
SELECT fd.ndb_no, fd.shrt_desc, nd.nutr_no, nd.nutr_val, ndd.num_dec, ndd.tagname, ndd.nutrdesc, ds.authors, ds.title, ds.`year` FROM dfs.nndb.food_des fd, dfs.nndb.nut_data nd, dfs.nndb.nutr_def ndd, dfs.nndb.datsrcln dsl, dfs.nndb.data_src ds WHERE fd.NDB_No=nd.NDB_No AND nd.Nutr_No=ndd.Nutr_No AND nd.NDB_No=dsl.NDB_No AND nd.nutr_no=dsl.Nutr_No AND dsl.DataSrc_ID=ds.DataSrc_ID AND fd.NDB_No=08613 AND nd.nutr_no IN (203,204,205); |
Вот то, что тот же запрос хотел бы по отношению к новой схеме:
|
1
2
3
4
5
6
|
SELECT fd.ndb_no, fd.shrt_desc, fd.nut_data.nutr_no as nutr_no, fd.nut_data.nutr_val as nutr_val, fd.nut_data.nutr_def.num_dec as num_dec, fd.nut_data.nutr_def.tagname as tagname, fd.nut_data.nutr_def.nutrdesc as nutrdesc, fd.data_src.datasrc_id as datasrc_id, fd.data_src.authors as authors, fd.data_src.title, fd.data_src.`year` as `year` FROM (SELECT *, FLATTEN(fd1.nut_data.data_src) as data_src FROM (SELECT *, FLATTEN(fd2.nut_data) FROM dfs.tmp.`food_des.json` fd2) fd1) fd WHERE fd.ndb_no=08613 AND fd.nut_data.nutr_no IN (203,204,205); |
Хотя эти два запроса выглядят одинаково по длине, их сложность существенно отличается. Второй запрос выглядит длинным только из-за всех имен полей в операторе выбора.
Изменение этого запроса на SELECT * оставит нас с:
|
1
2
3
4
5
|
SELECT * FROM (SELECT *, FLATTEN(fd1.nut_data.data_src) as data_src FROM (SELECT *, FLATTEN(fd2.nut_data) FROM dfs.tmp.`food_des.json` fd2) fd1) fd WHERE fd.ndb_no=08613 AND fd.nut_data.nutr_no IN (203,204,205); |
С этой точки зрения становится очень легко увидеть, что мы на самом деле не делаем ничего, кроме пары вложенных операторов SQL, чтобы FLATTEN эти вложенные списки данных. Это действительно не требует предметной экспертизы, такой как объединение сложного набора таблиц И по всем параметрам эта Национальная база данных по питательным веществам с весом 12 таблиц довольно проста по сравнению с большинством баз данных, над которыми я работал, которые легко измеряются в сотнях таблиц.
Есть две другие функции, которые очень удобны для проверки вложенных данных. Первый — REPEATED_COUNT. Как вы можете догадаться, эта функция подсчитывает количество элементов в списке. С помощью этого запроса мы можем увидеть, сколько элементов в языковом списке:
|
1
|
SELECT fd.ndb_no, fd.shrt_desc, REPEATED_COUNT(fd.langual) as lang_count FROM dfs.tmp.`food_des.json` fd; |
Следующая функция REPEATED_CONTAINS. Эта функция проверяет список ключевых слов, чтобы узнать, существует ли оно. Здесь мы проверим, описан ли этот элемент словом FRUIT. Вы также можете изменить это на любой произвольный текст, чтобы убедиться, что он возвращает false:
|
1
|
SELECT fd.ndb_no, fd.shrt_desc, REPEATED_CONTAINS(fd.langual, 'FRUIT') as `Fruit?` FROM dfs.tmp.`food_des.json` fd; |
С этими двумя функциями очень легко работать. REPEATED_CONTAINS отлично подходит для предложения WHERE, чтобы ограничить наборы результатов при проведении исследования. Например, в приведенном выше случае ограничение запроса включает только элементы, перечисленные как FRUIT.
NoSQL на помощь
До сих пор мы узнали, как упростить нашу схему базы данных, чтобы каждый мог получить доступ к данным с минимальным пониманием базы данных. Мы также узнали, как использовать этот механизм SQL-запросов для запроса очень сложных структур JSON. Теперь нам нужно посмотреть, где мы можем сохранить наши данные.
С точки зрения приложения, сохранение (сериализация) структуры данных в формате JSON в языке, подобном Java, очень просто и занимает всего пару строк кода. Не требуется сложное сопоставление таблиц.
|
1
2
3
4
5
6
7
|
// 1 - Serialize a Java POJO using the Google GSON library Gson gson = new Gson(); String json = gson.toJson(yourObject); // 2 - Deserialize a Java POJO using the Google GSON library YourObject yourObject2 = gson.fromJson(json, YourObject.class); |
Теперь мы можем предотвратить всю дополнительную работу по выяснению того, как сопоставить структуру данных YourObject.java с набором таблиц в схеме базы данных. Это сэкономит вам много времени и усилий.
Теперь вы можете воспользоваться преимуществами магазина NoSQL, такого как HBase. Вы можете использовать его для оперативной обработки транзакций (OLTP), чтобы обеспечить линейную масштабируемость на уровне базы данных для любого приложения. Это означает, что в этих корпоративных приложениях больше нет причин беспокоиться о том, как масштабировать платформу при достижении пределов производительности, как в традиционной системе СУБД. Просто добавьте сервер в кластер, и вы хорошо масштабируете.
Вы также можете выполнять аналитику в реальном времени для данных JSON непосредственно с HBase, используя Drill, потому что Drill имеет возможность запрашивать HBase из коробки. Нет необходимости извлекать данные или преобразовывать данные в другой формат.
Я надеюсь, что эта статья вдохновила вас на размышления вне традиционных подходов проектирования баз данных и систем баз данных. Пожалуйста, поделитесь своими мыслями или идеями по этим темам ниже. Я хотел бы услышать от вас.
| Ссылка: | Эволюция схем баз данных с использованием SQL + NoSQL от нашего партнера по JCG Джима Скотта из блога Mapr . |