Эван любит проектировать, создавать и улучшать современные распределенные данные и серверные системы, используя новейшие технологии с открытым исходным кодом. Он является создателем распределенной аналитической базы данных с открытым исходным кодом FiloDB, а также сервера заданий Spark. Он руководил проектированием и внедрением нескольких платформ больших данных на основе Storm, Spark, Kafka, Cassandra и Scala / Akka, включая колоночный механизм распределенных запросов в реальном времени. Он является активным участником проекта Apache Spark и MVP Datastax Cassandra. Он создал приложения Spark начиная с Spark 0.8, а Cassandra с 0.6. Он большой сторонник GitHub, open source и встреч, а также выступал на различных конференциях, включая Strata, Spark Summit, Cassandra Summit, FOSS4G и Scala Days. Он имеет степень бакалавра и магистра электротехники, с отличием, из Стэнфордского университета.
Эта статья рассказывает о том, как Spark SQL выполняет многостоловые соединения, и о том, как мы достигли действительно быстрых соединений, используя Datastax DSE (Spark и Cassandra) и FiloDB.
Фон
В Tuplejump мы помогаем различным предприятиям создавать современные платформы для больших данных на основе новейших технологий. Одним из наших клиентов является Element Financial Services , ведущая компания по управлению автопарком и финансированию оборудования. Они выбрали Datastax Enterprise в качестве переходной платформы для замены своего хранилища данных и поддержки своей следующей аналитики и платформы BI. Datastax Enterprise обеспечивает стабильную, простую в установке установку Cassandra со встроенной поддержкой Apache Spark, корпоративными функциями и профессиональной поддержкой Datastax.
Что делает принятие Datastax Enterprise, Cassandra и Spark сложной задачей для построения хранилища данных и платформы BI? Во-первых, ожидается, что платформа будет соответствовать текущим соглашениям об уровне обслуживания для отчетности и специальной аналитики с помощью существующих инструментов BI. Cassandra — это надежная распределенная база данных, но она больше предназначена для тысяч одновременных небольших операций чтения и записи, и не столько для традиционных аналитических рабочих нагрузок, которые включают сканирование миллионов записей. Разнообразие и специальная природа запросов препятствовали широкому использованию предварительной агрегации. Удовлетворение ожиданий потребует расширения платформы до предела и инноваций. Во-вторых, из-за существующих запросов, отчетов и моделей использования обычная методика моделирования данных Cassandra для денормализации всех таблиц была невозможна. Замедление изменения таблиц измерений и других бизнес-требований означает, что соединения являются предпочтительными по сравнению с увеличением сложности ETL на порядок. СОЕДИНЕНИЯ еще не очень эффективны в Apache Spark, хотя они улучшаются с каждым выпуском. Таким образом, мы поставили перед собой цель обеспечить возможность выполнения запросов JOIN в Datastax Enterprise менее чем за 5 секунд с некоторым параллелизмом.
План
Мы начали с моделирования таблиц фактов и измерений таким образом, чтобы большинство запросов можно было выразить как запросы с одним разделом. Чтобы быть более точным, учитывая ключи разделения A, B и C, самые быстрые запросы выполняются, когда они запрашивают данные с предложением WHERE, похожим на WHERE A = val1 AND B = val2 AND C = val3. Эти предикаты приводят к точному совпадению для одного раздела Cassandra, а соединитель Spark-Cassandra способен сократить запрос до одного раздела / потока Spark и запросить только один узел Cassandra. (Это часто упоминается как нажатие на предикат). Запросы с другими комбинациями предикатов приводили либо к многораздельным запросам, либо к просмотру всей таблицы, что занимало минуты. Моделирование наших таблиц таким образом максимизирует преимущество Cassandra в тонкодисперсном разбиении и фильтрации.
Следующим шагом является оптимизация соединения. Допустим, у вас есть этот запрос:
|
1
2
3
|
SELECT t1.col1, t2.col2FROM small_table t1, big_table t2WHERE t2.a = t1.a AND t1.a = 'XYZ' |
Допустим, столбец a является ключом разделения для обеих таблиц t1 и t2. Таким образом, Cassandra получит предикатное нажатие для чтения из одного раздела для таблицы t1 (t1.a = ‘XYZ’), но запустит полное сканирование таблицы в t2 из-за отсутствия фильтра в t2.a. Это было бы очень медленно. Один из вариантов — заставить пользователей указать дополнительный предикат вручную, чтобы у вас был следующий запрос:
|
1
2
3
|
SELECT t1.col1, t2.col2FROM small_table t1, big_table t2WHERE t2.a = t1.a AND (t1.a = 'XYZ' AND t2.a = 'XYZ') |
Этот запрос лучше, так как у вас есть предикат ключа разделения для обеих таблиц t1 и t2. Однако вместо того, чтобы изменять поведение пользователя и / или менять способ использования инструментов BI, мы вложили средства в создание настраиваемого сервера Spark Hive Thrift, который может перехватывать запросы SQL, анализировать их и преобразовывать логический план для автоматического расширения JOIN. предикаты. (Как это сделать должно быть темой еще одного целого поста). Пользовательский сервер также дает нам возможность для других пользовательских преобразований плана, таких как выбор наиболее оптимальной таблицы Cassandra для ответа на данный запрос и замена этой таблицы в плане запроса. Мы находимся в процессе внесения некоторых из этих оптимизаций обратно в Spark через SPARK-13219 .
Наконец, для достижения необходимого параллелизма мы запустили Hive Thrift Server и любые другие приложения Spark, используя режим планировщика FAIR spark.scheduler.mode = FAIR. Мы заметили, что в кластере, даже для больших заданий сканирования Cassandra, занимающих все потоки, Spark может планировать параллельные задания, выполняемые в одном приложении.
Используйте все таблицы Кассандры
Ниже приведена визуализация DAG и временной шкалы событий из пользовательского интерфейса Spark при выполнении запроса отчетности JOIN из 4 таблиц в небольшом кластере DSE 4.8. Нетривиальный запрос состоит из выбора 29 столбцов из 4 таблиц, 3 столбцов объединения и 27 столбцов группировки. Разделы в самых больших таблицах содержат много тысяч строк каждый.

Визуализация DAG в Spark — отличный инструмент для демонстрации различных этапов, их взаимосвязи и операций, выполняемых на каждом этапе. Вы можете видеть, что здесь есть два различных типа этапов — 7, 8, 9 и 12, состоящие в основном из MapPartitions и Filter, и не имеют зависимостей от других этапов. Это этапы, которые считывают данные из таблиц Cassandra параллельно (MapPartitions) и фильтруют их. Этапы 10, 11 и 13 являются этапами соединения (ShuffleHashJoin), а строки показывают, как Spark выполняет соединение из 4 таблиц: сначала данные из 7 и 8 объединяются на этапе 10; затем результаты 10 и данные из 9 объединяются; и так далее.
Из графика времени событий вы можете сделать несколько выводов:
* Общее время запроса составляет ок. 6 секунд
* Четыре этапа чтения выполняются параллельно, по одному в каждом потоке, благодаря одиночному предикату разделов. Ура!
* Чтения занимают большую часть времени запроса. Этапы случайного воспроизведения — это крошечные этапы, которые зависят от этапов чтения; они занимают, возможно, 1/4 секунды.
* Запрос на узкие места при чтении для двух таблиц занимает около 5 секунд. 5 секунд каждый. Это чтения, содержащие наибольшее количество данных. Таким образом, тасования не являются узким местом.
В целом, план работал довольно хорошо. Использование хорошего моделирования данных с включенными опциями нажатия клавиш секционирования позволяет распараллеливать чтения, но при этом содержать по одному потоку на таблицу. Можем ли мы улучшить и улучшить эти длинные чтения?
Используйте смешанные таблицы Cassandra + FiloDB
Мы решили сохранить данные из двух крупнейших таблиц (одна таблица фактов, одна таблица больших измерений) в FiloDB , которая хранит данные в Cassandra в столбчатом формате, оптимизированном для быстрых аналитических / OLAP-запросов. FiloDB имеет модель данных, аналогичную модели Cassandra, что означает, что мы можем использовать ту же стратегию поиска с одним разделом для эффективной фильтрации запросов. Когда две большие таблицы Кассандры заменяют таблицы FiloDB, вот результаты:
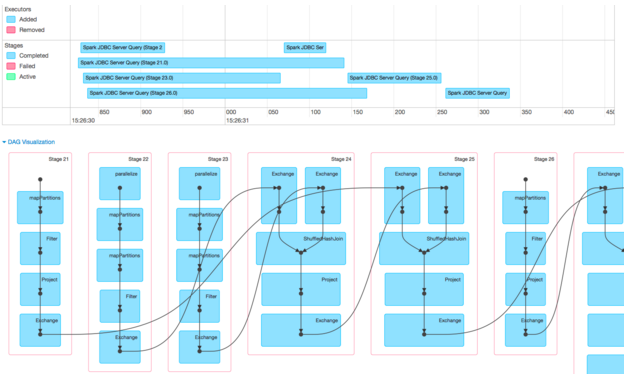
Мы сконцентрируемся на временной шкале события, поскольку DAG такая же, за исключением номеров этапов. Обратите внимание, что масштаб шкалы времени теперь указывается в миллисекундах, а весь запрос JOIN из 4 таблиц завершается всего за полсекунды! Это ускорение позволило использовать FiloDB, что уменьшило предыдущие 5 секунд чтения до 250 мс каждый. (Стадии FiloDB — это 22 и 23, те, у которых «параллелизация» находится вверху каждой ступени, поскольку источник данных sc.parallelize использует sc.parallelize / sc.makeRDD , в то время как Spark Cassandra Connector имеет собственный класс RDD).
Используя FiloDB для хранения самых больших таблиц, мы смогли достичь времени соединения менее секунды для нетривиального запроса, охватывающего четыре таблицы и удовлетворяющего желаемым соглашениям об уровне обслуживания. В то же время решение по-прежнему вписывается в стек Datastax Enterprise / Spark / Cassandra, упрощая операции и обслуживание для снижения совокупной стоимости владения.
Куда пойти отсюда
Мы надеемся, что вы видели стратегии и технологии, которые, собрав их вместе, могут ускорить запросы JOIN в реальном мире на Spark и Cassandra — даже JOIN с четырьмя таблицами может выполняться менее чем за секунду!
Для получения дополнительной информации о FiloDB посетите нашу веб-трансляцию O’Reilly или посетите проект Github . Для получения дополнительной информации о Datastax Enterprise, пожалуйста, посетите целевую страницу .
Если вы заинтересованы в работе над передовыми технологиями обработки больших данных, такими как Spark, Cassandra и FiloDB, рассмотрите возможность объединения наших усилий в Element и Tuplejump!
| Ссылка: | Достижение подпрограмм SQL JOINs и создание хранилища данных с использованием Spark, Cassandra и FiloDB от нашего партнера по JCG Эвана Чана в блоге Planet Cassandra . |