В недавнем проекте, связанном с системой CQRS на основе событий, мы решили сделать некоторые вещи, которые кажутся несколько необычными по сравнению с решениями, о которых в основном говорилось. Тем не менее, они позволяют нам получить некоторые хорошие свойства, которые в противном случае были бы трудными (если вообще возможно)
Магазин событий как обычный стол
Мы решили реализовать хранилище событий как обычную таблицу в СУБД. Мы использовали PostgreSQL, но здесь мало что характерно для PostgreSQL. Мы знаем, что эта база данных очень надежная, мощная и просто зрелая. Кроме того, транзакции ACID с одним узлом обеспечивают некоторые действительно хорошие преимущества.
Таблица закончилась следующими полями:
-
event_id(int) — первичный ключ из глобальной последовательности -
stream_id(UUID) — идентификатор потока событий, обычно агрегат DDD -
seq_no(int) — порядковый номер в истории конкретного потока -
transaction_time(timestamp) — время начала транзакции, одинаковое для всех событий, совершенных в одной транзакции - id
correlation_id(UUID) -
payload(JSON)
Не все из них являются обязательными для хранилища событий, но есть одно важное и необычное отличие: event_id — глобально, последовательно увеличивающееся число. Мы вернемся к этому через минуту.
Ты можешь сделать это?
Если вы идете за хранилищем событий в обычной таблице БД, получить глобальный идентификатор события, как это, очень дешево. Базы данных действительно эффективно генерируют, хранят, индексируют и т. Д. Такие столбцы. Единственная актуальная проблема — можете ли вы позволить себе использовать для этого таблицу БД.
Система, которую мы строим, не ориентирована на широкую сеть. Он предназначен для внутреннего использования в компаниях с сотнями или тысячами пользователей. Это относительно небольшой масштаб, и у Postgres не будет проблем с обслуживанием.
В общем, это не то, что я бы рекомендовал, если бы вы строили следующую Амазонку. Но скорее всего, это не так, и вы можете позволить себе роскошь использования более простых технологий.
Преимущества глобального последовательного идентификатора события
Теперь, когда у нас есть этот специфический идентификатор события, что мы можем с ним сделать?
Давайте посмотрим на интерфейс чтения нашего хранилища событий:
|
1
2
3
4
5
|
public interface EventStoreReader { List<Event> getEventsForStream(UUID streamId, long afterSequence, int limit); List<Event> getEventsForAllStreams(long afterEventId, int limit); Optional<Long> getLastEventId();} |
Первый метод довольно очевиден и его можно найти повсюду. Мы используем его только для восстановления одного потока (агрегата) из хранилища событий для обработки новой команды.
Два других используют идентификатор события, возвращая пакет событий после определенного события, и идентификатор последнего события. Они являются основой наших моделей чтения (проекции).
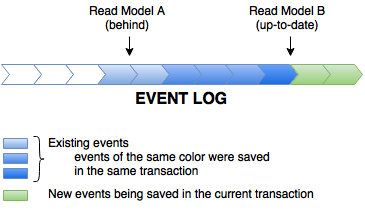
Чтение моделей осуществляется путем опроса (с подсказками) хранилища событий. Они запоминают идентификатор последнего обработанного события . Время от времени (или когда их вызывает уведомление из хранилища событий), они читают следующий пакет событий из хранилища и обрабатывают их последовательно, в одном потоке.
Этот тип линейной однопоточной обработки, вероятно, настолько прост, насколько это возможно, но он, очевидно, имеет ограниченную масштабируемость. Если вы получаете 600 событий в минуту, это означает, что в среднем вы не можете быть медленнее, чем 100 мс на событие, несмотря ни на что. На самом деле вам также нужно учитывать накладные расходы и оставлять некоторый запас, так что это должно быть быстрее, чем это.
Это может быть решено с помощью шардинга или распараллеливания записей в модели чтения, но на данный момент мы не нашли в этом необходимости. Наличие нескольких независимых специализированных моделей, работающих параллельно, безусловно, помогает в этом.
Сравнивая последний обработанный идентификатор события для прогноза с текущим глобальным максимумом, вы можете сразу определить, сколько стоит проекция . Это логический эквивалент размера очереди.
Глобальная последовательность также может быть использована для уменьшения недостатков возможной согласованности (или устаревания).
Выполнение команды может вернуть идентификатор последнего записанного события. Затем запрос может использовать этот идентификатор, запрашивая: «Я в порядке, жду 5 секунд, но не дайте мне результат, если ваши данные старше этого идентификатора». В большинстве случаев это всего лишь миллисекунды. По этой цене, когда пользователь вносит изменения, он сразу же видит результаты. И это фактические данные, поступающие с сервера, а не имитация, достигнутая путем дублирования логики домена в пользовательском интерфейсе!
Это также полезно на стороне домена. У нас есть некоторые приложения и доменные службы, которые запрашивают некоторые доменные прогнозы (например, для уникальных проверок). Если вы знаете, что последним событием в хранилище событий является X, вы можете просто подождать, пока проекция не достигнет этой точки, прежде чем продолжить выполнение команды. Это все, что нужно для решения многих проблем, обычно решаемых сагой.
Наконец, что не менее важно, поскольку все события упорядочены, проекция всегда последовательна . Это может отставать на несколько секунд или несколько дней, но это никогда не противоречит. Просто невозможно столкнуться с такими проблемами, как обработка одного потока до понедельника, а другого до четверга. Если что-то произошло до того, как произошло конкретное событие, в модели представления всегда сохраняется один и тот же порядок.
Это делает код и состояние системы намного проще для написания, поддержки и анализа.
Масштабируемость и сложность
Существует тенденция использовать сложные технологии с высокой масштабируемостью независимо от реальных требований заказчика и реалистичного масштаба. Такие инструменты имеют свое место, но они не являются очевидными победителями, никакие золотые молотки не решают всех проблем. Более того, они действительно дороги, если учесть сложность разработки и эксплуатации, а также их ограничения.
Иногда более простой инструмент хорошо решит проблему. Вы не только экономите на разработке и операциях, но и получаете доступ к некоторым действительно мощным инструментам, которые невозможны в больших масштабах. Включая глобальные счетчики, линеаризуемость и ACID транзакции.
В нашем примере показана система, которая была достаточно сложной, чтобы гарантировать получение событий с помощью CQRS, но в достаточно малом масштабе, чтобы можно было использовать линейное хранилище событий, даже с линейными проекциями, в простых базах данных Postgres.
Есть много веских причин для выбора скучных технологий . Если вы вводите новшества (и вы должны это делать), будьте осторожны с тем, почему вы на самом деле делаете это, и не вводите новшества во всех областях одновременно.
| Ссылка: | Достижение согласованности в CQRS с Linear Event Store от нашего партнера JCG Конрада Гаруса в блоге Белки . |