Метатенденция, происходящая в ИТ-отрасли, — это переход от систем на основе запросов к пакетным системам к (мягким) обновленным системам реального времени. Хотя это связано только с финансовой торговлей, есть много других примеров, таких как логистические системы «Just-In-Time», авиакомпании, выполняющие оценку пассажирских мест в реальном времени на основе спроса и нагрузки, аукционная система C2C, такая как EBay, трафик в реальном времени контроль и многое другое.
Вполне вероятно, что эта тенденция сохранится, поскольку (коммерческая) ценность информации зависит от времени , ценность уменьшается с возрастом информации.
Автоматическая торговля в финансовом секторе является лишь предвестником в этой области, потому что некоторые временные преимущества в микросекундах могут стоить миллионы долларов. Его естественные системы обработки в реальном времени развиваются в этой области быстрее.
Однако большая часть традиционной ИТ-инфраструктуры не предназначена для реактивных систем, основанных на событиях. От баз данных, основанных на запросах, до протоколов Http, основанных на запросе-ответе, общей парадигмой является хранение и запрос данных «при необходимости».
Текущие базы данных являются статичными и ориентированными на запросы
Современные подходы к управлению данными, такие как базы данных SQL и NOSQL, фокусируются на транзакциях данных и статическом запросе данных. Базы данных обеспечивают удобство в разрезании и копировании данных, но они не поддерживают обновление сложных запросов в режиме реального времени. Восстание баз данных NOSQL по-прежнему сосредоточено на вычислении статического результата.
Базы данных явно не являются «реактивными».
Текущие продукты обмена сообщениями предоставляют плохие параметры запросов / фильтрации
Текущие продукты обмена сообщениями слабо фильтруются. Сообщения разделяются на разные потоки (или темы), поэтому клиенты могут предварительно выбирать полученные данные. Однако это часто означает, что клиентское приложение получает примерно в 10 раз больше данных, чем необходимо, выполняя тонкую фильтрацию «сверху».
Большим недостатком является то, что тематический подход встраивает возможности фильтра «в» проектирование данных системы.
Например, если система фондовой биржи разделяет потоки на основе акций, клиентскому приложению все еще необходимо подписаться на все потоки, чтобы предоставить динамически обновляемый список «наиболее активных» акций. Запросы обычно означают «воспроизведение + поиск по всей истории сообщений».
Масштабируемый распределенный «непрерывный запрос» Datagrid.
Мне очень понравилось заниматься концептуальным и техническим проектированием крупномасштабной системы реального времени, поэтому я хотел бы поделиться универсальным масштабируемым решением для непрерывной обработки запросов в больших объемах и масштабах.
Как правило, системы обработки в реальном времени разрабатываются «на основе событий». Это означает, что постоянство заменяется журналированием транзакций. Состояние системы хранится в памяти, журнал транзакций необходим только для исторического анализа и восстановления после сбоя.
Клиентские приложения не запрашивают, а прослушивают потоки событий. Общей проблемой систем, основанных на событиях, является проблема «позднего присоединения клиента». Поздний клиент должен был бы воспроизвести весь журнал системных событий, чтобы получить актуальный снимок состояния системы.
Для поддержки позднего присоединения клиентов необходим своего рода компонент «Last Value Cache» (LVC). LVC хранит текущее состояние системы и позволяет последним присоединяющимся пользователям загружаться с помощью запросов.
В высокопроизводительной системе больших данных компонент LVC становится узким местом по мере увеличения числа клиентов.
Обобщение кэша последнего значения: непрерывные запросы
В кеше данных непрерывного запроса результат запроса автоматически обновляется. Запросы заменяются подписками.
|
1
2
3
4
|
subscribe * from Orders where symbol in ['ALV', 'BMW'] and volume > 1000 and owner='MyCompany' |
создает поток сообщений, который первоначально выполняет операцию запроса, после чего обновляет результирующий набор всякий раз, когда происходит изменение данных, влияющее на результат запроса (прозрачно для клиентского приложения). Система гарантирует, что каждый подписчик получит именно те уведомления об изменениях, которые необходимы для своевременного обновления результатов «живого» запроса.
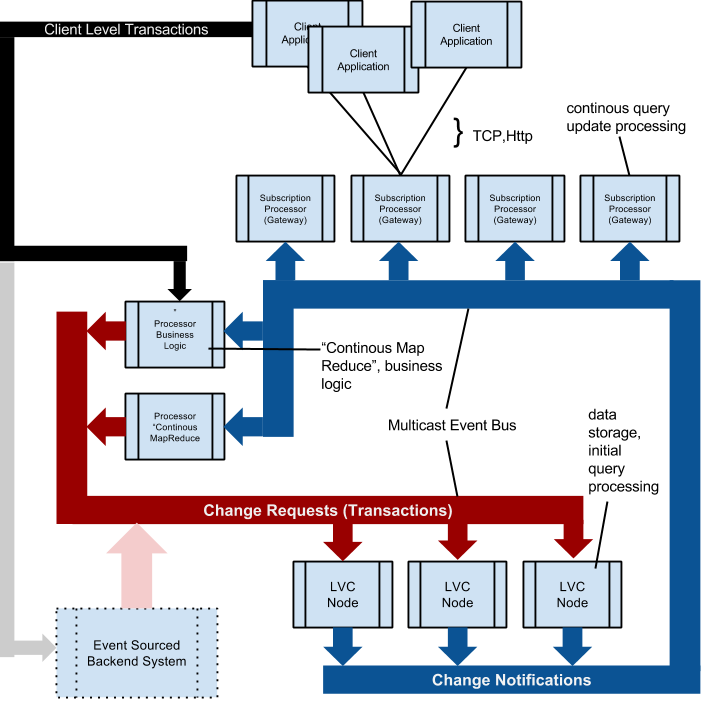
Распределенная система непрерывных запросов: узлы LVC содержат данные. Транзакции отправляются им по шине сообщений (красный). Узлы LVC вычисляют фактическую разницу, вызванную транзакцией, и отправляют уведомления об изменениях по шине сообщений (синий). Это позволяет «узлам обработки» поддерживать актуальность соответствующего раздела данных. Внешние клиенты, подключенные через TCP / Http, не прослушивают шину сообщений (поскольку многоадресная рассылка не доступна в WAN). «Процессоры подписки» поддерживают постоянные запросы клиента в актуальном состоянии, прослушивая (синюю) шину сообщений и отправляя необходимые уведомления об изменениях только клиентскому соединению point2point.
Разница в схемах доступа к данным по сравнению со статическим управлением данными:
- Большой объем записи
Системы реального времени создают большой объем доступа к записи / изменения данных. - Меньше полных сканирований таблицы.
Только клиенты с поздним присоединением или изменения условий запроса требуют полного сканирования данных. Поскольку непрерывные запросы делают «обновление» результата запроса устаревшим, соотношение чтения / записи составляет ~ 1: 1 (если считать уведомление об изменении, полученное в результате транзакции, как «Доступ для чтения»). - Большая часть нагрузки генерируется при оценке запросов активных непрерывных подписок при каждом изменении данных. Рассмотрим нагрузку транзакции в 100 000 изменений в секунду с 10 000 активных непрерывных запросов: для этого требуется 100 000 * 10 000 = 1 млрд. Оценок условий запроса в секунду . Это все еще недооценка: при обновлении записи необходимо проверить, соответствует ли запись условию запроса перед обновлением и соответствует ли оно после обновления. Обновление записи может привести к добавлению (потому что оно соответствует после изменения) или удалению транзакции (поскольку запись больше не соответствует после изменения) подписке на запрос (или «обновление», или «пропуск» ofc).
Узлы кластера данных («Узлы LastValueCache»)
Данные организованы в виде таблиц, ориентированных на столбцы. Данные каждой таблицы равномерно распределяются между всеми узлами сетки данных (= последний узел кэша значений = «узел LVC»). При добавлении узлов данных в кластер увеличивается емкость, а запросы моментальных снимков (инициализация подписки) ускоряются за счет увеличения параллелизма.
Есть три основных транзакции / сообщения, обрабатываемые узлами сетки данных:
- AddRow (таблица, NewRow),
- RemoveRow (таблица, RowId),
- UpdateRow (таблица, rowId, diff).
Узлы сетки данных предоставляют лямбда-подобный интерфейс (итератор строк), поддерживающий итерацию строк таблицы с использованием простого Java-кода. Это можно использовать для выполнения заданий по уменьшению карты и в качестве специализации — начальный запрос, который требуется новым подписчикам. Поскольку текущие вычисления непрерывных запросов выполняются в узлах «шлюза», загрузка узлов данных и количество клиентов коррелируют только слабо.
Все транзакции, обрабатываемые узлом сетки данных, (ре) транслируются с использованием многоадресных сообщений «Уведомление об изменении».
Узлы шлюза
Узлы шлюза отслеживают подписки / соединения с клиентскими приложениями. Они прослушивают глобальный поток уведомлений об изменениях и проверяют, влияет ли изменение на результат непрерывного запроса (= подписка). Это очень интенсивно использует процессор.
Две вещи делают эту работу:
- Используя простой Java для определения запроса, условия запроса получают выгоду от JIT-компиляции, нет необходимости анализировать и интерпретировать язык запросов. HotSpot — один из лучших оптимизирующих JIT-компиляторов на планете.
- Поскольку многоадресная рассылка используется для потока глобальных изменений, можно добавить дополнительные узлы шлюза, не влияющие на пропускную способность кластера.
Узлы процессора (или мутатора)
Эти узлы реализуют логику поверх данных кластера. Например, процессор статистики выполняет непрерывный запрос для каждой таблицы, постепенно подсчитывает количество строк в каждой таблице и записывает результаты обратно в таблицу «статистики», чтобы клиентское приложение мониторинга могло подписаться на данные в реальном времени текущих размеров таблицы. Другим примером может быть «процессор соответствия» на фондовой бирже, который прослушивает ордера на акцию, если ордера совпадают, он удаляет их и добавляет сделку в таблицу «сделок».
Если рассматривать весь кластер как «гигантскую электронную таблицу», процессоры реализуют формулы этой электронной таблицы.
Масштабирование
- с размером данных:
увеличить количество узлов LVC - Количество клиентов
увеличить подписку процессорных узлов. - TP / S
масштабировать процессорные узлы и узлы LVC
Конечно, система в значительной степени зависит от доступности «настоящей» системы шины многоадресных сообщений. Любые двухточечные или брокерские сети / обмен сообщениями будут огромным узким местом.
Вывод
Создание программного обеспечения для обработки в реальном времени с системой непрерывных запросов значительно упрощает разработку приложений.
- Его модель-вид-контроллер в большом масштабе.
Удивительно: шаблоны, используемые в приложениях с графическим интерфейсом в течение десятилетий, не были распространены на системы хранения данных. - Любая обработка на стороне сервера может быть разделена естественным образом. Процессорный узел создает зеркало своего раздела данных в памяти, используя непрерывные запросы. Результаты обработки передаются обратно в таблицу данных. Вычисление интенсивных заданий, например, вычисление риска производных, может быть масштабировано путем добавления экземпляров процессора, подписывающихся на отдельные разделы данных («разбиение»).
- Размер Code Base значительно уменьшается (как бизнес-логика, так и Front-End).
Большая часть кода в системах ручной работы имеет дело с обновлением данных.