Назад в древнюю историю (2004) Джефф Дин и Санджай Гемават из Google представили свою инновационную идею для работы с огромными наборами данных — новую идею под названием MapReduce
Джефф и Санджай представили, что типичный кластер состоит из 100–10 тысяч машин с 2 ЦП и 2–4 ГБ ОЗУ каждый. Они представили, что за весь август 2004 года Google обработал ~ 3,3 ПБ данных в 29 423 заданиях, то есть в среднем было обработано около 110 ГБ данных.
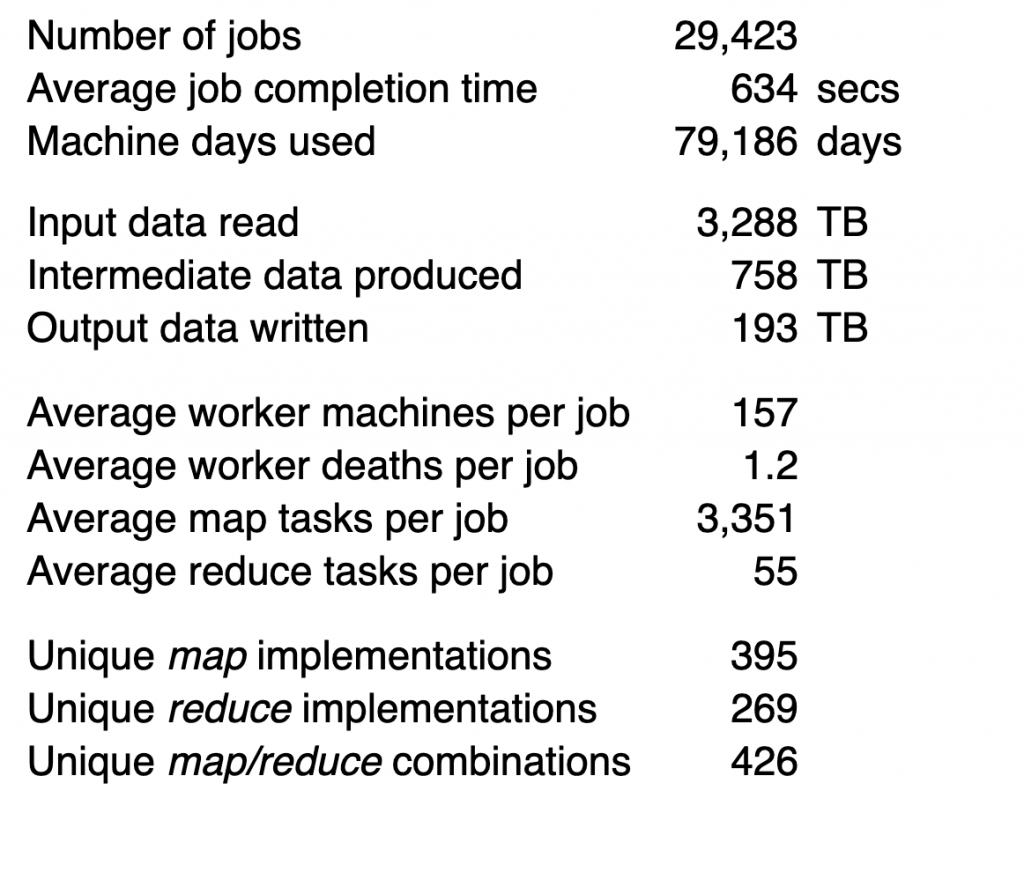
Как это соотносится с сегодняшними системами и рабочими нагрузками?
Я не мог получить точные цифры от Google, но другие говорят, что к 2017 году Google обрабатывал более 20PB в день (не говоря уже об ответе на 40K поисковых запросов в секунду), поэтому Google определенно находится в игре с большими данными. После этого цифры быстро сокращаются, даже для компаний, которые действительно являются крупными информационными компаниями — Facebook, представленный еще в 2017 году, ежедневно обрабатывает 500 ТБ + новых данных. Всего данных Twitter по состоянию на май 2018 года было около 300 ПБ, а Uber сообщил, что их хранилище данных находится в 100+ ПБ
Хорошо, а как насчет остальных из нас? Давайте посмотрим на пример
Марк Литвинчик взял набор данных из 1,1 миллиардов поездок в такси и Uber, опубликованный Тоддом У. Шнидером, на 500 ГБ несжатого CSV (т.е. в 5 раз больше, чем в среднем по Google в 2004 году) и сравнил его с современной инфраструктурой больших данных. Например, он запустил свой тест с Spark 2.4.0 на
Кластер m3.xlarge с 21 узлом — т.е. 4 виртуальных ЦП и 15 ГБ ОЗУ на узел (это x2 ЦП и x4 ОЗУ по сравнению с машинами 2004 года)
Его тест включает в себя несколько запросов. Выполнение приведенного ниже заняло 20,412 секунды, поэтому в целом это выглядит как приличный прогресс за 14 лет (я знаю, что это не настоящее сравнение, но следующее :)).
|
01
02
03
04
05
06
07
08
09
10
|
SELECT passenger_count, year(pickup_datetime) trip_year, round(trip_distance), count(*) trips FROM trips_orc GROUP BY passenger_count, year(pickup_datetime), round(trip_distance) ORDER BY trip_year, trips desc; |
Однако правда в том, что этот набор данных «1,1 миллиарда поездок» — не большая проблема с данными. Так получилось, что Марк также выполнил тот же тест на одноядерном ноутбуке i5 (16 ГБ ОЗУ), используя Яндекс ClickHouse, и тот же запрос занял всего 12,748 секунд, почти на 40% быстрее.
Там, где я работаю сегодня, один из наших самых больших наборов — это 7 миллионов часов госпитализации пациентов с минимальным разрешением, с сотнями различных функций: жизненно важные функции, лекарства, лаборатории и множество клинических особенностей, построенных на них — это все еще удобно вписывается в общедоступной версии Vertica (т. е. <1 ТБ данных)
Фактически, при цене менее 7 долл. / Час Amazon арендует вам 1 ТБ ОЗУ с 64 ядрами — и у них есть машины, которые занимают до 12 ТБ ОЗУ — так что огромное количество наборов данных и проблем на самом деле помещаются в памяти.
Если взглянуть на другой аспект — одна из основных идей Map / Reduce и множества технологий «больших данных», которые последовали за этим, заключается в том, что, поскольку данные велики, гораздо эффективнее перенести вычисления туда, где находятся данные. Документация для Hadoop, автора плаката для больших систем данных, хорошо объясняет это в разделе архитектуры HDFS
«Вычисление, запрошенное приложением, намного эффективнее, если оно выполняется рядом с данными, с которыми оно работает. Это особенно верно, когда размер набора данных огромен. Это сводит к минимуму перегрузку сети и увеличивает общую пропускную способность системы. Предполагается, что зачастую лучше перенести вычисление ближе к месту, где расположены данные, чем перемещать данные туда, где выполняется приложение. HDFS предоставляет интерфейсы для приложений, позволяющих им перемещаться ближе к тому месту, где находятся данные ».
В одной из предыдущих компаний, в которой я работал, мы обрабатывали 10 миллиардов событий в день. Мы все еще могли хранить наши данные в S3 и считывать их в искровой кластер для создания отчетов, таких как «еженедельное хранение», которые выглядели как данные за 6 месяцев — т.е. все данные, которые были в терабайтах, были прочитаны из удаленного хранилища — это было И все же то, что вы бы назвали работой с большими данными, работающей на 150 серверах с большим количеством оперативной памяти (что-то вроде 36 ТБ в пределах кластера), но опять же, мы могли бы и действительно приводить данные к вычислениям, а не наоборот.
Сам Hadoop теперь поддерживает RAID-подобные коды стирания, а не только 3-кратную репликацию (которая была очень полезна для получения локальности данных), а также предоставленное хранилище (то есть не управляемое HDFS).
Напомним, что эта неспособность обеспечить реальное конкурентное преимущество над облачным хранилищем (и, следовательно, облачными предложениями Hadoop), наряду с ростом Kubernetes, — вероятно, заставила Cloudera и HortonWorks объединиться и объединиться — но это для другого Почта.
В любом случае, я пытаюсь подчеркнуть, что по мере того, как объем данных увеличивается, порог больших данных также отодвигается. Я часто вижу вопросы о StackOverflow, когда человек запускает 3-узловый искровой кластер и жалуется, почему он / она видит плохую производительность по сравнению с тем, что он делал раньше — конечно, именно так и будет — инструменты больших данных созданы для больших данных (Дух!) и когда вы используете небольшие данные (а это может быть довольно много, как мы видели), вы платите все накладные расходы и не получаете никаких преимуществ. Примеры, которые я привел здесь, относятся к статическим данным, но то же самое относится и к потоковым решениям. Такие решения, как Kafka, сложны — они действительно хорошо решают определенные типы проблем, а когда вам это нужно, они неоценимы.
В обоих случаях потоковая и пакетная обработка — когда вам не нужны инструменты для работы с большими данными, это просто бремя. Во многих случаях «большие данные» не
|
Опубликовано на Java Code Geeks с разрешения Арнона Ротема Гал Оз, партнера нашей программы JCG . Смотрите оригинальную статью здесь: Большие данные не — ну, почти Мнения, высказанные участниками Java Code Geeks, являются их собственными. |