Примечание редактора: не пропустите наш новый бесплатный учебный курс по требованию о том, как создавать приложения конвейера данных с использованием Apache Spark — узнайте больше здесь.
Деревья решений широко используются для задач машинного обучения классификации и регрессии. В этом посте я помогу вам начать использовать деревья классификации Apli Spark MLlib для машинного обучения для классификации.
Обзор алгоритмов ML
В целом, машинное обучение может быть разбито на два класса алгоритмов: контролируемый и неконтролируемый.
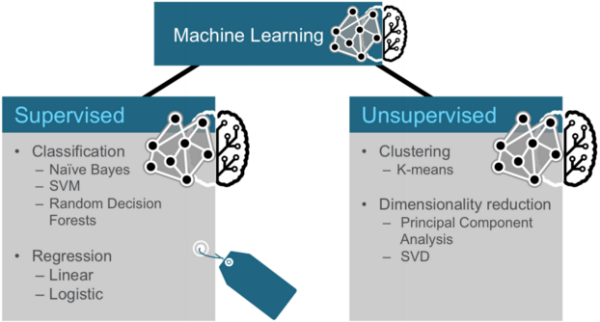
Контролируемые алгоритмы используют помеченные данные, в которых вход и выход передаются в алгоритм. Неуправляемые алгоритмы не имеют выходов заранее. Эти алгоритмы оставляют смысл данных без меток.
Три категории методов машинного обучения
Три общие категории методов машинного обучения — классификация, кластеризация и совместная фильтрация.
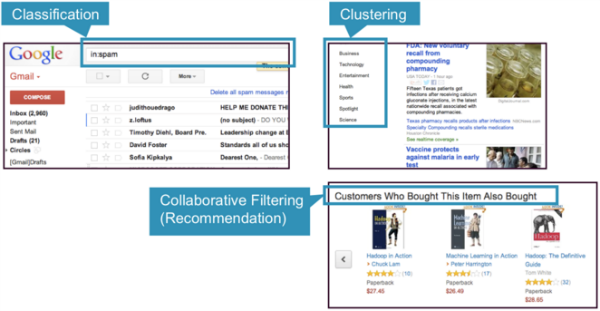
- Классификация. Gmail использует метод машинного обучения, называемый классификацией, для определения того, является ли электронная почта спамом или нет, на основе данных электронного письма: отправитель, получатели, тема и тело сообщения. Классификация берет набор данных с известными метками и изучает, как маркировать новые записи на основе этой информации.
- Кластеризация. Новости Google используют технику, называемую кластеризацией, для группировки новостных статей по различным категориям на основе заголовка и содержания. Алгоритмы кластеризации обнаруживают группировки, которые встречаются в коллекциях данных.
- Коллаборативная фильтрация: Amazon использует метод машинного обучения, называемый коллективной фильтрацией (обычно называемый рекомендацией), для определения того, какие продукты пользователям понравятся, исходя из их истории и сходства с другими пользователями.
классификация
Классификация — это семейство контролируемых алгоритмов машинного обучения, которые обозначают входные данные как принадлежащие одному из нескольких предопределенных классов. Некоторые общие случаи использования для классификации включают в себя:
- обнаружение мошенничества с кредитными картами
- обнаружение спама в электронной почте
Данные классификации помечены, например, как спам / не спам или мошенничество / не мошенничество. Машинное обучение присваивает метку или класс новым данным.
Вы классифицируете что-то на основе заранее определенных особенностей. Особенности — это «если вопросы», которые вы задаете. Этикетка является ответом на эти вопросы. В этом примере, если он ходит, плавает и крякает, как утка, то ярлык «утка».

Кластеризация
При кластеризации алгоритм группирует объекты по категориям, анализируя сходства между входными примерами. Кластеризация включает в себя:
- Группировка результатов поиска
- Группировка клиентов
- Обнаружение аномалий
- Текстовая категоризация

Кластеризация использует неконтролируемые алгоритмы, которые не имеют выходов заранее.
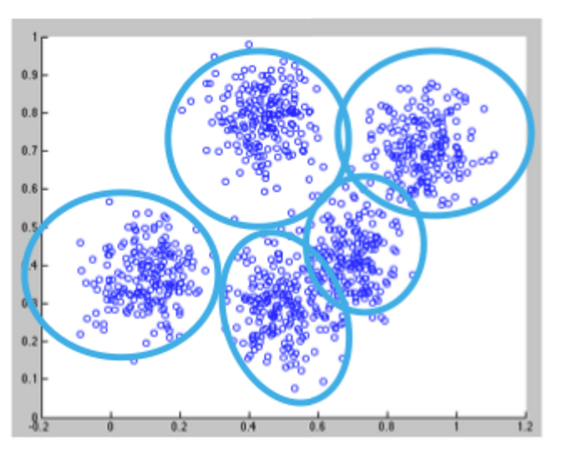
Кластеризация с использованием алгоритма K-средних начинается с инициализации всех координат центроидами. С каждым проходом алгоритма каждая точка присваивается ближайшему центроиду на основе некоторой метрики расстояния, обычно евклидова расстояния. Центроиды затем обновляются, чтобы стать «центрами» всех точек, назначенных ему в этом проходе. Это повторяется до тех пор, пока не произойдет минимальное изменение в центрах.
Совместная фильтрация
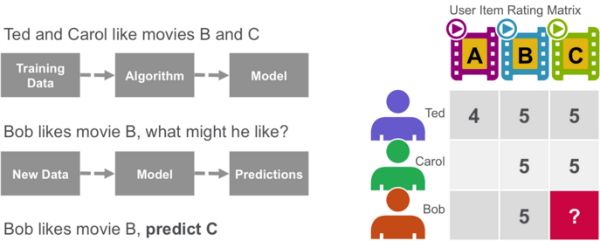
Алгоритмы совместной фильтрации рекомендуют элементы (это часть фильтрации) на основе информации о предпочтениях многих пользователей (это часть для совместной работы). Подход коллективной фильтрации основан на сходстве; люди, которым нравились подобные предметы в прошлом, будут любить подобные предметы в будущем. Целью алгоритма совместной фильтрации является получение данных о предпочтениях от пользователей и создание модели, которая может использоваться для рекомендаций или прогнозов. Тед любит фильмы A, B и C. Кэрол любит фильмы B и C. Мы берем эти данные и используем алгоритм для построения модели. Затем, когда у нас появляются новые данные, например, Бобу нравится фильм B, мы используем модель, чтобы предсказать, что C является возможной рекомендацией для Боба.
Деревья решений
Деревья решений создают модель, которая прогнозирует класс или метку на основе нескольких входных функций. Деревья решений работают, оценивая выражение, содержащее элемент в каждом узле, и выбирая ответвление для следующего узла на основе ответа. Дерево решений для прогнозирования выживания на Титанике показано ниже. Функциональные вопросы — это узлы, а ответы «да» или «нет» — это ветви в дереве для дочерних узлов.
- Q1: секс мужской?
- да
- Q2: возраст> 9,5?
- нет
- Sibsp> 2,5?
- нет
- умер
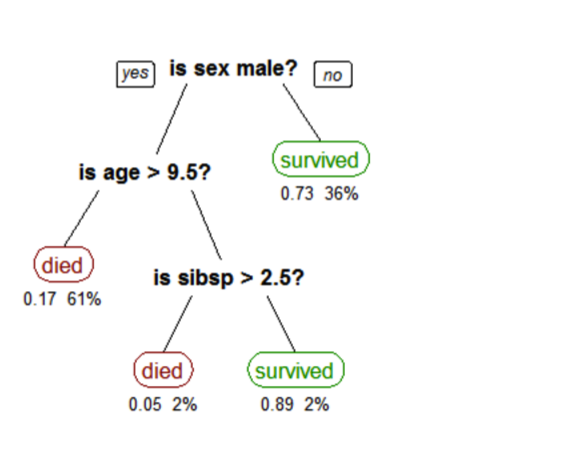
Дерево, показывающее выживание пассажиров на Титанике («сибсп» — это число супругов или братьев и сестер на борту). Цифры под листьями показывают вероятность выживания и процент наблюдений в листе.
Проанализируйте задержки полета с помощью сценария машинного обучения
Наши данные взяты из http://www.transtats.bts.gov/DL_SelectFields.asp?Table_ID=236&DB_Short_Name=On-Time . Мы используем информацию о рейсе за январь 2014 года. Для каждого рейса у нас есть следующая информация:
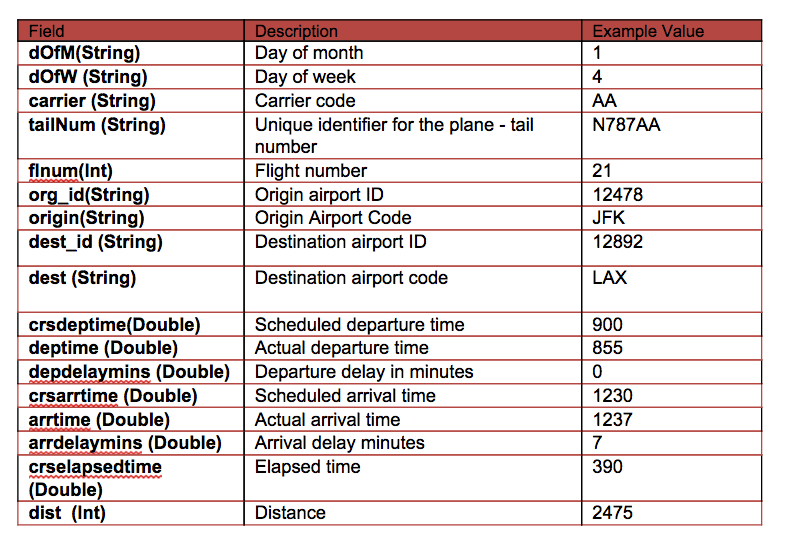
В этом сценарии мы создадим дерево для прогнозирования метки / классификации отложенных или не основанных на следующих функциях:
- Метка → задерживается и не задерживается — задерживается, если задержка> 40 минут
- Особенности → {day_of_month, день недели, crsdeptime, crsarrtime, перевозчик, crselapsedtime, origin, dest, delayed}

Программного обеспечения
Это руководство будет работать в песочнице MapR, в которую входит Spark.
- Вы можете скачать код и данные для запуска этих примеров здесь: https://github.com/caroljmcdonald/sparkmldecisiontree
- Примеры в этом посте можно запустить в оболочке Spark после запуска с помощью команды spark-shell.
- Вы также можете запустить код как отдельное приложение, как описано в руководстве по началу работы с Spark в MapR Sandbox .
Войдите в MapR Sandbox, как описано в разделе Начало работы с Spark в MapR Sandbox , используя идентификатор пользователя user01, пароль mapr. Скопируйте файл примера данных в домашнюю директорию песочницы / user / user01 с помощью scp. Начните искровую оболочку с:
|
1
|
$ spark-shell |
Загрузка и анализ данных из файла CSV
Сначала мы импортируем пакеты машинного обучения. (В полях кода комментарии отображаются зеленым, а вывод — синим)
|
1
2
3
4
5
6
7
8
|
import org.apache.spark._import org.apache.spark.rdd.RDD// Import classes for MLLibimport org.apache.spark.mllib.regression.LabeledPointimport org.apache.spark.mllib.linalg.Vectorsimport org.apache.spark.mllib.tree.DecisionTreeimport org.apache.spark.mllib.tree.model.DecisionTreeModelimport org.apache.spark.mllib.util.MLUtils |
В нашем примере каждый полет — это элемент, и мы используем класс случая Scala для определения схемы полета, соответствующей строке в файле данных csv.
|
1
2
|
// define the Flight Schemacase class Flight(dofM: String, dofW: String, carrier: String, tailnum: String, flnum: Int, org_id: String, origin: String, dest_id: String, dest: String, crsdeptime: Double, deptime: Double, depdelaymins: Double, crsarrtime: Double, arrtime: Double, arrdelay: Double, crselapsedtime: Double, dist: Int) |
Функция ниже анализирует строку из файла данных в классе Flight.
|
1
2
3
4
5
|
// function to parse input into Flight classdef parseFlight(str: String): Flight = { val line = str.split(",") Flight(line(0), line(1), line(2), line(3), line(4).toInt, line(5), line(6), line(7), line(8), line(9).toDouble, line(10).toDouble, line(11).toDouble, line(12).toDouble, line(13).toDouble, line(14).toDouble, line(15).toDouble, line(16).toInt)} |
Мы используем данные о рейсе за январь 2014 года в качестве набора данных. Ниже мы загружаем данные из файла CSV в Resilient Distributed Dataset (RDD) . СДР могут иметь преобразования и действия , действие first () возвращает первый элемент СДР.
|
1
2
3
4
5
6
7
8
9
|
// load the data into a RDDval textRDD = sc.textFile("/user/user01/data/rita2014jan.csv")// MapPartitionsRDD[1] at textFile // parse the RDD of csv lines into an RDD of flight classes val flightsRDD = textRDD.map(parseFlight).cache()flightsRDD.first()//Array(Flight(1,3,AA,N338AA,1,12478,JFK,12892,LAX,900.0,914.0,14.0,1225.0,1238.0,13.0,385.0,2475), |
Особенности извлечения
Чтобы построить модель классификатора, сначала извлеките функции, которые наиболее способствуют классификации. Мы определяем два класса или метки — Да (с задержкой) и Нет (без задержки). Рейс считается задержанным, если он опоздал более чем на 40 минут.
Функции для каждого элемента состоят из полей, показанных ниже:
- Метка → задерживается и не задерживается — задерживается, если задержка> 40 минут
- Особенности → {day_of_month, день недели, crsdeptime, crsarrtime, перевозчик, crselapsedtime, origin, dest, delayed}
Ниже мы преобразуем нечисловые объекты в числовые значения. Например, авиакомпания AA является номером 6. Исходящий ATL аэропорта — 273.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
// create airports RDD with ID and Namevar carrierMap: Map[String, Int] = Map()var index: Int = 0flightsRDD.map(flight => flight.carrier).distinct.collect.foreach(x => { carrierMap += (x -> index); index += 1 })carrierMap.toString//res2: String = Map(DL -> 5, F9 -> 10, US -> 9, OO -> 2, B6 -> 0, AA -> 6, EV -> 12, FL -> 1, UA -> 4, MQ -> 8, WN -> 13, AS -> 3, VX -> 7, HA -> 11)// Defining a default vertex called nowherevar originMap: Map[String, Int] = Map()var index1: Int = 0flightsRDD.map(flight => flight.origin).distinct.collect.foreach(x => { originMap += (x -> index1); index1 += 1 })originMap.toString//res4: String = Map(JFK -> 214, LAX -> 294, ATL -> 273,MIA -> 175 ... // Map airport ID to the 3-letter code to use for printlnsvar destMap: Map[String, Int] = Map()var index2: Int = 0flightsRDD.map(flight => flight.dest).distinct.collect.foreach(x => { destMap += (x -> index2); index2 += 1 }) |
Определить массив объектов
Объекты преобразуются и помещаются в векторы объектов, которые представляют собой векторы чисел, представляющие значение для каждого объекта.
Затем мы создаем RDD, содержащий массивы объектов, состоящие из метки и объектов в числовом формате. Пример показан в этой таблице:

|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
//- Defining the features arrayval mlprep = flightsRDD.map(flight => { val monthday = flight.dofM.toInt - 1 // category val weekday = flight.dofW.toInt - 1 // category val crsdeptime1 = flight.crsdeptime.toInt val crsarrtime1 = flight.crsarrtime.toInt val carrier1 = carrierMap(flight.carrier) // category val crselapsedtime1 = flight.crselapsedtime.toDouble val origin1 = originMap(flight.origin) // category val dest1 = destMap(flight.dest) // category val delayed = if (flight.depdelaymins.toDouble > 40) 1.0 else 0.0 Array(delayed.toDouble, monthday.toDouble, weekday.toDouble, crsdeptime1.toDouble, crsarrtime1.toDouble, carrier1.toDouble, crselapsedtime1.toDouble, origin1.toDouble, dest1.toDouble)})mlprep.take(1)//res6: Array[Array[Double]] = Array(Array(0.0, 0.0, 2.0, 900.0, 1225.0, 6.0, 385.0, 214.0, 294.0)) |
Создать помеченные точки
Из RDD, содержащего массивы объектов, мы создаем RDD, содержащий массивы LabeledPoints . Помеченная точка — это класс, который представляет вектор объектов и метку точки данных.
|
1
2
3
4
|
//Making LabeledPoint of features - this is the training data for the modelval mldata = mlprep.map(x => LabeledPoint(x(0), Vectors.dense(x(1), x(2), x(3), x(4), x(5), x(6), x(7), x(8))))mldata.take(1)//res7: Array[org.apache.spark.mllib.regression.LabeledPoint] = Array((0.0,[0.0,2.0,900.0,1225.0,6.0,385.0,214.0,294.0])) |
Затем данные разделяются, чтобы получить хороший процент задержанных и не задержанных рейсов. Затем он разделяется на набор обучающих данных и набор тестовых данных.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
// mldata0 is %85 not delayed flightsval mldata0 = mldata.filter(x => x.label == 0).randomSplit(Array(0.85, 0.15))(1)// mldata1 is %100 delayed flightsval mldata1 = mldata.filter(x => x.label != 0)// mldata2 is delayed and not delayedval mldata2 = mldata0 ++ mldata1// split mldata2 into training and test dataval splits = mldata2.randomSplit(Array(0.7, 0.3))val (trainingData, testData) = (splits(0), splits(1))testData.take(1)//res21: Array[org.apache.spark.mllib.regression.LabeledPoint] = Array((0.0,[18.0,6.0,900.0,1225.0,6.0,385.0,214.0,294.0])) |
Тренировать модель
Далее мы подготавливаем значения для параметров, которые требуются для дерева решений:
-
categoricalFeaturesInfoкоторая указывает, какие функции являются категориальными и сколько категориальных значений может принимать каждая из этих функций. Первый элемент здесь представляет день месяца и может принимать значения от 0 до 31. Второй элемент представляет день недели и может принимать значения от 1 до 7. Значение носителя может быть от 4 до числа разные носители и тд. -
maxDepth:максимальная глубина дерева. -
maxBins:количество бинов, используемых при дискретизации непрерывных объектов. -
impurity:мера однородности меток в узле.
Модель обучается путем установления связей между входными функциями и помеченными выходными данными, связанными с этими функциями. Мы обучаем модель, используя метод DecisionTree.trainClassifier, который возвращает DecisionTreeModel.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// set ranges for 0=dofM 1=dofW 4=carrier 6=origin 7=destvar categoricalFeaturesInfo = Map[Int, Int]()categoricalFeaturesInfo += (0 -> 31)categoricalFeaturesInfo += (1 -> 7)categoricalFeaturesInfo += (4 -> carrierMap.size)categoricalFeaturesInfo += (6 -> originMap.size)categoricalFeaturesInfo += (7 -> destMap.size)val numClasses = 2// Defning values for the other parametersval impurity = "gini"val maxDepth = 9val maxBins = 7000// call DecisionTree trainClassifier with the trainingData , which returns the modelval model = DecisionTree.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo,impurity, maxDepth, maxBins)// print out the decision treemodel.toDebugString// 0=dofM 4=carrier 3=crsarrtime1 6=origin res20: String = DecisionTreeModel classifier of depth 9 with 919 nodes If (feature 0 in {11.0,12.0,13.0,14.0,15.0,16.0,17.0,18.0,19.0,20.0,21.0,22.0,23.0,24.0,25.0,26.0,27.0,30.0}) If (feature 4 in {0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,13.0}) If (feature 3 <= 1603.0) If (feature 0 in {11.0,12.0,13.0,14.0,15.0,16.0,17.0,18.0,19.0}) If (feature 6 in {0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,10.0,11.0,12.0,13.0... |
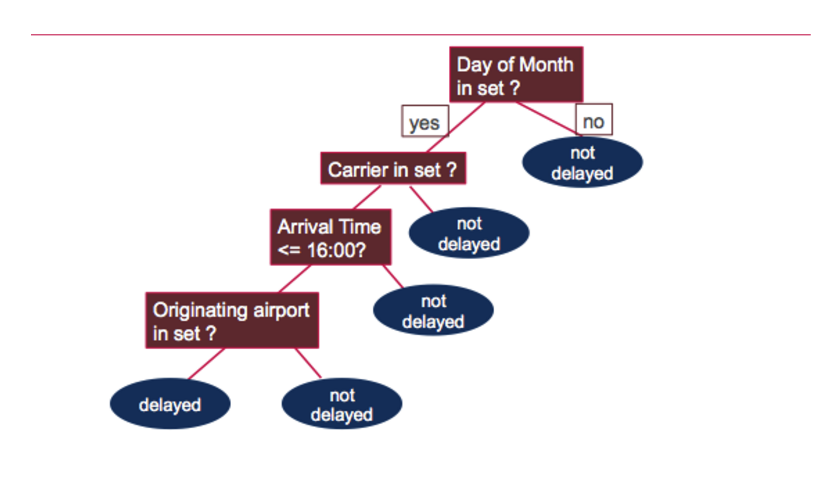
Model.toDebugString распечатывает дерево решений, в котором задаются следующие вопросы, чтобы определить, был ли рейс задержан или нет:
Проверьте модель
Далее мы используем тестовые данные для получения прогнозов. Затем мы сравниваем прогнозы задержки полета с фактическим значением задержки полета, меткой. Отношение неправильных прогнозов — это число неправильных прогнозов / количество значений тестовых данных, которое составляет 31%.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
// Evaluate model on test instances and compute test errorval labelAndPreds = testData.map { point => val prediction = model.predict(point.features) (point.label, prediction)}labelAndPreds.take(3)res33: Array[(Double, Double)] = Array((0.0,0.0), (0.0,0.0), (0.0,0.0))val wrongPrediction =(labelAndPreds.filter{ case (label, prediction) => ( label !=prediction) })wrongPrediction.count()res35: Long = 11040val ratioWrong=wrongPrediction.count().toDouble/testData.count()ratioWrong: Double = 0.3157443157443157 |
Хотите узнать больше?
- Бесплатная тренировка искр по требованию
- http://spark.apache.org/docs/latest/mllib-decision-tree.html
В этом посте мы показали, как начать работу с деревьями решений машинного обучения Apache Spark MLlib для классификации. Если у вас есть какие-либо дополнительные вопросы по этому учебнику, пожалуйста, задавайте их в разделе комментариев ниже.
| Ссылка: | Учебное пособие по машинному обучению Apache Spark от нашего партнера JCG Кэрол Макдональд в блоге Mapr . |