Вступление
Все проекты, над которыми я работал, использовали пул соединений с базой данных, и это по очень веским причинам. Иногда мы можем забыть, почему мы используем один шаблон проектирования или определенную технологию, поэтому стоит отступить и рассуждать об этом. У каждой технологии или технологического решения есть как положительные, так и отрицательные стороны, и если вы не видите каких-либо недостатков, вам нужно задуматься, чего вам не хватает.
Жизненный цикл подключения к базе данных
Каждая операция чтения или записи базы данных требует подключения. Итак, давайте посмотрим, как выглядит поток подключения к базе данных:
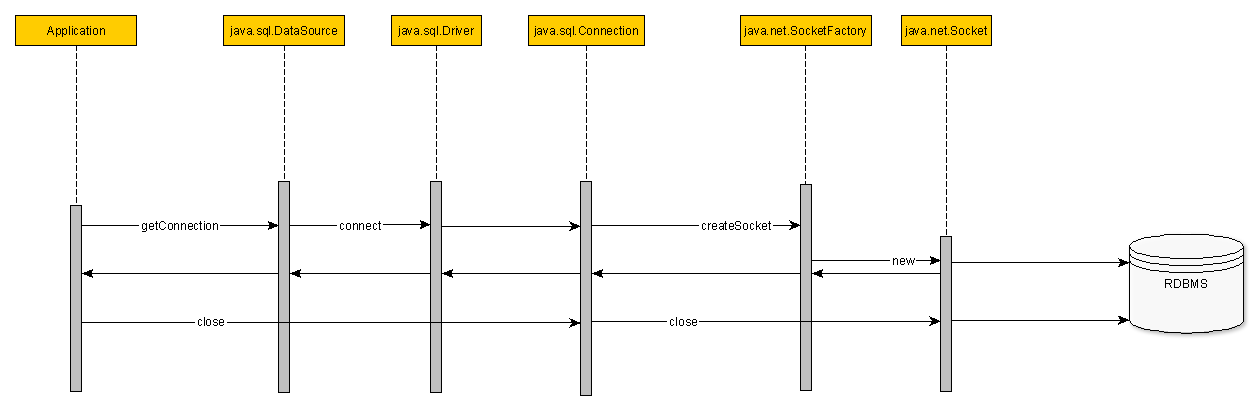
Поток идет так:
- Уровень данных приложения запрашивает источник данных для соединения с базой данных
- Источник данных будет использовать драйвер базы данных, чтобы открыть соединение с базой данных.
- Соединение с базой данных создано и TCP-сокет открыт
- Приложение читает / пишет в базу данных
- Соединение больше не требуется, поэтому оно закрыто
- Розетка закрыта
Вы можете легко сделать вывод, что открытие / закрытие соединений довольно дорогая операция. PostgreSQL использует отдельный процесс ОС для каждого клиентского соединения, поэтому высокая скорость открытия / закрытия соединений будет создавать нагрузку для вашей системы управления базами данных.
Наиболее очевидные причины для повторного использования соединения с базой данных:
- сокращение накладных расходов ввода-вывода ОС системы управления приложениями и базами данных при создании / разрушении TCP-соединения
- уменьшение мусора объекта JVM
Объединение в пул без объединения
Давайте сравним сравнение решения без пула с HikariCP, который, вероятно, является самой быстрой из доступных сред пула соединений .
Тест откроет и закроет 1000 соединений.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
private static final Logger LOGGER = LoggerFactory.getLogger(DataSourceConnectionTest.class);private static final int MAX_ITERATIONS = 1000;private Slf4jReporter logReporter;private Timer timer;protected abstract DataSource getDataSource();@Beforepublic void init() { MetricRegistry metricRegistry = new MetricRegistry(); this.logReporter = Slf4jReporter .forRegistry(metricRegistry) .outputTo(LOGGER) .build(); timer = metricRegistry.timer("connection");}@Testpublic void testOpenCloseConnections() throws SQLException { for (int i = 0; i < MAX_ITERATIONS; i++) { Timer.Context context = timer.time(); getDataSource().getConnection().close(); context.stop(); } logReporter.report();} |
На графике отображается время, затраченное на открытие и закрытие соединений, поэтому чем ниже, тем лучше.
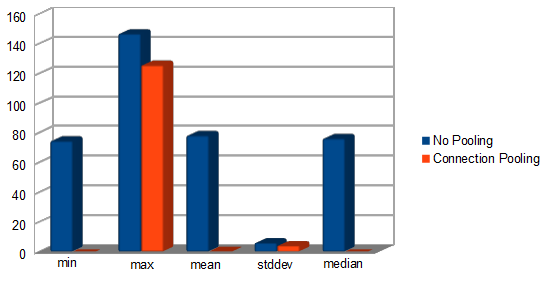
Пул соединений в 600 раз быстрее, чем альтернатива без пула . Наша корпоративная система состоит из десятков приложений, и только одна система пакетного процессора может выдавать более 2 миллионов соединений с базой данных в час, поэтому стоит подумать об оптимизации на 2 порядка.
| Тип | Нет времени объединения (миллисекунды) | Время пула соединений (миллисекунды) |
|---|---|---|
| мин | 74.551414 | 0.002633 |
| Максимум | 146,69324 | 125.528047 |
| жадный | 78.216549 | 0.128900 |
| StdDev | 5.9438335 | 3.969438 |
| медиана | 76.150440 | 0.003218 |
Почему объединение происходит намного быстрее?
Чтобы понять, почему решение для пулов работает так хорошо, нам нужно проанализировать поток управления пулами:
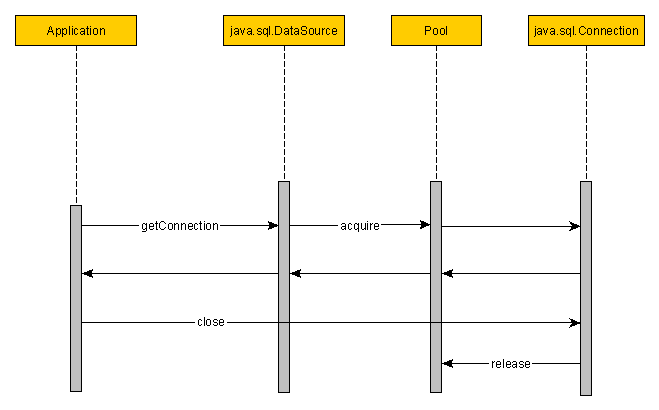
Всякий раз, когда запрашивается соединение, источник данных пула будет использовать доступный пул соединений для получения нового соединения. Пул будет создавать новые соединения только тогда, когда не останется доступных, и пул еще не достиг своего максимального размера. Метод close () соединения пула собирается вернуть соединение в пул, вместо того, чтобы фактически закрывать его.
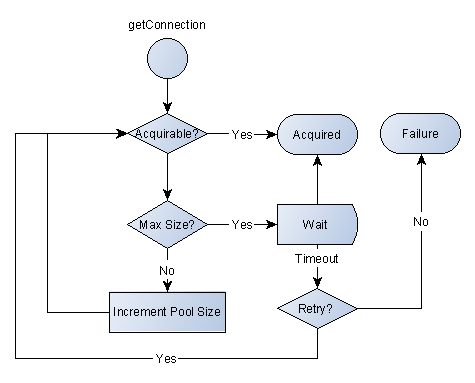
Быстрее и безопаснее
Пул соединений действует как ограниченный буфер для входящих запросов на соединение. Если наблюдается всплеск трафика, пул соединений будет выравнивать его, а не насыщать все доступные ресурсы базы данных.
Шаг ожидания и механизм тайм-аута являются безопасными хуками, предотвращающими чрезмерную нагрузку на сервер базы данных. Если одно приложение получает слишком большой трафик базы данных, пул соединений будет его уменьшать, поэтому он не сможет отключить сервер базы данных (что повлияет на всю систему предприятия).
С большой властью приходит большая ответственность
Все эти преимущества достижимы по цене, реализованной в виде дополнительной сложности конфигурации пула (особенно в крупных корпоративных системах). Так что это не серебряная пуля, и вам нужно обратить внимание на многие настройки пула, такие как:
- минимальный размер
- максимальный размер
- максимальное время простоя
- получить тайм-аут
- попытки повторного тайм-аута
В следующей статье я расскажу о проблемах пула корпоративных подключений и о том, как Flexy Pool поможет вам найти правильный размер пула.
- Код доступен на GitHub .
| Ссылка: | Анатомия Connection Pooling от нашего партнера JCG Влада Михалча в блоге Влада Михалча . |