Вступление
В моем предыдущем посте я говорил о различных стратегиях идентификатора базы данных, которые необходимо учитывать при разработке модели базы данных. Мы пришли к выводу, что последовательности базы данных очень удобны, потому что они гибки и эффективны для большинства случаев использования.
Но даже с кэшированными последовательностями , приложению требуется двустороннее обращение к базе данных для каждого нового значения последовательности. Если вашим приложениям требуется большое количество операций вставки на транзакцию, распределение последовательности может быть оптимизировано с помощью алгоритма hi / lo.
Алгоритм хай-лоу
Алгоритмы hi / lo разбивают область последовательностей на группы «hi». «Привет» значение назначается синхронно. Каждой группе «hi» дается максимальное количество записей «lo», которые могут быть назначены в автономном режиме, не беспокоясь о параллельных повторяющихся записях.
- Токен «hi» назначается базой данных, и два одновременных вызова гарантированно видят уникальные последовательные значения
- После получения токена «hi» нам нужен только «incrementSize» (количество записей «lo»)
- Диапазон идентификаторов задается следующей формулой:
- Когда используются все значения «lo», выбирается новое значение «hi» и цикл продолжается
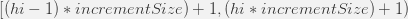
и значение «lo» будет взято из:
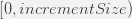
начиная с:
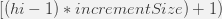
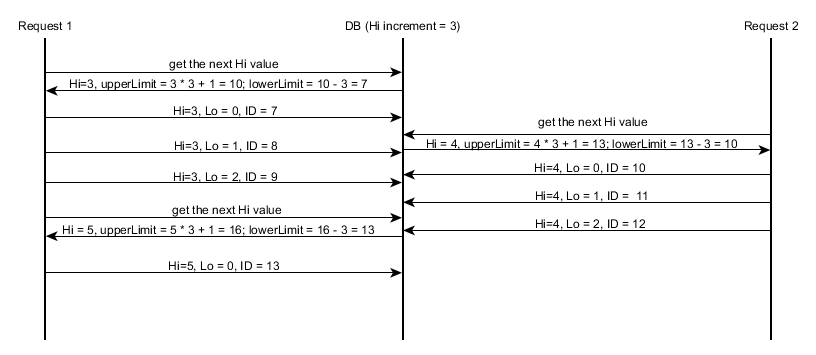
Здесь вы можете получить пример двух одновременных транзакций, каждая из которых вставляет несколько сущностей:
Проверка теории
Если у нас есть следующий объект:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
@Entitypublic class Hilo { @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "hilo_sequence_generator") @GenericGenerator( name = "hilo_sequence_generator", strategy = "org.hibernate.id.enhanced.SequenceStyleGenerator", parameters = { @Parameter(name = "sequence_name", value = "hilo_seqeunce"), @Parameter(name = "initial_value", value = "1"), @Parameter(name = "increment_size", value = "3"), @Parameter(name = "optimizer", value = "hilo") }) @Id private Long id;} |
Мы можем проверить, сколько обходов последовательности базы данных выдается при вставке нескольких объектов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
@Testpublic void testHiloIdentifierGenerator() { doInTransaction(new TransactionCallable<Void>() { @Override public Void execute(Session session) { for(int i = 0; i < 8; i++) { Hilo hilo = new Hilo(); session.persist(hilo); session.flush(); } return null; } });} |
Какие элементы генерируют следующие SQL-запросы:
|
01
02
03
04
05
06
07
08
09
10
11
|
Query:{[call next value for hilo_seqeunce][]} Query:{[insert into Hilo (id) values (?)][1]} Query:{[insert into Hilo (id) values (?)][2]} Query:{[insert into Hilo (id) values (?)][3]} Query:{[call next value for hilo_seqeunce][]} Query:{[insert into Hilo (id) values (?)][4]} Query:{[insert into Hilo (id) values (?)][5]} Query:{[insert into Hilo (id) values (?)][6]} Query:{[call next value for hilo_seqeunce][]} Query:{[insert into Hilo (id) values (?)][7]} Query:{[insert into Hilo (id) values (?)][8]} |
Как видите, у нас есть только 3 последовательных вызова для 8 вставленных объектов. Чем больше сущностей вставит транзакцию, тем нам потребуется больший прирост производительности, который мы получим благодаря уменьшению количества обращений к последовательности базы данных.
| Ссылка: | Алгоритм hi / lo от нашего партнера JCG Влада Михалча в блоге Влада Михалча . |