В этом уроке я покажу вам, как создать собственную поисковую систему SitePoint, которая намного превосходит все, что WordPress мог когда-либо выпустить. Мы будем использовать Diffbot как сервис для автоматического извлечения структурированных данных из SitePoint, а этот соответствующий API-клиент будет выполнять поиск и сканирование.

Я также буду использовать свою надежную среду Homestead Improved для чистого проекта, поэтому я могу экспериментировать на виртуальной машине, которая посвящена этому проекту и только этому проекту.
Что к чему?
Чтобы создать поисковую систему SitePoint, нам нужно сделать следующее:
- Создайте Crawljob, который будет индексировать и обрабатывать весь домен SitePoint.com и постоянно обновлять публикуемый контент.
- Создайте графический интерфейс для отправки поисковых запросов в сохраненный набор, созданный этим обходом. Поиск осуществляется через API поиска . Мы сделаем это в следующем посте.
Diffbot Crawljob выполняет следующие действия:
- Это паук шаблон URL для URL. Это не означает обработку — это означает поиск ссылок для обработки на всех страницах, которые он может найти, начиная с домена, который вы изначально передали в качестве начального числа . Разницу между сканированием и обработкой см. Здесь .
- Он обрабатывает страницы, найденные по указанным URL-адресам, с помощью назначенного механизма API — например, используя Product API, обрабатывает все продукты, найденные на Amazon.com, и сохраняет их в структурированной базе данных предлагаемых товаров.
Создание Crawljob
Задания могут быть созданы с помощью графического интерфейса Diffbot, но я считаю, что создание их с помощью API обхода контента является более настраиваемым. В пустой папке давайте сначала установим клиентскую библиотеку.
composer require swader/diffbot-php-client Теперь мне нужен файл job.php в который я просто дам дамп процедуры создания задания согласно README :
include 'vendor/autoload.php'; use Swader\Diffbot\Diffbot; $diffbot = new Diffbot('my_token');
Экземпляр Diffbot используется для создания точек доступа к типам API, предлагаемым Diffbot. В нашем случае необходим тип «Сканирование». Давайте назовем это «sp_search».
$job = $diffbot->crawl('sp_search');
Это создаст новый crawljob при call() метода call() . Далее нам нужно настроить работу. Во-первых, нам нужно дать ему начальный URL-адрес (ы), с которого нужно начать процесс паутинга:
$job ->setSeeds(['http://sitepoint.com'])
Затем мы уведомляем нас о завершении сканирования, чтобы точно знать, когда завершен цикл сканирования, и мы можем ожидать, что в наборе данных будет находиться актуальная информация.
$job ->setSeeds(['http://sitepoint.com']) ->notify('bruno.skvorc@sitepoint.com')
Сайт может иметь сотни тысяч ссылок на паука и сотни тысяч страниц для обработки — максимальные ограничения являются механизмом контроля затрат, и в этом случае я хочу получить максимально подробный набор из доступных для меня, поэтому я ‘ Я добавлю миллион URL в оба значения.
$job ->setSeeds(['http://sitepoint.com']) ->notify('bruno.skvorc@sitepoint.com') ->setMaxToCrawl(1000000) ->setMaxToProcess(1000000)
Мы также хотим, чтобы эта работа обновлялась каждые 24 часа, потому что мы знаем, что SitePoint публикует несколько новых сообщений каждый день. Важно отметить, что повторение означает «с момента окончания последнего раунда» — поэтому, если для завершения работы требуется 24 часа, новый раунд сканирования фактически начнется через 48 часов с начала предыдущего раунда. Мы установим максимальное количество раундов равным 0, чтобы указать, что мы хотим, чтобы это повторялось бесконечно.
$job ->setSeeds(['http://sitepoint.com']) ->notify('bruno.skvorc@sitepoint.com') ->setMaxToCrawl(1000000) ->setMaxToProcess(1000000) ->setRepeat(1) ->setMaxRounds(0)
Наконец, есть шаблон обработки страниц. Когда Diffbot обрабатывает страницы во время сканирования, только те, которые обработаны — не просканированы — фактически оплачиваются / учитываются до вашего лимита. Поэтому в наших интересах быть как можно более конкретными с определением нашего crawljob, чтобы не обрабатывать страницы, которые не являются статьями — например, авторские биографии, объявления или даже списки категорий. Поиск <section class="article_body"> должен сделать — у каждого сообщения есть это. И, конечно же, мы хотим, чтобы он обрабатывал только те страницы, с которыми ранее не сталкивался в каждом новом раунде — не нужно извлекать одни и те же данные снова и снова, это просто увеличит расходы.
$job ->setSeeds(['http://sitepoint.com']) ->notify('bruno.skvorc@sitepoint.com') ->setMaxToCrawl(1000000) ->setMaxToProcess(1000000) ->setRepeat(1) ->setMaxRounds(0) ->setPageProcessPatterns(['<section class="article_body">']) ->setOnlyProcessIfNew(1)
Прежде чем закончить настройку сканирования, нужно добавить еще один важный параметр — шаблон сканирования. При передаче начального URL в Crawl API, Crawljob также будет проходить по всем поддоменам. Так что, если мы перейдем на http://sitepoint.com , Crawlbot будет просматривать http://community.sitepoint.com , а теперь уже устаревший http://reference.sitepoint.com — это то, чего мы хотим избежать, так как это резко замедлит наш процесс сканирования и приведет к сбору ненужного материала (мы не хотим, чтобы форумы были проиндексированы прямо сейчас). Чтобы настроить это, мы используем метод setUrlCrawlPatterns , указывающий, что setUrlCrawlPatterns ссылки должны начинаться с sitepoint.com .
$job ->setSeeds(['http://sitepoint.com']) ->notify('bruno.skvorc@sitepoint.com') ->setMaxToCrawl(1000000) ->setMaxToProcess(1000000) ->setRepeat(1) ->setMaxRounds(0) ->setPageProcessPatterns(['<section class="article_body">']) ->setOnlyProcessIfNew(1) ->setUrlCrawlPatterns(['^http://www.sitepoint.com', '^http://sitepoint.com'])
Теперь нам нужно сообщить заданию, какой API использовать для обработки. Мы могли бы использовать по умолчанию — Analyze API — который заставил бы Diffbot автоматически определять структуру данных, которые мы пытаемся получить, но я предпочитаю конкретность и хочу, чтобы он сразу знал, что он должен производить только статьи.
$api = $diffbot->createArticleAPI('crawl')->setMeta(true)->setDiscussion(false); $job->setApi($api);
Обратите внимание, что с отдельными API-интерфейсами (такими как «Продукт», «Статья», «Обсуждение» и т. Д.) Вы можете обрабатывать отдельные ресурсы даже с помощью бесплатного демо-токена от Diffbot.com, который позволяет протестировать ваши ссылки и посмотреть, какие данные они будут возвращать раньше. погружение в массовую обработку через Crawlbot. Информацию о том, как это сделать, смотрите в файле README .
Теперь задание настроено, и мы можем call() Diffbot с инструкциями по его созданию:
$job->call();
Полный код для создания этой работы:
$diffbot = new Diffbot('my_token'); $job = $diffbot->crawl('sp_search'); $job ->setSeeds(['http://sitepoint.com']) ->notify('bruno.skvorc@sitepoint.com') ->setMaxToCrawl(1000000) ->setMaxToProcess(1000000) ->setRepeat(1) ->setMaxRounds(0) ->setPageProcessPatterns(['<section class="article_body">']) ->setOnlyProcessIfNew(1) ->setApi($diffbot->createArticleAPI('crawl')->setMeta(true)->setDiscussion(false)) ->setUrlCrawlPatterns(['^http://www.sitepoint.com', '^http://sitepoint.com']); $job->call();
Вызов этого скрипта из командной строки ( php job.php ) или открытие его в браузере создало задание — его можно увидеть на экране разработчика Crawlbot :
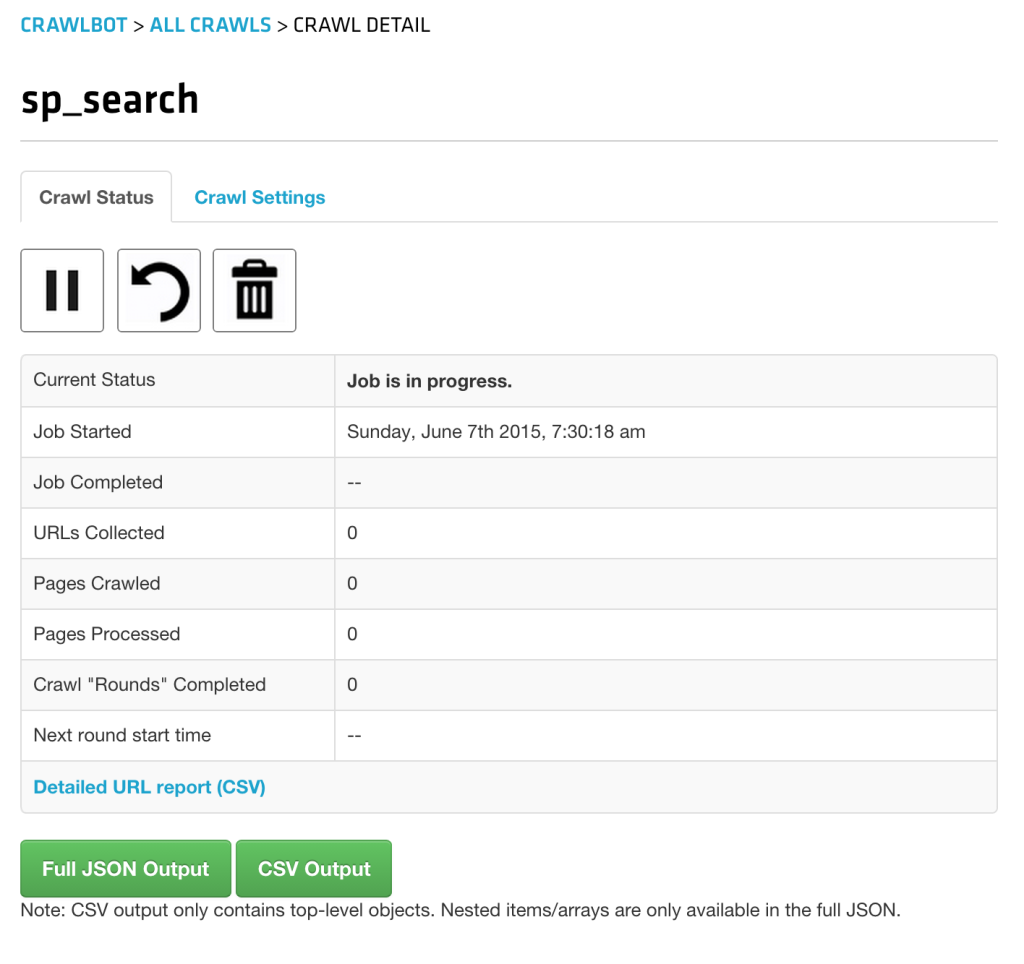
Это займет некоторое время (фактически, дни — SitePoint — огромное место), но все последующие раунды будут быстрее, потому что мы сказали, что нужно обрабатывать только те страницы, с которыми раньше не сталкивались.
Поиск
Для поиска в наборе данных нам нужно использовать API поиска. Набор данных можно использовать даже до его завершения — API-интерфейс поиска будет просто выполнять поиск по имеющимся данным, игнорируя тот факт, что у него нет всего.
Чтобы использовать API поиска, необходимо создать новый экземпляр поиска с поисковым запросом в качестве параметра конструктора:
$search = $diffbot->search(); $search->setCol('sp_search'); $result = $search->call();
Метод setCol является необязательным, и если он опущен, API поиска будет проходить через все коллекции в рамках одного токена Diffbot. Поскольку у меня есть несколько коллекций из моих предыдущих экспериментов, я решил указать последний созданный нами: sp_search (коллекции делятся именами с заданиями, которые их создали).
Возвращенные данные могут быть повторены, и каждый элемент будет экземпляром Article. Вот элементарная таблица, отображающая ссылки и заголовки:
<table> <thead> <tr> <td>Title</td> <td>Url</td> </tr> </thead> <tbody> <?php foreach ($search as $article) { echo '<tr>'; echo '<td>' . $article->getTitle() . '</td>'; echo '<td><a href="' . $article->getResolvedPageUrl() . '">Link</a></td>'; echo '</tr>'; } ?> </tbody> </table>

API поиска может возвращать удивительно точно настроенные наборы результатов. Параметр query будет принимать все: от общих ключевых слов до диапазонов дат, до целевых определенных полей (например, title:diffbot ) до логических комбинаций различных параметров, таких как type:article AND title:robot AND (overlord OR butler) , производя все статьи, которые в заголовке должно быть слово «робот», а в любом из полей (заголовок, тело, мета-теги и т. д.) слово «повелитель» или «дворецкий». Мы будем использовать все эти расширенные функциональные возможности в следующем посте, когда будем создавать графический интерфейс нашей поисковой системы.
Мы также можем получить «мета» информацию о поисковом API-запросе, передав true в call() после выполнения исходного вызова:
$info = $search->call(true); dump($info);
В результате мы получаем объект SearchInfo со значениями, как показано ниже (все доступны через геттеры):
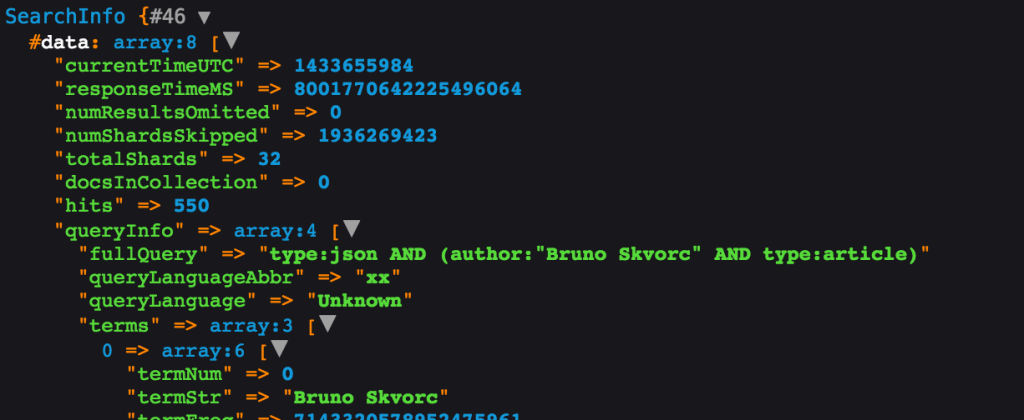
С SearchInfo вы получаете доступ к скорости вашего запроса, количеству обращений (не возвращенные результаты, а общее количество — полезно для разбивки на страницы) и т. Д.
Чтобы получить информацию о конкретном задании на сканирование, например, узнать его текущее состояние или сколько страниц было просканировано, обработано и т. Д., Мы можем снова вызвать API crawl и просто передать то же имя задания. Затем эта операция работает только для чтения и возвращает всю мета-информацию о нашей работе:
dump($diffbot->crawl('sp_search')->call());
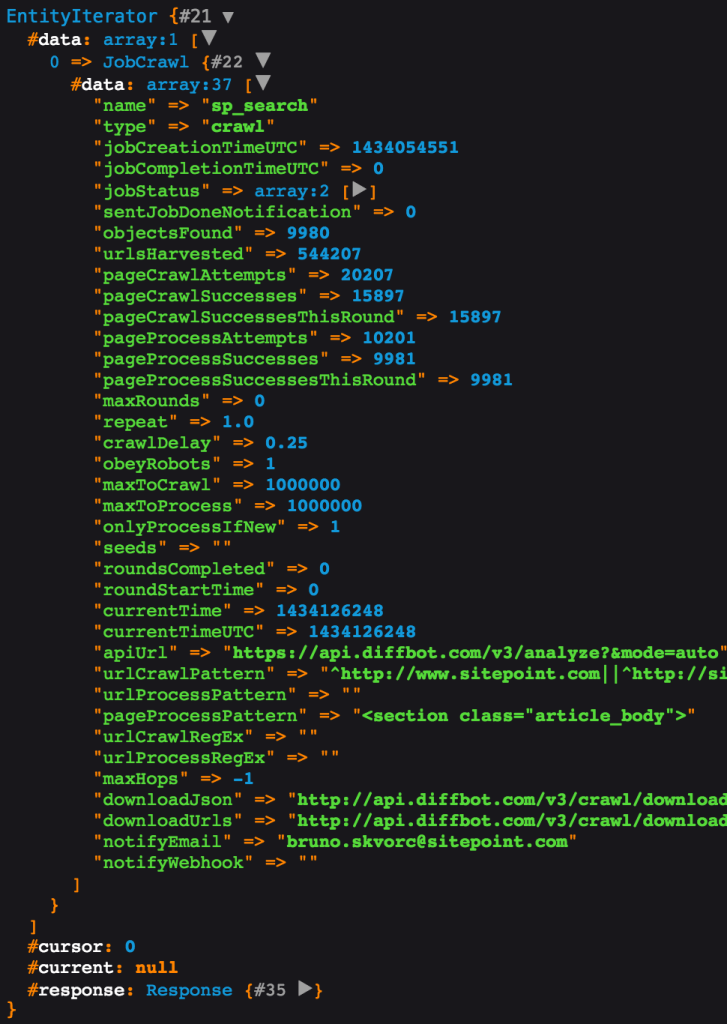
На данный момент наша коллекция заполнена данными для сканирования с SitePoint.com. Теперь все, что нам нужно сделать, это построить графический интерфейс пользователя на основе функции поиска клиента Diffbot API, и это именно то, что мы собираемся сделать в следующей части.
Вывод
В этом руководстве мы рассмотрели способность Diffbot генерировать коллекции структурированных данных из веб-сайтов произвольного формата и его API-интерфейс поиска, который можно использовать в качестве поисковой системы для просканированного сайта. Хотя цена может быть несколько выше, чем для среднего одиночного разработчика, для команд и компаний этот инструмент — находка.
Представьте себе медиа-конгломерат с десятками или сотнями различных веб-сайтов под вашим поясом, и вам нужен каталог со всем вашим контентом. Консолидация усилий всех этих бэкэнд-команд не только придумать способ объединения баз данных, но и найти время, чтобы сделать это в своих ежедневных усилиях (которые включают поддержание их устаревших веб-сайтов), была бы невозможной и очень дорогой задачей, но с Diffbot вы запускаете Crawlbot на всех своих доменах и просто используете API поиска, чтобы просмотреть то, что было возвращено. Более того, данные, которые вы сканируете, полностью загружаются в виде полезной нагрузки JSON, поэтому, даже если это будет слишком дорого, вы всегда сможете импортировать данные в собственное решение.
Важно отметить, что не многие веб-сайты соглашаются на сканирование, поэтому вам, вероятно, следует ознакомиться с их условиями обслуживания, прежде чем пытаться использовать его на сайте, который вам не принадлежит — сканирование может довольно быстро увеличить затраты на серверы и украсть их контент. для личного использования без разрешения вы также лишаете их потенциального дохода от рекламы и других источников дохода, связанных с сайтом.
Во второй части мы рассмотрим, как мы можем превратить все, что у нас есть, в графический интерфейс, чтобы обычный Джо мог легко использовать его в качестве углубленной поисковой системы SitePoint.
Если у вас есть какие-либо вопросы или комментарии, пожалуйста, оставьте их ниже!