В прошлой статье хеширование паролей обсуждалось как способ безопасного хранения учетных данных пользователя в приложении. Безопасность — это всегда очень спорная тема, во многом похожая на политику и религию, где существует множество точек зрения, и «идеальное решение» для кого-то не то же самое, что и для других. На мой взгляд, нарушение мер безопасности приложения — это вопрос времени. С ростом мощности и сложности компьютеров с каждым днем современные безопасные приложения не будут такими уж безопасными завтра.
Для наших читателей, которые не знакомы с алгоритмом хеширования, это не более чем односторонняя функция, которая отображает данные переменной длины на данные фиксированной длины . Поэтому, если мы проанализируем приведенное выше определение, нам нужно понять следующие требования и характеристики таких алгоритмов:
- Односторонняя функция : вывод не может быть обращен с помощью эффективного алгоритма.
- Сопоставляет данные переменной длины с данными фиксированной длины : это означает, что пространство входного сообщения может быть «бесконечным», а пространство вывода — нет. Это означает, что 2 или более входных сообщения могут иметь одинаковый хэш. Чем меньше выходное пространство, тем больше вероятность «столкновения» между двумя входными сообщениями.
md5 подтвердил практические коллизии, и вероятности sha1 для достижения коллизии растут с каждым днем (больше информации о вероятности коллизий можно найти, анализируя классическую проблему дня рождения ), поэтому, если нам нужно применить алгоритм хэширования, мы должны использовать с большим выходным пространством (и незначительной вероятностью столкновения), например sha256, sha512 , джакузи и т. д.
Они также называются « псевдослучайными функциями» , что означает, что выходные данные хэш-функции должны быть неотличимы от генератора истинных случайных чисел (или TRNG).
Почему простое хеширование небезопасно для хранения паролей
Тот факт, что выходные данные хеш-функции не могут быть возвращены обратно к входным данным с использованием эффективного алгоритма, не означает, что они не могут быть взломаны. Базы данных, содержащие хеши общих слов и короткие строки, обычно находятся в пределах досягаемости благодаря простому поиску в Google. Кроме того, обычные строки можно легко и быстро перебором или взломать с помощью словарной атаки.
демонстрация
Вот краткое видео о том, как такой инструмент, как sqlmap, может взломать пароли с помощью инъекции sql путем подбора хешей md5
Кроме того, мы могли бы просто выполнить простейшие атаки … просто захватить хеш и погуглить его … Скорее всего, хеш существует в онлайн-базе данных. Примеры хеш-баз данных:
- http://www.hash-database.net/
- https://isc.sans.edu/tools/hashsearch.html
- http://md5online.net/
- https://crackstation.net/
Мы также должны учитывать, что, поскольку 2 или более идентичных пароля действительно будут иметь одинаковое значение хеша, взлом одного хеша автоматически даст вам пароли каждого отдельного пользователя, который использовал один и тот же. Просто для ясности, скажем, у вас есть тысячи пользователей, весьма вероятно, что значительное количество из них будет использовать (если политики паролей не применяются) позорный пароль «123456». Хеш-значение md5 для этого пароля равно ‘e10adc3949ba59abbe56e057f20f883e’, поэтому, когда вы взломаете этот хеш (если вам даже придется) и выполните поиск всех пользователей, которые имеют это значение в своем поле пароля, вы будете знать, что каждый из них использовал пароль «123456».
Почему соленые хэши небезопасны для хранения паролей
Чтобы смягчить эту атаку, соли стали обычным явлением, но, очевидно, их недостаточно для современных вычислительных мощностей, особенно если строка соли короткая, что делает ее грубой силой.
Основная функция пароля / соли определяется как:
f(password, salt) = hash(password + salt)
Чтобы смягчить атаку методом «грубой силы», соль должна быть длиной до 64 символов, однако для дальнейшей аутентификации пользователя соль должна храниться в виде простого текста внутри базы данных, поэтому:
if (hash([provided password] + [stored salt]) == [stored hash]) then user is authenticated
Поскольку у каждого пользователя будет совершенно другая соль, это также позволяет избежать проблемы с простыми хэшами, где мы могли бы легко определить, используют ли 2 или более пользователей один и тот же пароль; теперь хэши будут другими. Мы также больше не можем напрямую брать хэш пароля и пытаться его найти. Кроме того, с длинной солью атака грубой силой маловероятна. Но если злоумышленник получит доступ к этой соли с помощью SQL-инъекции или прямого доступа к базе данных, вероятна атака методом перебора или словаря, особенно если ваши пользователи используют общие пароли (опять же, например, «123456»):
Generate some string or get entry from dictionary
Concatenate with salt
Apply hash algorithm
If generated hash == hash in database then Bingo
else continue iterating
Но даже если один пароль будет взломан, он не даст вам автоматически пароль для каждого пользователя, который мог его использовать, поскольку ни один пользователь не должен иметь такой же сохраненный хэш.
Случайность вопроса
Чтобы получить хорошую соль, у нас должен быть хороший генератор случайных чисел. Если функция php rand()
В random.org есть отличная статья о случайности. Проще говоря, компьютер не может думать о случайных данных сам по себе. Считается, что компьютеры являются детерминированными машинами , и это означает, что каждый алгоритм, который может запустить компьютер при одинаковом входном сигнале, всегда будет давать один и тот же результат.
Когда на компьютер запрашивается случайное число, оно обычно получает данные из нескольких источников, таких как переменные среды (дата, время, количество прочитанных / записанных байтов, время безотказной работы…), а затем применяет к ним некоторые вычисления для получения случайных данных. По этой причине случайные данные, предоставляемые алгоритмом, называются псевдослучайными, и поэтому важно отличать их от истинного источника случайных данных. Если мы каким-то образом сможем воссоздать точные условия, присутствующие в момент выполнения генератора псевдослучайных чисел (или PRNG), мы автоматически получим исходное сгенерированное число.
Кроме того, если PRNG не реализован должным образом, можно обнаружить шаблоны в сгенерированных данных. Если шаблоны существуют, мы можем предсказать результат … Возьмем, к примеру, случай PHP-функции rand()здесь . Хотя не ясно, какая версия PHP или Windows используется, вы можете сразу сказать, что что-то не так, посмотрев на растровое изображение, сгенерированное с помощью rand()

Сравните с выходным изображением из TRNG:

Несмотря на то, что проблема была решена в PHP> = 5, rand()mt_rand()
Если вам нужно сгенерировать случайные данные, используйте openssl_random_pseudo_bytes() доступную с PHP 5> = 5.3.0, у него даже есть флаг crypto_strong
Вот быстрый пример кода для генерации случайных строк с использованием openssl_random_pseudo_bytes()
<?php
function getRandomBytes ($byteLength)
{
/*
* Checks if openssl_random_pseudo_bytes is available
*/
if (function_exists('openssl_random_pseudo_bytes')) {
$randomBytes = openssl_random_pseudo_bytes($byteLength, $cryptoStrong);
if ($cryptoStrong)
return $randomBytes;
}
/*
* if openssl_random_pseudo_bytes is not available or its result is not
* strong, fallback to a less secure RNG
*/
$hash = '';
$randomBytes = '';
/*
* On linux/unix systems, /dev/urandom is an excellent entropy source, use
* it to seed initial value of $hash
*/
if (file_exists('/dev/urandom')) {
$fp = fopen('/dev/urandom', 'rb');
if ($fp) {
if (function_exists('stream_set_read_buffer')) {
stream_set_read_buffer($fp, 0);
}
$hash = fread($fp, $byteLength);
fclose($fp);
}
}
/*
* Use the less secure mt_rand() function, but never rand()!
*/
for ($i = 0; $i < $byteLength; $i ++) {
$hash = hash('sha256', $hash . mt_rand());
$char = mt_rand(0, 62);
$randomBytes .= chr(hexdec($hash[$char] . $hash[$char + 1]));
}
return $randomBytes;
}
Растяжение пароля может быть эффективным, если все сделано правильно
Для дальнейшего смягчения атак методом перебора мы можем внедрить технику растягивания пароля. Это просто итеративный или рекурсивный алгоритм, который вычисляет значение хеш-функции само по себе, обычно десятки тысяч раз (или больше).
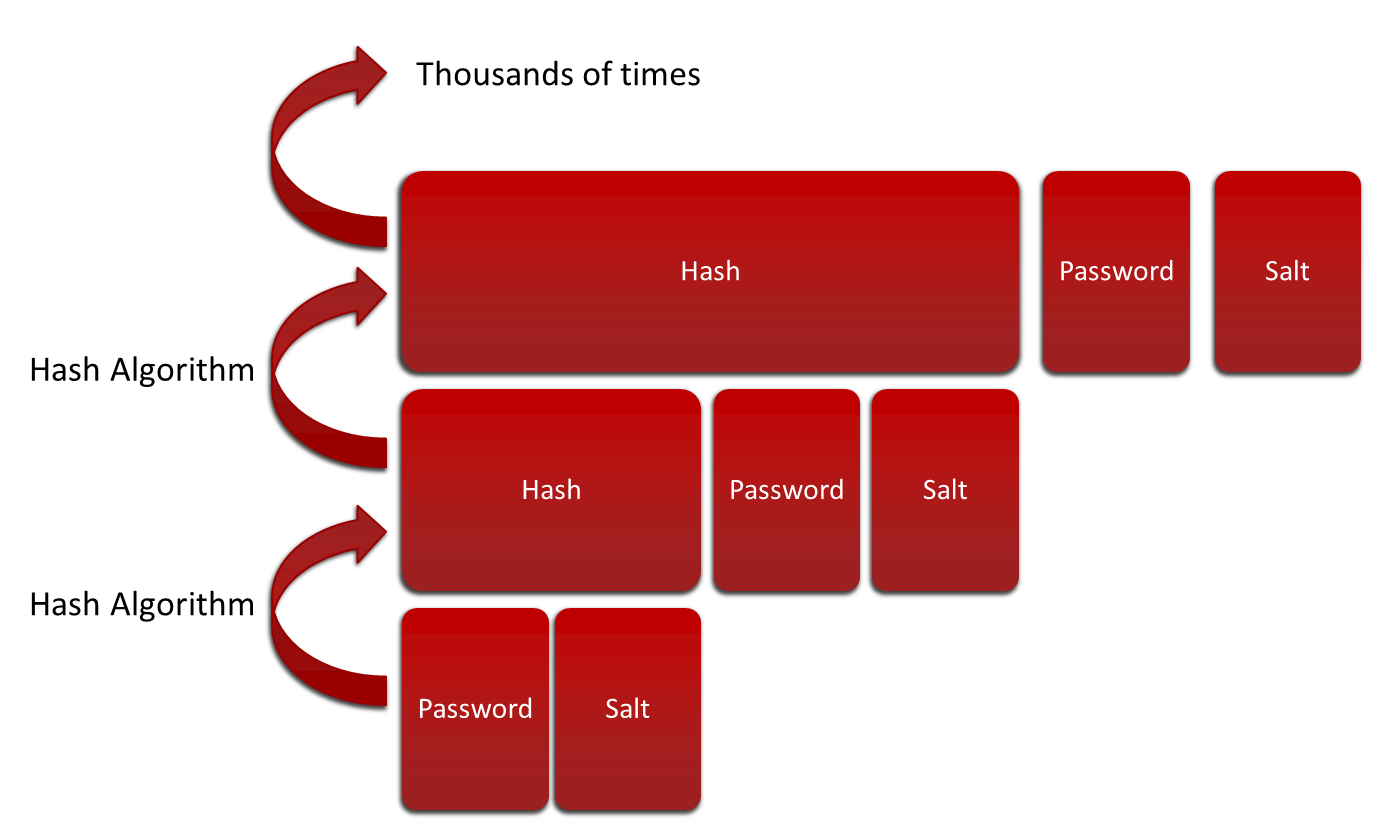
Этот алгоритм должен выполнять итерацию, достаточную для выполнения всех вычислений не менее чем за 1 секунду (более медленное хеширование также означает, что атакующему придется ждать)
Чтобы взломать пароль, защищенный растяжением, злоумышленник должен:
- Знайте точный счетчик итераций, любое отклонение приведет к совершенно другим хэшам.
- Следует подождать не менее 1 секунды между каждой попыткой.
Это делает атаку невероятной … но не невозможной. Чтобы преодолеть задержку в 1 секунду, злоумышленник должен иметь более высокие характеристики оборудования, чем компьютер, для которого был настроен алгоритм, что может означать высокую стоимость, поэтому атака становится чрезмерно дорогой.
Вы также можете использовать стандартные алгоритмы, такие как PBKDF2, который является функцией получения ключа на основе пароля
<?php
/*
* PHP PBKDF2 implementation The number of rounds can be increased to keep ahead
* of improvements in CPU/GPU performance. You should use a different salt for
* each password (it's safe to store it alongside your generated password This
* function is slow; that's intentional! For more information see: -
* http://en.wikipedia.org/wiki/PBKDF2 - http://www.ietf.org/rfc/rfc2898.txt
*/
function pbkdf2 ($password, $salt, $rounds = 15000, $keyLength = 32,
$hashAlgorithm = 'sha256', $start = 0)
{
// Key blocks to compute
$keyBlocks = $start + $keyLength;
// Derived key
$derivedKey = '';
// Create key
for ($block = 1; $block <= $keyBlocks; $block ++) {
// Initial hash for this block
$iteratedBlock = $hash = hash_hmac($hashAlgorithm,
$salt . pack('N', $block), $password, true);
// Perform block iterations
for ($i = 1; $i < $rounds; $i ++) {
// XOR each iteration
$iteratedBlock ^= ($hash = hash_hmac($hashAlgorithm, $hash,
$password, true));
}
// Append iterated block
$derivedKey .= $iteratedBlock;
}
// Return derived key of correct length
return base64_encode(substr($derivedKey, $start, $keyLength));
}
Существуют также алгоритмы, интенсивно использующие время и память, такие как bcrypt (через функцию crypt()
<?php
//bcrypt is implemented in php's crypt() function
$hash = crypt($pasword, '$2a$' . $cost . '$' . $salt);
Где $cost$salt
Коэффициент рабочей нагрузки полностью зависит от целевой системы. Вы можете начать с коэффициента «09» и увеличивать его до завершения операции прибл. 1 секунда.
Начиная с PHP 5> = 5.5.0 вы можете использовать новую функцию password_hash() , которая использует bcrypt в качестве метода хеширования по умолчанию.
В PHP пока нет поддержки scrypt, но вы можете проверить реализацию scrypt в Domblack .
Как насчет применения методов шифрования?
Хеширование и шифрование (или шифрование ) — это термины, которые часто путают. Как я упоминал ранее, хеширование — это псевдослучайная функция, тогда как шифрование — это, как правило, «псевдослучайная перестановка» . Это означает, что входное сообщение разрезано и изменено таким образом, что выход неотличим от TRNG, однако выход МОЖЕТ быть снова преобразован обратно в исходный вход. Это преобразование выполняется с использованием ключа шифрования, без которого невозможно снова преобразовать вывод в исходное сообщение.
У шифрования есть еще одна большая разница по сравнению с хешированием. Хотя пространство выходных сообщений хеширования конечно, пространство шифрования выходных сообщений бесконечно, так как отношение между входом и выходом составляет 1: 1, таким образом, коллизии не должны существовать.
Нужно быть очень осторожным в том, как правильно применять методы шифрования, думая, что простого применения алгоритма шифрования к конфиденциальным данным достаточно для обеспечения их безопасности, считается неправильным, поскольку существует много проблем, которые могут привести к утечке данных. Как правило, вы никогда не должны рассматривать применение собственной реализации шифрования
Недавно у Adobe произошла массовая утечка данных из базы данных их пользователей, поскольку они неправильно применяли методы шифрования, и я приведу их в качестве примера того, чего не следует делать. Я постараюсь быть как можно более прямолинейным, делая вещи по-настоящему простыми.
Рассмотрим следующую схему:
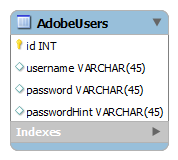
Допустим, текстовое содержимое таблицы выглядит следующим образом:

Теперь кто-то в Adobe решил зашифровать пароли, но сделал две большие ошибки:
- Использовать тот же ключ шифрования для шифрования паролей
- Решили оставить поле подсказки пароля в виде обычного текста.
Скажем, например, что после применения алгоритма шифрования к полю пароля, теперь наши данные выглядят следующим образом:

Хотя пароли не могут быть просто расшифрованы, и мы не можем знать, какой ключ шифрования используется простым способом, изучая данные, мы можем заметить, что записи 2 и 7 используют один и тот же пароль, а также 3 и 6… Вот где поле подсказки пароля вступает в игру.
Подсказка к записи 6 — «Я один!», Которая не дает нам много информации, однако подсказка к записи 3 делает… мы можем смело предположить, что пароль — «королева» . Подсказки из записей 2 и 7 не дают много информации в отдельности, но если мы посмотрим на них вместе, сколько праздников будет иметь то же название, что и страшный фильм? Теперь у нас есть доступ ко всем аккаунтам, которые использовали «Хэллоуин» в качестве пароля.
Чтобы снизить риск утечки данных, лучше перейти на методы хеширования, однако, если вам необходимо использовать методы шифрования для хранения паролей, мы можем использовать настраиваемое шифрование . Термин выглядит причудливо, но очень просто.
Допустим, у нас тысячи пользователей, и мы хотим зашифровать все пароли. Как мы видели, мы не можем использовать один и тот же ключ шифрования для каждого пароля, так как данные будут подвергаться риску (и возможны другие сложные атаки). Однако мы не можем использовать уникальный ключ для каждого пользователя, так как хранение этих ключей само по себе представляет угрозу безопасности. Нам нужно сгенерировать один ключ и использовать «твик», который будет уникальным для каждого пользователя, и ключ, и твик вместе будут ключом шифрования для каждой записи. Самым простым из доступных настроек является первичный ключ, который по определению уникален для каждой записи в таблице (хотя я не рекомендую использовать его, это просто для демонстрации концепции):
f(key, primaryKey) = key + primaryKey
Выше я просто объединяю ключ шифрования и значение первичного ключа для генерации окончательного ключа шифрования, однако вы можете ( и должны ) применять алгоритм хеширования или функцию получения ключа. Кроме того, вместо использования первичного ключа в качестве настройки, вы можете сгенерировать одноразовый номер (аналог соли) для каждой записи, которая будет использоваться в качестве настройки.
После применения настраиваемого шифрования к таблице пользователей это выглядит следующим образом:

Конечно, у нас все еще есть проблема с подсказкой пароля, но теперь каждая запись имеет уникальное значение, поэтому неясно, какие пользователи используют один и тот же пароль.
Я хочу подчеркнуть, что шифрование — не лучшее решение, и его следует избегать, если это возможно, для хранения паролей, так как может быть введено много недостатков… Вы можете и должны придерживаться проверенных решений (таких как bcrypt) для хранения паролей, но имейте в виду, что даже проверенные решения имеют свои недостатки.
Вывод
Идеального решения не существует, и риск того, что кто-то нарушит наши меры безопасности, растет с каждым днем. Тем не менее, исследования и исследования в области криптографии и безопасности данных продолжаются, и с относительно недавним определением функций губки наш инструментарий продолжает расти с каждым днем.