Разбиение на страницы — это метод разбиения больших наборов записей на более мелкие части, называемые страницами. Как разработчик, вы должны быть знакомы с реализацией разбиения на страницы, но внедрение разбиения на страницы для данных в реальном времени может стать сложным даже для опытных разработчиков. В этом уроке мы собираемся обсудить практические варианты использования и решения для нумерации данных в реальном времени и пагинации на основе курсора.
Выявление проблем в разбивке на страницы данных в реальном времени
Википедия определяет данные в реальном времени как информацию, полученную сразу после сбора. Там нет задержки в своевременности предоставленной информации. В таких приложениях трудно предоставить точные разбитые на страницы данные из-за частых обновлений. Давайте посмотрим на проблемы со стандартной нумерацией страниц при управлении данными в реальном времени.
-
Предполагается, что данные статичны и не меняются часто. При разбиении на страницы по умолчанию извлеченный набор записей разбивается на несколько страниц. Поскольку данные не часто меняются, пользователи чувствуют, что нумерация страниц работает точно, но результаты нумерации страниц становятся неточными при добавлении новых данных или удалении существующих данных.
-
Разбивка на страницы учитывает только количество записей, а не каждую отдельную запись. Записи разбиваются на страницы с использованием общего количества записей и разбиваются на страницы в обычном порядке. Он не учитывает, попадает ли каждая запись в нужную страницу на нумерации страниц. Это может привести к избыточному отображению записей.
Учитывая эти моменты, сложно использовать стандартные методы разбиения на страницы для обработки данных в реальном времени. Давайте попробуем определить проблемы, используя практический сценарий.
Предположим, что у нас изначально есть 20 записей, и мы используем 10 как предел, чтобы разбить записи на страницы. На следующем рисунке показано, как записи разбиваются на страницы.

Теперь предположим, что набор результатов обновляется пятью новыми записями, пока мы на первой странице. На следующем рисунке показан текущий сценарий.
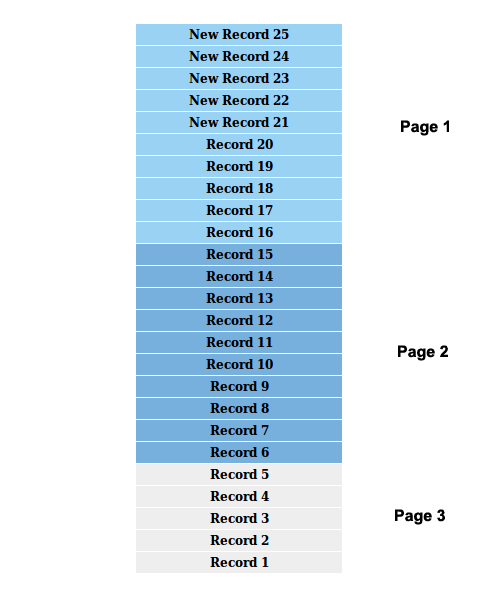
Теперь перейдем ко второй странице. Основываясь на нашем первом изображении, он должен получить записи от 1 до 10. Тем не менее, записи с номерами 15-6 будут восстановлены. Вы можете ясно видеть, что номера записей 15-11 отображаются как на первой странице, так и на второй странице.
Примеры практического использования пагинации данных в реальном времени
Как мы все знаем, изобретать велосипед — это не то, что должен делать разработчик. Мы должны взглянуть на существующие методы разбиения на страницы сайтов, которые решили эти проблемы, прежде чем думать о создании наших собственных. Многие сайты социальных сетей, такие как Twitter и Facebook, предоставляют данные в реальном времени в своих профилях пользователей. В этом разделе мы рассмотрим примеры практического использования нумерации данных в реальном времени на некоторых из самых популярных сайтов.
Разбиение страниц на основе API Twitter на основе курсора
Профили пользователей Twitter часто заполняются новыми твитами, поэтому механизм извлечения данных из временной шкалы Twitter должен стать хорошим началом для определения методов разбиения на страницы в потоках данных в реальном времени. Давайте посмотрим, как это работает, используя метод API Twitter.
Ниже приведен пример запроса к методу поисковых твитов API Twitter.
https://api.twitter.com/1.1/search/tweets.json?q=php&since_id=24012619984051000&max_id=250126199840518145&result_type=recent&count=10 В приведенном выше URL мы запрашиваем самые последние твиты, содержащие слово «php», и разбиваем результирующий набор на блоки по 10, используя параметр count . Это типичное поведение смещения нумерации страниц, когда мы отвечаем на количество записей. Но здесь мы видим два дополнительных параметра, которые называются since_id и max_id , что позволяет использовать пагинацию на основе курсора. Давайте посмотрим, как работает разбиение на страницы курсором, используя наш предыдущий пример.
У нас было 20 записей, разбитых на 2 страницы, и предположим, что мы на первой странице. 5 новых записей добавляются в начало списка. На следующем изображении показан текущий сценарий.
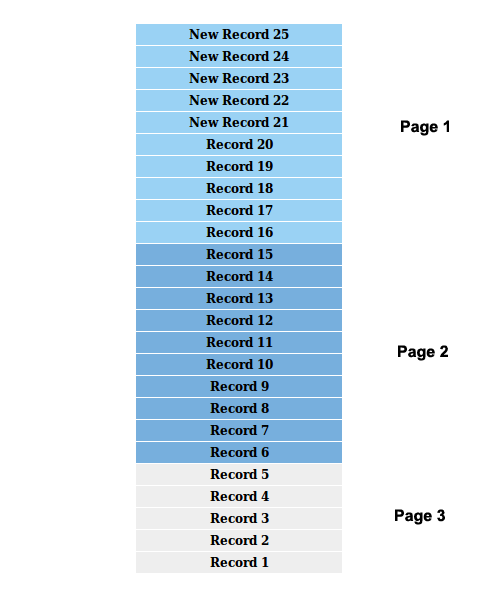
Теперь давайте взглянем на часть ответа, сгенерированного для первой страницы поискового запроса Twitter. Вы можете просмотреть полный формат ответа здесь .
"search_metadata": { "max_id": 250126199840518145, "since_id": 24012619984051000, "refresh_url": "?since_id=250126199840518145&q=php&result_type=recent&include_entities=1", "next_results": "?max_id=249279667666817023&q=php&count=10&include_entities=1&result_type=recent", "count": 10, "completed_in": 0.035, "since_id_str": "24012619984051000", "query": "php", "max_id_str": "250126199840518145" }
Как видите, раздел search_metadata предоставляет подробности о результатах. Он сгенерирует URL next_results , в случае если есть больше записей для разбивки на страницы. В основном мы используем параметр max_id для разбивки на страницы. С каждым ответом мы будем извлекать параметр max_id и использовать его для генерации следующего набора результатов. Мы используем параметр max_id для получения результатов старше указанного идентификатора.
В нашем примере мы должны получить параметр max_id как Record 11 при отображении записей 20-11. Затем мы передаем max_id для генерации следующего набора результатов. Таким образом, мы получим точные результаты, как показано на следующем рисунке.
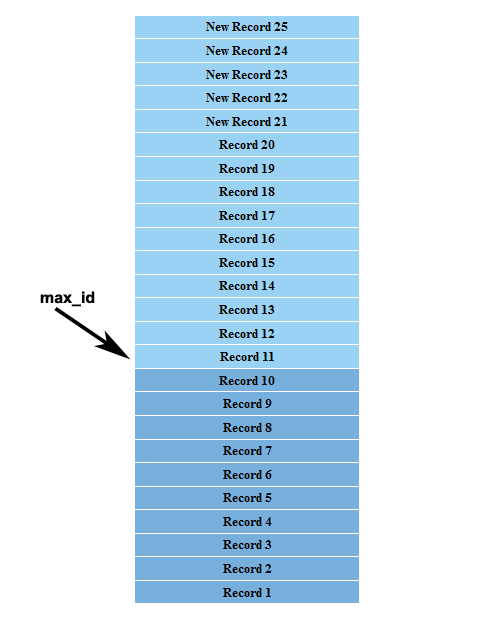
Как видите, у нас есть точные результаты для второй страницы, исключив 15 записей вверху, а не 10 в смещении на основе нумерации страниц. При разбиении на страницы курсором мы не можем рассматривать концепцию страниц, поскольку она быстро меняется, поэтому результаты будут рассматриваться как предыдущие или следующие. Как правило, max_id достаточно эффективен, чтобы генерировать точные результаты, но могут быть сценарии, когда since_id также важен при разбиении на страницы назад и вперед. Вы можете посмотреть более сложные примеры использования max_id и since_id в разделе для разработчиков в Twitter .
Facebook API курсора на основе нумерации страниц
Реализация API Facebook немного отличается от Twitter, хотя оба API используют одну и ту же теорию. Давайте посмотрим на ответ на пример запроса Facebook API.
{ "data": [ ... Endpoint data is here ], "paging": { "cursors": { "after": "MTAxNTExOTQ1MjAwNzI5NDE=", "before": "NDMyNzQyODI3OTQw" }, "previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw" "next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE=" } }
Как вы можете видеть, Facebook использует два строковых курсора, вызываемых before и after , для разбивки на страницы, вместо since_id и max_id . В Facebook курсор « before будет указывать на начало страницы, а курсор « after указывает на конец страницы.
Большинство API с данными в реальном времени используют этот механизм для точного разбивки своих результатов. Как разработчики, мы должны знать теорию разбиения на страницы с помощью курсора, чтобы использовать существующие API, а также создавать свои собственные при необходимости.
Основы построения пагинации для данных в реальном времени
Реализация разбиения на страницы данных в реальном времени является сложной задачей, выходящей за рамки данного руководства, поэтому мы рассмотрим основные потребности и процесс создания простого механизма разбиения на страницы для понимания разбиения на страницы курсором.
Давайте определим основные компоненты пагинации на основе курсора, используя рассмотренные ранее примеры.
-
Курсоры — нам нужен по крайней мере один столбец с уникальными последовательными значениями, чтобы реализовать пагинацию на основе курсора. Это может быть похоже на параметр
max_idв Twitter или параметрmax_idFacebook. -
Count — нам нужен параметр
countкак и в случае нумерации страниц, для фильтрации ограниченного числа результатов, до или после курсора. -
Следующий URL — это необходимо в случае, если мы предоставляем нумерацию страниц через API. Пользователи должны знать, доступна ли следующая страница и как получить следующий набор данных.
-
Предыдущий URL — это необходимо, если мы предоставляем нумерацию страниц через API. Пользователи должны знать, доступна ли предыдущая страница и как получить следующий набор данных.
Это основные потребности для нумерации на основе курсора. Разработчики часто работают с нумерацией страниц на основе смещения и редко получают возможность работать с нумерацией страниц на основе курсора, поэтому важно определить различия и преимущества каждого метода для использования их в соответствующих сценариях.
-
В разбивке по страницам мы можем отсортировать по любому столбцу и разбить на страницы результаты, в то время как разбивка на основе курсора зависит от сортировки уникального столбца курсора.
-
Смещение нумерации страниц содержит номера страниц в дополнение к следующим и предыдущим ссылкам. Но из-за высокой динамики данных мы не можем предоставить номера страниц для разбивки на страницы курсора.
-
Как правило, смещение нумерации страниц позволяет нам перемещаться в обоих направлениях, тогда как пагинация на основе курсора в основном используется для навигации вперед.
До сих пор мы рассматривали основные потребности и различия пагинации на основе курсора. Теперь мы можем перейти к примеру реализации, чтобы определить, как он работает.
Реализация базовой курсорной пагинации
<?php class Real_Time_Pagination{ public $conn; public function dbConnection(){ $this->conn = new PDO('mysql:host=localhost;dbname=database','username','password'); } public function handlePaginationData(){ $direction = 'next'; $order = 'desc'; $where = ''; $params = array(); if(isset($_GET['max_id'])){ $direction = 'next'; $where = " where tweetID < :max_id "; $order = 'desc'; $params = array(':max_id' => $_GET['max_id']); }else if(isset($_GET['since_id'])){ $direction = 'prev'; $where = " where tweetID > :since_id "; $order = 'asc'; $params = array(':since_id' => $_GET['since_id']); } $sth = $this->conn->prepare("select * from tweets $where order by tweetID $order "); $sth->execute($params); $results = $sth->fetchAll(); $count = count($results); $sth = $this->conn->prepare("select * from tweets $where order by tweetID $order limit 3"); $sth->execute($params); $results = $sth->fetchAll(); if($direction == 'prev'){ $results = array_reverse($results); } $html = ""; $max_id = ''; $since_id = ''; foreach($results as $row) { if($since_id == '' ) $since_id = $row['tweetID']; $view = $this->paginateDataView(); $html .= $this->assignTemplateVars(array('tweets'=>$row['tweet']) , $view); $max_id = $row['tweetID']; } $html = $this->getResultsList($html); $html .= $this->paginator($max_id,$since_id,$count,$direction); return $html; } public function getResultsList($res){ $html = "<table>$res</table>"; return $html; } public function assignTemplateVars($params,$view){ foreach($params as $key=>$val){ $view = str_replace('{'.$key.'}',$val,$view); } return $view; } }
-
Сначала мы создаем соединение с базой данных, используя PDO. Затем мы выполняем функцию
handlePaginationDataдля разбивки результатов на страницы. -
Затем мы проверяем,
max_idmin_idпараметрmax_idилиmin_idв URL.max_idпохож на параметр after в Facebook и используется для навигации вперед.min_idаналогичен параметру before в Facebook и используется для навигации в обратном направлении. Также мы устанавливаем направление навигации, предложениеmax_idс помощьюmax_idилиmin_idи порядок сортировки. -
Затем мы выполняем запрос, чтобы получить полный счетчик результатов, за которым следует тот же запрос с оператором limit для сужения результатов.
-
В случае, если мы движемся в предыдущем направлении, мы должны изменить сортировку на asc. В противном случае он получит самые последние записи вместо предыдущей страницы. Мы переворачиваем записи в массиве, чтобы показать их в порядке убывания.
-
Затем мы перебираем результаты. При зацикливании мы присваиваем ID первой записи
min_idа последней записиmax_id. Эти значения курсора используются для фильтрации точных данных путем устранения дублирования. -
Наконец, мы можем взглянуть на функцию
paginatorдля реализации ссылок на страницы.
public function paginator($max_id,$since_id,$count,$direction){ $pag['next_url'] = "?max_id=".$max_id; $pag['prev_url'] = "?since_id=".$since_id; $html = ''; $params = array('prev_url'=> $pag['prev_url'], 'next_url' => $pag['next_url']); if($direction == 'next' ){ if($count <= 3) $params['next_url'] ='#'; $view = $this->paginateLinksView(); $html .= $this->assignTemplateVars($params,$view); } if($direction == 'prev'){ if($count <= 3) $params['prev_url'] ='#'; $view = $this->paginateLinksView(); $html .= $this->assignTemplateVars($params,$view); } return $html; } public function paginateLinksView(){ $html ="<a href='{prev_url}'>Prev</a>"; $html .="<a href='{next_url}'>Next</a>"; return $html; } public function paginateDataView(){ $html = "<tr><td>{tweet}</td></tr>"; return $html; }
Следующий код содержит код инициализации для нумерации страниц, созданной в этом разделе.
<?php $rtp = new Real_Time_Pagination(); $rtp->dbConnection(); echo $rtp->handlePaginationData();
Теперь у нас есть простой образец разбиения на страницы данных, чтобы понять, как работает разбивка данных в реальном времени. Используйте этот код и разбивайте результаты на страницы. Во время разбивки на страницы добавьте несколько записей в конец таблицы, чтобы они отображались в реальном времени. Затем разбивайте страницы вперед и назад, чтобы проверить дубликаты данных на страницах. Сделайте то же самое со смещенной нумерацией страниц, чтобы понять разницу.
Вывод
В этом уроке мы изучили теорию разбиения данных в режиме реального времени на нумерацию курсоров. Дайте нам знать ваши мысли и опыт в комментариях ниже!