Как вы, возможно, знаете, я являюсь автором и сопровождающим парсера PHPM CommonMark Markdown . Этот проект имеет три основные цели:
- полностью поддерживать всю спецификацию CommonMark
- соответствовать поведению эталонной реализации JS
- быть хорошо написанным и суперрасширяемым, чтобы другие могли добавлять свои собственные функции.
Эта последняя цель, пожалуй, самая сложная, особенно с точки зрения производительности. Другие популярные парсеры Markdown создаются с использованием отдельных классов с массивными функциями регулярных выражений. Как видно из этого теста, он делает их молниеносно:
| Библиотека | Avg. Время разбора | Количество файлов / классов |
|---|---|---|
| Parsedown 1.6.0 | 2 мс | 1 |
| PHP Markdown 1.5.0 | 4 мс | 4 |
| PHP Markdown Extra 1.5.0 | 7 мс | 6 |
| CommonMark 0.12.0 | 46 мс | 117 |
К сожалению, из-за тесно связанной конструкции и общей архитектуры трудно (если не невозможно) расширить эти анализаторы с помощью пользовательской логики.
Для анализатора CommonMark в Лиге мы решили отдать предпочтение расширяемости, а не производительности. Это привело к отделенному объектно-ориентированному дизайну, который пользователи могут легко настроить . Это позволило другим создавать собственные интеграции , расширения и другие пользовательские проекты .
Производительность библиотеки по-прежнему приличная — конечный пользователь, вероятно, не может различить 42 мс и 2 мс (вы все равно должны кэшировать отрисованный Markdown). Тем не менее, мы все еще хотели максимально оптимизировать наш парсер, не ставя под угрозу наши основные цели. Этот пост объясняет, как мы использовали Blackfire для этого.
Профилирование с Blackfire
Blackfire — фантастический инструмент от людей в SensioLabs . Вы просто присоединяете его к любому веб-запросу или запросу CLI и получаете этот удивительный, легко усваиваемый след производительности запроса вашего приложения. В этой статье мы рассмотрим, как использовался Blackfire для выявления и оптимизации двух проблем с производительностью, обнаруженных в версии 0.6.1 библиотеки league / commonmark.
Давайте начнем с профилирования времени, которое требуется лиге / общему знаку для анализа содержимого документа спецификации CommonMark:
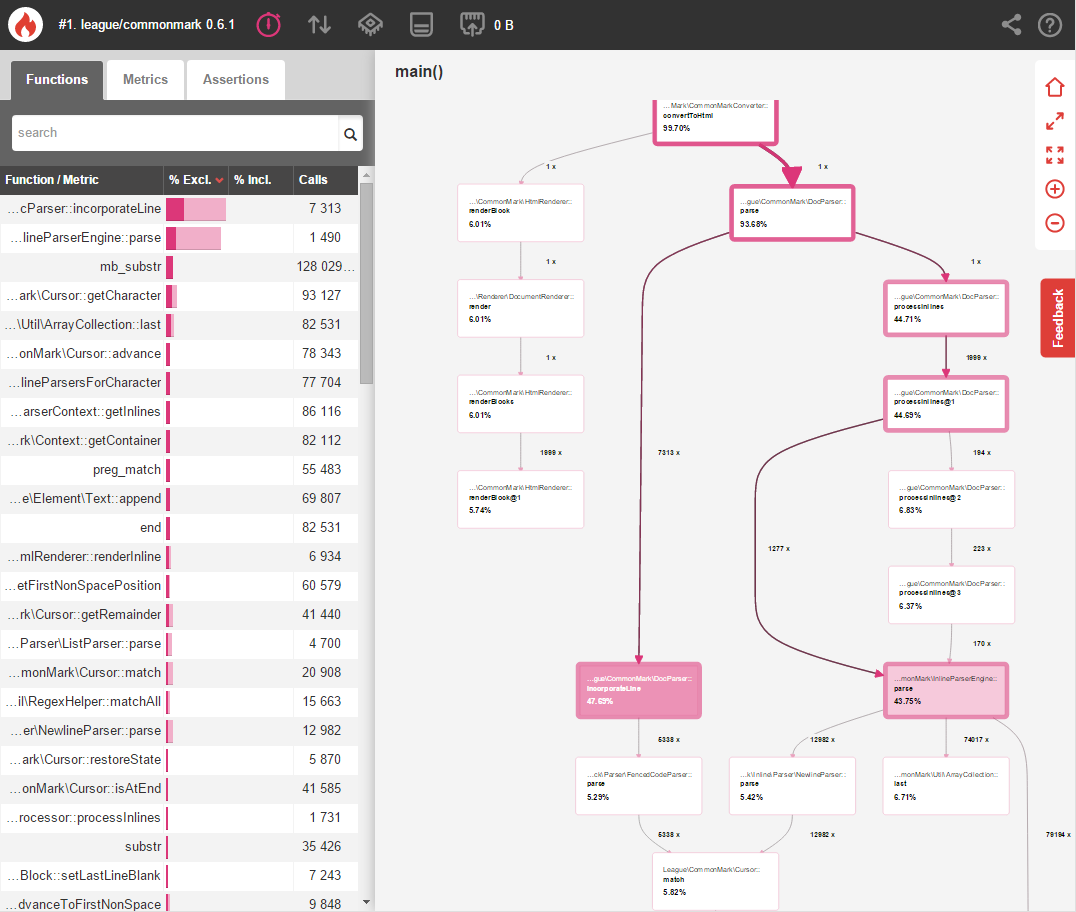
Позже мы сравним этот тест с нашими изменениями, чтобы измерить улучшения производительности.
Краткое примечание: Blackfire добавляет накладные расходы при профилировании, поэтому время выполнения всегда будет намного выше обычного. Сосредоточьтесь на относительных процентных изменениях вместо абсолютных «настенных часов».
Оптимизация 1
Глядя на наш начальный тест, вы можете легко увидеть, что встроенный анализ с InlineParserEngine::parse() составляет колоссальные 43,75% времени выполнения. Нажатие на этот метод показывает больше информации о том, почему это происходит:
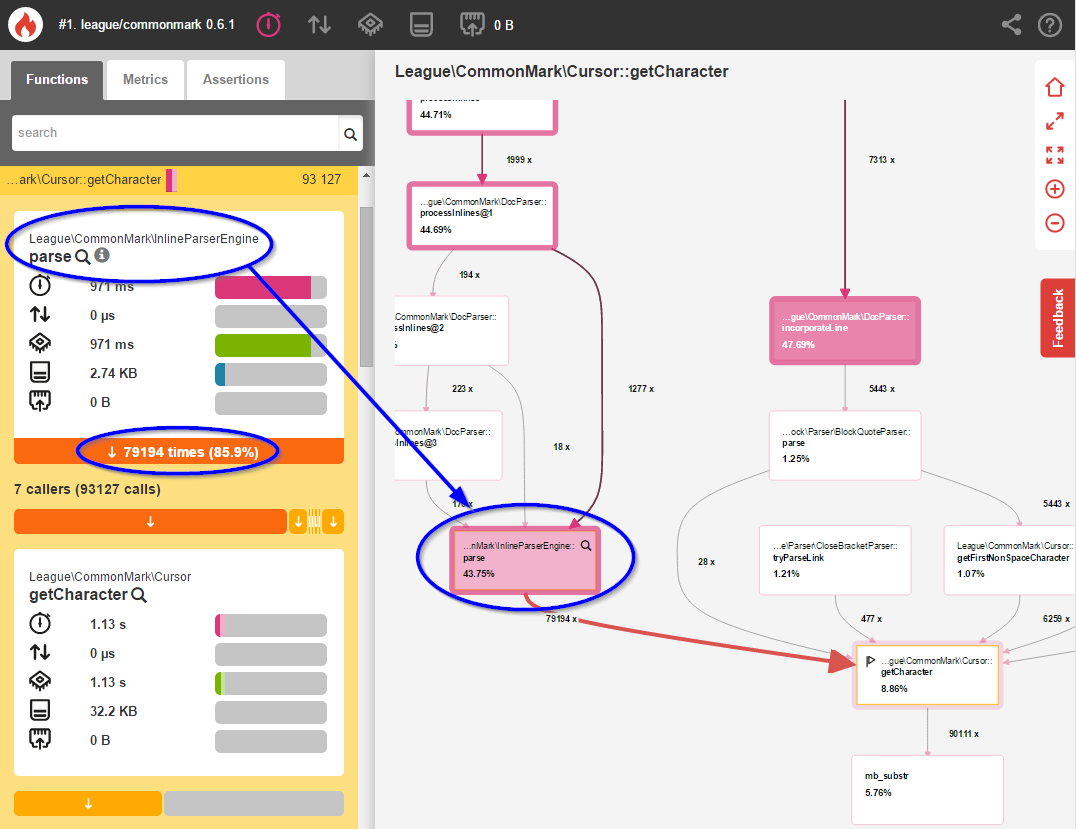
Здесь мы видим, что InlineParserEngine::parse() вызывает Cursor::getCharacter() 79 194 раза — по одному разу для каждого символа в тексте Markdown. Вот частичная (слегка измененная) выдержка из этого метода из 0.6.1:
public function parse(ContextInterface $context, Cursor $cursor) { // Iterate through every single character in the current line while (($character = $cursor->getCharacter()) !== null) { // Check to see whether this character is a special Markdown character // If so, let it try to parse this part of the string foreach ($matchingParsers as $parser) { if ($res = $parser->parse($context, $inlineParserContext)) { continue 2; } } // If no parser could handle this character, then it must be a plain text character // Add this character to the current line of text $lastInline->append($character); } }
Blackfire говорит нам, что parse() тратит более 17% своего времени на проверку каждого. не замужем. персонаж. один. в. а. время Но большинство из этих 79 194 символов — простой текст, который не требует специальной обработки! Давайте оптимизировать это.
Вместо добавления одного символа в конце нашего цикла, давайте используем регулярное выражение для захвата как можно большего количества специальных символов:
public function parse(ContextInterface $context, Cursor $cursor) { // Iterate through every single character in the current line while (($character = $cursor->getCharacter()) !== null) { // Check to see whether this character is a special Markdown character // If so, let it try to parse this part of the string foreach ($matchingParsers as $parser) { if ($res = $parser->parse($context, $inlineParserContext)) { continue 2; } } // If no parser could handle this character, then it must be a plain text character // NEW: Attempt to match multiple non-special characters at once. // We use a dynamically-created regex which matches text from // the current position until it hits a special character. $text = $cursor->match($this->environment->getInlineParserCharacterRegex()); // Add the matching text to the current line of text $lastInline->append($character); } }
Как только это изменение было сделано, я перепрофилировал библиотеку, используя Blackfire:
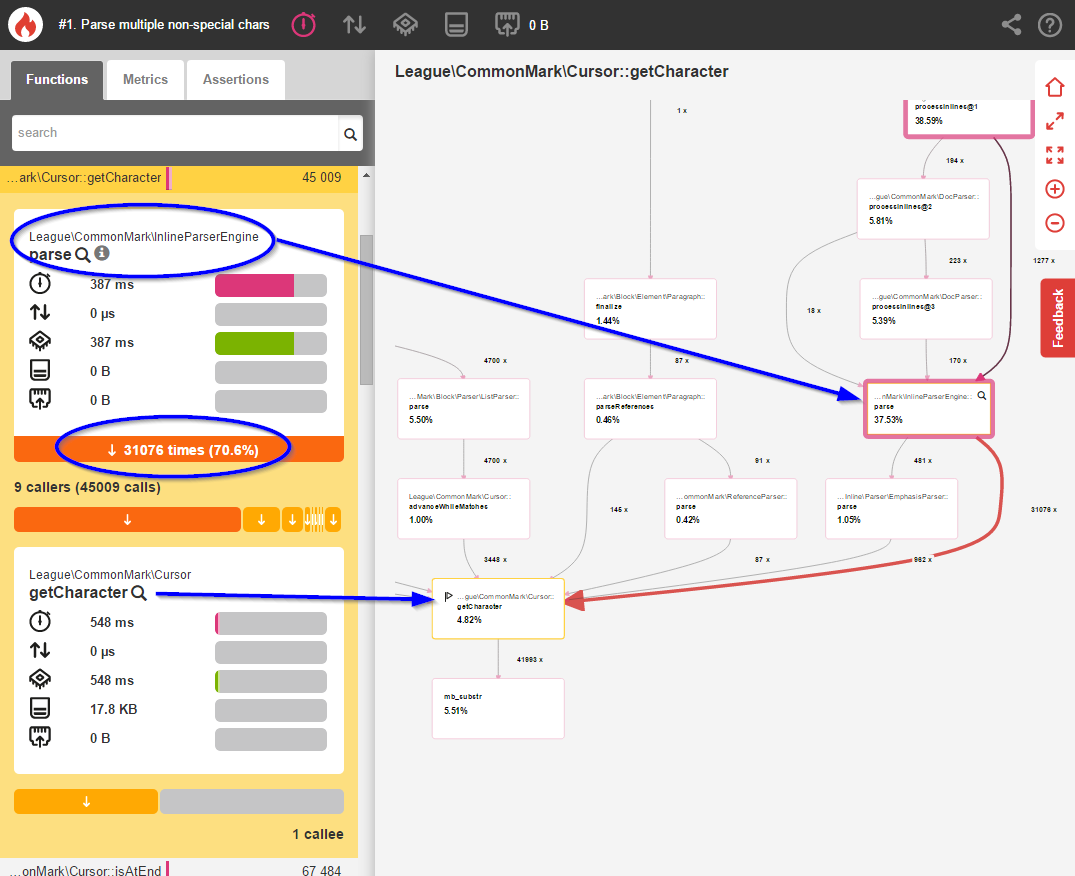
Хорошо, все выглядит немного лучше. Но давайте на самом деле сравним два теста, используя инструмент сравнения Blackfire, чтобы получить более четкую картину того, что изменилось:
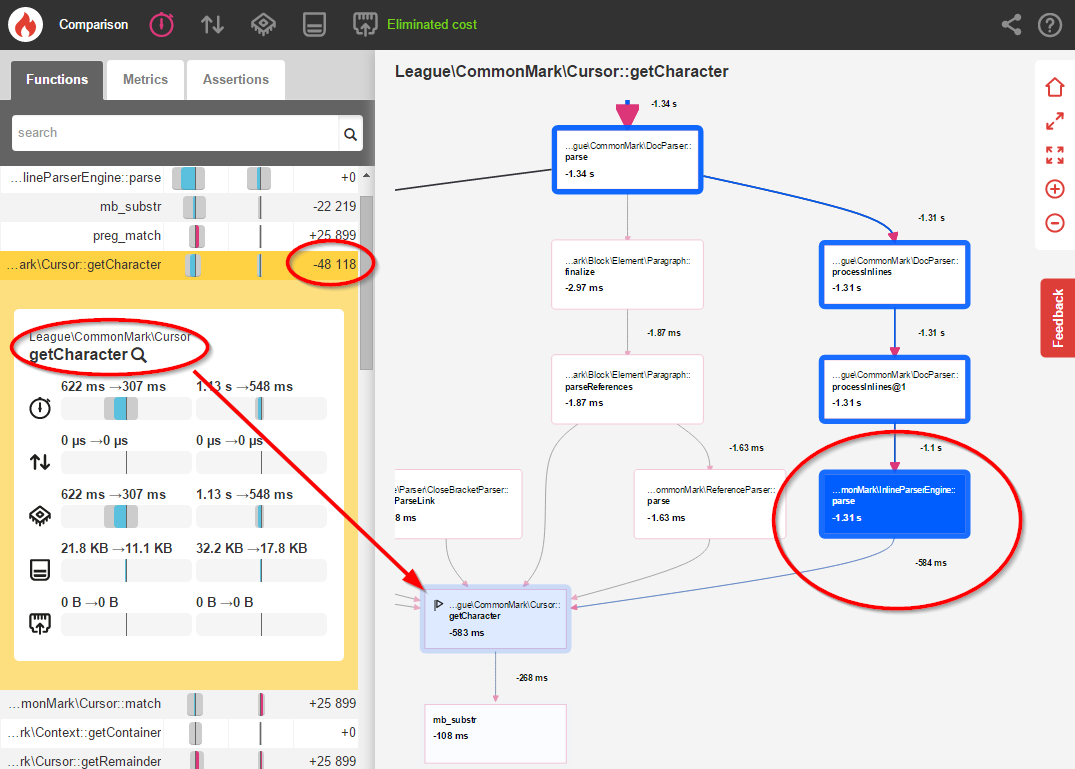
Это единственное изменение привело к сокращению на 481818 вызовов этого метода Cursor::getCharacter() и повышению общей производительности на 11% ! Это, безусловно, полезно, но мы можем оптимизировать встроенный анализ еще дальше.
Оптимизация 2
Согласно спецификации CommonMark :
Разрыв строки …, которому предшествуют два или более пробелов …, анализируется как жесткий разрыв строки (отображается в HTML как
тег)
Из-за этого языка у меня изначально была остановка NewlineParser и исследование каждого пробела и \n символа, с которым он столкнулся. Вот пример того, как выглядел этот оригинальный код:
class NewlineParser extends AbstractInlineParser { public function getCharacters() { return array("\n", " "); } public function parse(ContextInterface $context, InlineParserContext $inlineContext) { if ($m = $inlineContext->getCursor()->match('/^ *\n/')) { if (strlen($m) > 2) { $inlineContext->getInlines()->add(new Newline(Newline::HARDBREAK)); return true; } elseif (strlen($m) > 0) { $inlineContext->getInlines()->add(new Newline(Newline::SOFTBREAK)); return true; } } return false; } }
Большинство из этих пространств не были особенными, и поэтому было бесполезно останавливаться на каждом и проверять их с помощью регулярных выражений. Вы можете легко увидеть влияние производительности на оригинальный профиль Blackfire:

Я был шокирован, когда увидел, что 43,75% всего процесса разбора выясняют, нужно ли преобразовывать 12 982 пробела и символы новой строки в элементы. Это было совершенно неприемлемо, поэтому я решил оптимизировать это.
Помните, что спецификация диктует, что последовательность должна заканчиваться символом новой строки ( \n ). Итак, вместо того, чтобы останавливаться на каждом символе пробела, давайте просто остановимся на новых строках и посмотрим, были ли предыдущие символы пробелами:
class NewlineParser extends AbstractInlineParser { public function getCharacters() { return array("\n"); } public function parse(ContextInterface $context, InlineParserContext $inlineContext) { $inlineContext->getCursor()->advance(); // Check previous text for trailing spaces $spaces = 0; $lastInline = $inlineContext->getInlines()->last(); if ($lastInline && $lastInline instanceof Text) { // Count the number of spaces by using some `trim` logic $trimmed = rtrim($lastInline->getContent(), ' '); $spaces = strlen($lastInline->getContent()) - strlen($trimmed); } if ($spaces >= 2 ) { $inlineContext->getInlines()->add(new Newline(Newline::HARDBREAK)); } else { $inlineContext->getInlines()->add(new Newline(Newline::SOFTBREAK)); } return true; } }
После этого изменения я повторно профилировал приложение и увидел следующие результаты:
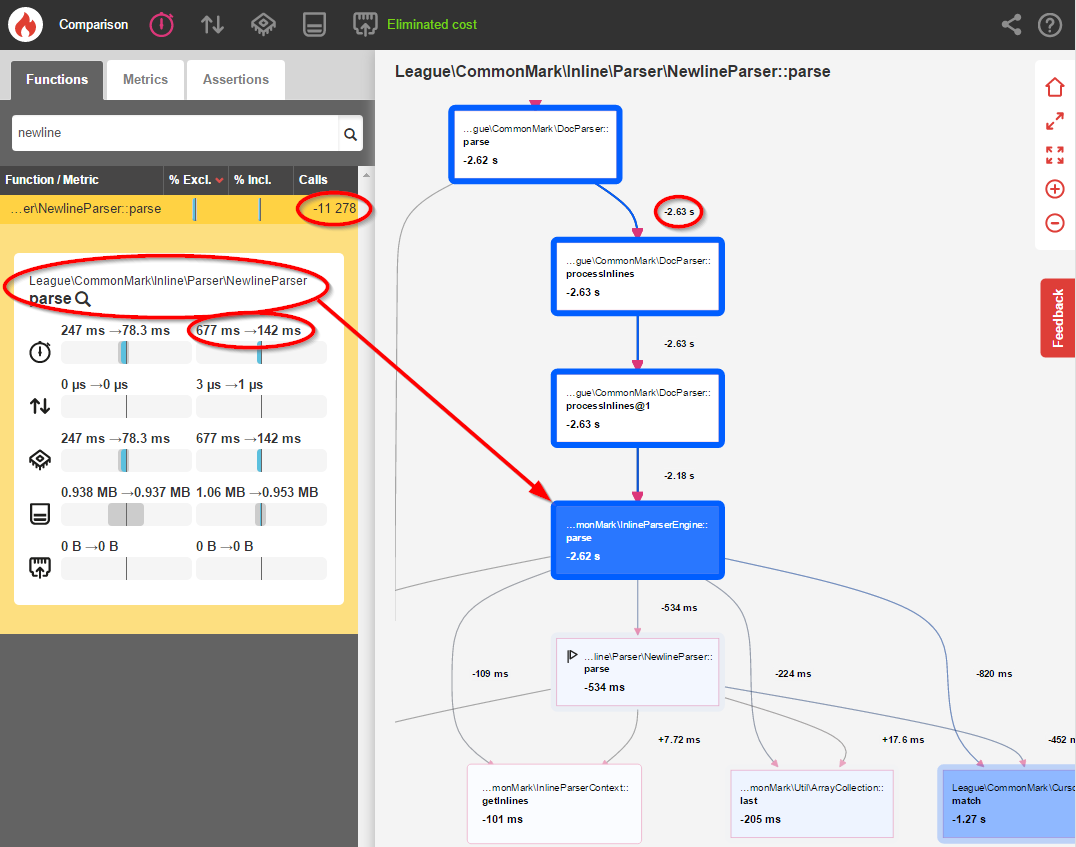
-
NewlineParser::parse()теперь вызывается только 1704 раза вместо 12,982 раза (снижение на 87%) - Общее время синтаксического анализа сократилось на 61%
- Общая скорость разбора улучшена на 23%
Резюме
После того, как обе оптимизации были реализованы, я повторно запустил инструмент тестирования лиги / общепринятого теста, чтобы определить реальные последствия для производительности:
- Перед:
- 59ms
- После:
- 28ms
Это колоссальное увеличение производительности на 52,5% благодаря двум простым изменениям !
Возможность определения затрат на производительность (как по времени выполнения, так и по количеству вызовов функций) имела решающее значение для выявления этих скачков производительности. Я очень сомневаюсь, что эти проблемы были бы замечены без доступа к данным о производительности.
Профилирование абсолютно необходимо для обеспечения того, чтобы ваш код работал быстро и эффективно. Если у вас еще нет инструмента профилирования, я настоятельно рекомендую вам проверить его. Моим личным фаворитом является Blackfire («freemium»), но есть и другие инструменты профилирования . Все они работают немного по-разному, так что посмотрите вокруг и найдите тот, который лучше всего подходит для вас и вашей команды.
Неотредактированная версия этого поста была первоначально опубликована в блоге Колина . Это было переиздано здесь с разрешения автора.