Эта статья является частью серии по созданию примера приложения — блога галереи с несколькими изображениями — для оценки производительности и оптимизации. (Посмотреть репо здесь.)
За последние несколько месяцев мы представили Blackfire и способы его использования для обнаружения узких мест в производительности приложений. В этом посте мы применим его к нашему недавно начатому проекту, чтобы попытаться найти низкие и низко висящие фрукты, которые мы можем выбрать, чтобы улучшить производительность нашего приложения.
Если вы используете Homestead Improved (и вам следует), Blackfire уже установлен.
Хотя полезно ознакомиться с Blackfire, прежде чем углубляться в это, применение шагов в этом посте не потребует каких-либо предварительных знаний; мы начнем с нуля.
Настроить
Ниже приведены полезные термины при оценке графиков, созданных Blackfire.
-
Эталонный профиль : нам обычно нужно запускать наш первый профиль как эталонный профиль Этот профиль будет основой производительности нашего приложения. Мы можем сравнить любой профиль со ссылкой, чтобы измерить достижения производительности.
-
Эксклюзивное время : количество времени, затрачиваемое на выполнение функции / метода без учета времени, потраченного на внешние вызовы.
-
Включенное время : общее время, затраченное на выполнение функции, включая все внешние вызовы.
-
Горячие пути : Горячие пути — это части нашего приложения, которые были наиболее активными во время профиля. Это могут быть части, которые занимают больше памяти или занимают больше процессорного времени.
Первым шагом является регистрация учетной записи на Blackfire . Страница учетной записи будет содержать токены и идентификаторы, которые необходимо поместить в Homestead.yaml после клонирования проекта. Есть заполнитель для всех этих значений внизу:
# blackfire: # - id: foo # token: bar # client-id: foo # client-token: bar
После раскомментирования строк и замены значений нам нужно установить компаньон Chrome .
Компаньон Chrome полезен только в том случае, если вам нужно запустить профилирование вручную, что будет в большинстве случаев. Также доступны другие интеграции, полный список которых можно найти здесь .
Оптимизация с помощью Blackfire
Мы протестируем домашнюю страницу: целевая страница, пожалуй, самая важная часть любого веб-сайта, и если загрузка займет слишком много времени, мы гарантированно потеряем наших посетителей. Они исчезнут до того, как Google Analytics сможет зарегистрировать отскок! Мы могли бы тестировать страницы, на которых пользователи добавляют изображения, но производительность только для чтения гораздо важнее, чем производительность записи, поэтому мы сосредоточимся на первом.
Эта версия приложения загружает все галереи и сортирует их по возрасту.
Тестирование просто. Мы открываем страницу, которую мы хотим сравнить, нажимаем кнопку расширения в браузере и выбираем «Профиль!».
Вот результирующий график:
Фактически, мы можем видеть здесь, что время выполнения, включающее эксклюзив, составляет 100% при выполнении PDO. В частности, это означает, что вся темно-розовая часть расходуется внутри этой функции и что эта функция, в частности, не ожидает какой-либо другой функции. Это функция, которую ждут. У других вызовов методов могут быть светло-розовые столбцы, намного большие, чем у PDO, но эти светло-розовые части представляют собой сумму всех меньших светло-розовых частей зависимых функций, что означает, что при рассмотрении по отдельности эти функции не являются проблемой. Темные должны быть обработаны в первую очередь; они являются приоритетом.
Кроме того, переключение в режим ОЗУ показывает, что, хотя весь вызов использовал почти колоссальные 40 МБ ОЗУ, подавляющее большинство приходится на рендеринг Twig, что имеет смысл: в конце концов, он показывает много данных.
На диаграмме горячие пути имеют толстые границы и обычно указывают на узкие места. Интенсивные узлы могут быть частью горячего пути, но также и полностью вне его. Интенсивные узлы — это узлы, по которым по какой-то причине тратится много времени, и они также могут указывать на проблемы.
Рассматривая наиболее проблемные методы и щелкая по соответствующим узлам, мы можем определить, что PDOExecute является наиболее проблемным узким местом, в то время как unserialize использует больше оперативной памяти по сравнению с другими методами. Если мы применим какую-то детективную работу и будем следовать потоку методов, вызывающих друг друга, мы заметим, что обе эти проблемы вызваны тем фактом, что мы загружаем весь набор галерей на главной странице. PDOExecute всегда тратит память и время на их поиск и сортировку, а Doctrine тратит целые и бесконечные циклы ЦП, чтобы превратить их в визуализируемые объекты с unserialize для циклического unserialize их в шаблоне twig . Решение кажется простым — добавьте нумерацию страниц на главную страницу!
Добавляя константу PER_PAGE в HomeController и устанавливая для нее что-то вроде 12 , а затем используя эту константу разбиения на страницы в процедуре извлечения, мы блокируем первый вызов новейших 12 галерей:
$galleries = $this->em->getRepository(Gallery::class)->findBy([], ['createdAt' => 'DESC'], self::PER_PAGE);
Мы будем запускать ленивую загрузку, когда пользователь достигает конца страницы при прокрутке, поэтому нам нужно добавить JS в домашний вид:
{% block javascripts %} {{ parent() }} <script> $(function () { var nextPage = 2; var $galleriesContainer = $('.home__galleries-container'); var $lazyLoadCta = $('.home__lazy-load-cta'); function onScroll() { var y = $(window).scrollTop() + $(window).outerHeight(); if (y >= $('body').innerHeight() - 100) { $(window).off('scroll.lazy-load'); $lazyLoadCta.click(); } } $lazyLoadCta.on('click', function () { var url = "{{ url('home.lazy-load') }}"; $.ajax({ url: url, data: {page: nextPage}, success: function (data) { if (data.success === true) { $galleriesContainer.append(data.data); nextPage++; $(window).on('scroll.lazy-load', onScroll); } } }); }); $(window).on('scroll.lazy-load', onScroll); }); </script> {% endblock %}
Поскольку для маршрутов используются аннотации, легко добавить новый метод в HomeController чтобы лениво загружать наши галереи при запуске:
/** * @Route("/galleries-lazy-load", name="home.lazy-load") */ public function homeGalleriesLazyLoadAction(Request $request) { $page = $request->get('page', null); if (empty($page)) { return new JsonResponse([ 'success' => false, 'msg' => 'Page param is required', ]); } $offset = ($page - 1) * self::PER_PAGE; $galleries = $this->em->getRepository(Gallery::class)->findBy([], ['createdAt' => 'DESC'], 12, $offset); $view = $this->twig->render('partials/home-galleries-lazy-load.html.twig', [ 'galleries' => $galleries, ]); return new JsonResponse([ 'success' => true, 'data' => $view, ]); }
сравнение
Давайте теперь сравним наше обновленное приложение с предыдущей версией, повторно запустив профилировщик.
Конечно, наш сайт использует в 10 раз меньше памяти и загружается гораздо быстрее — возможно, не во время процессора, как указано на графике, а в виде впечатлений. Перезагрузка теперь практически мгновенная.
Теперь график показывает, что DebugClass является наиболее ресурсоемким вызовом метода.
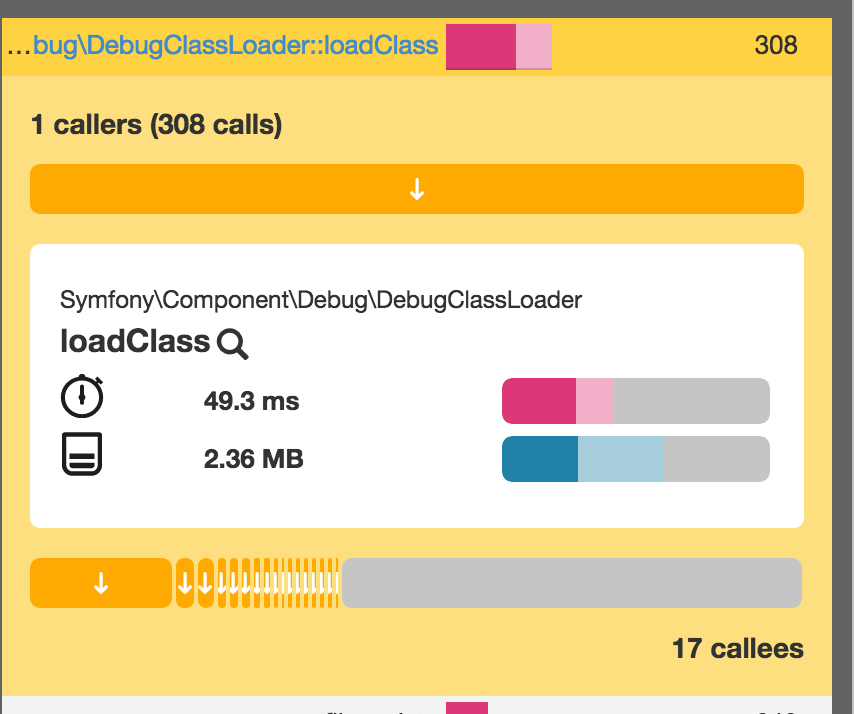
Это происходит потому, что мы находимся в режиме разработки, и этот загрузчик классов, как правило, намного медленнее, чем производственный, потому что он не кэширует классы. Это необходимо для того, чтобы изменения, сделанные в коде, можно было немедленно проверить без необходимости очищать кэш APC или любой другой используемый кэш.
Если мы перейдем в режим prod только для целей этого теста, мы увидим заметную разницу:
Вывод
Скорость нашего приложения сейчас ошеломляет — крошечные 58 мс для загрузки страницы, и загрузчик классов не виден. Имейте в виду, все это происходит в виртуальной машине с тысячами записей фиктивных данных. На данный момент мы можем быть очень оптимистичными по поводу состояния производства нашего приложения: на домашней странице практически не осталось оптимизаций; все остальное можно классифицировать как микрооптимизацию.
Регулярное повторное выполнение этих тестов производительности важно для цикла разработки любого приложения, и интеграция их в конвейер тестирования приложения, например поток CD / CI, может быть чрезвычайно полезной и продуктивной. Мы рассмотрим этот вариант чуть позже, но важно отметить, что премиальная подписка Blackfire действительно предлагает именно эту встроенную функцию. Проверьте это !
В настоящее время важно, чтобы у нас был установлен и доступен Blackfire, и чтобы он мог помочь нам найти узкие места и выявить новые, поскольку мы добавляем больше функций в микшер. Добро пожаловать в мир непрерывного тестирования производительности!