Оптическое распознавание символов (OCR) — это процесс преобразования печатного текста в цифровое представление. Он имеет множество практических применений — от оцифровки печатных книг, создания электронных записей квитанций до распознавания номерных знаков и даже обхода CAPTCHA на основе изображений.

Tesseract — это программа с открытым исходным кодом для выполнения распознавания текста. Вы можете запустить его на системах * Nix, Mac OSX и Windows, но используя библиотеку, мы можем использовать ее в приложениях PHP. Этот учебник разработан, чтобы показать вам, как.
Установка
подготовка
Для простоты и согласованности мы будем использовать виртуальную машину для запуска приложения, которое мы предоставляем с помощью Vagrant. Это позаботится об установке PHP и Nginx, хотя мы установим Tesseract отдельно, чтобы продемонстрировать процесс.
Если вы хотите установить Tesseract на свою собственную, существующую систему на основе Debian, вы можете пропустить эту следующую часть или, в качестве альтернативы, посетить README для получения инструкций по установке на других * nix системах, Mac OSX (подсказка — используйте MacPorts !) Или Windows.
Vagrant Setup
Чтобы настроить Vagrant, чтобы вы могли следовать инструкциям, выполните следующие шаги. Кроме того, вы можете просто получить код из Github .
Введите следующую команду, чтобы загрузить конфигурацию Homestead Improved Vagrant в каталог с именем ocr :
git clone https :// github . com / Swader / homestead_improved ocr
Давайте изменим конфигурацию Nginx в Homestead.yml из:
sites :
- map : homestead . app to : /home/ vagrant / Code / Project / public
… до …
sites :
- map : homestead . app to : /home/ vagrant / Code / public
Вам также необходимо добавить следующее в ваш файл hosts:
192.168 . 10.10 homestead . app
Установка Tesseract Binary
Следующим шагом является установка двоичного файла Тессеракта.
Поскольку Homestead Improved использует дистрибутив Linux на основе Debian, мы можем использовать apt-get для его установки после входа в виртуальную vagrant ssh с помощью vagrant ssh . Это так же просто, как выполнить следующую команду:
sudo apt - get install tesseract - ocr
Как я упоминал выше, в README есть инструкции для других операционных систем.
Тестирование и настройка установки
Мы собираемся использовать оболочку PHP, но прежде чем мы начнем строить, мы можем проверить, что Tesseract работает с использованием командной строки.
Сначала щелкните правой кнопкой мыши и сохраните это изображение .
{kind=link}
( Изображение предоставлено Clipart Panda )
В виртуальной vagrant ssh ( vagrant ssh ) выполните следующую команду, чтобы «прочитать» образ и выполнить процесс распознавания:
tesseract sign . png out
Это создает файл в текущей папке с именем out.txt который все хорошо, должен содержать слово «ВНИМАНИЕ».
Теперь попробуйте с файлом sign2.jpg :
{kind=link}
( Изображение является адаптированной версией этого ).
{kind=link}
tesseract sign2 . jpg out
На этот раз вы должны обнаружить, что он произвел слово «Einbahnstral’ie». Это близко, но это не правильно — даже несмотря на то, что текст на изображении довольно четкий и ясный, он не смог распознать символ eszett (ß).
Чтобы Tesseract правильно прочитал строку, нам нужно установить несколько новых языковых файлов — в нашем случае это немецкий.
Здесь представлен полный список доступных языковых файлов, но давайте просто скачаем соответствующий файл напрямую:
wget https :// tesseract - ocr . googlecode . com / files / tesseract - ocr - 3.02 . deu . tar . gz
… извлечь это …
tar zxvf tesseract - ocr - 3.02 . deu . tar . gz
Затем скопируйте файлы в следующий каталог:
/usr/ share / tesseract - ocr / tessdata
например
cp deu - frak . traineddata / usr / share / tesseract - ocr / tessdata cp deu . traineddata / usr / share / tesseract - ocr / tessdata
Теперь снова запустите предыдущую команду, но, используя ключ -l выполните следующие действия:
tesseract sign2 . jpg out - l deu
«Deu» — это код ISO 639-3 для немецкого языка.
На этот раз текст должен быть правильно обозначен как «Einbahnstraße».
Не стесняйтесь добавлять дополнительные языки, повторяя этот процесс.
Настройка приложения
Мы собираемся использовать эту библиотеку-оболочку для использования Tesseract из PHP.
Мы собираемся создать действительно простое веб-приложение, которое позволит людям загружать изображения и видеть результаты процесса распознавания. Для его реализации мы будем использовать микрорамку Silex — хотя не беспокойтесь, если вы с ней не знакомы, так как само приложение будет очень простым.
Помните, что весь код для этого урока доступен на Github .
Первый шаг — установить зависимости с помощью Composer:
composer require silex / silex twig / twig thiagoalessio / tesseract_ocr : dev - master
Теперь создайте следующие три каталога:
- public
- uploads - views
Нам понадобится форма для загрузки ( views\index.twig ):
<html>
<head>
<title> OCR </title>
</head>
<body>
<form action = "" method = "post" enctype = "multipart/form-data" >
<input type = "file" name = "upload" >
<input type = "submit" >
</form>
</body>
</html>
И страница с результатами ( views\results.twig ):
<html>
<head>
<title> OCR </title>
</head>
<body>
<h2> Results </h2>
<textarea cols = "50" rows = "10" > {{ text }} </textarea>
<hr>
<a href = "/" > ← Go back </a>
</body>
</html>
Теперь создайте скелет приложения Silex ( public\index.php ):
<? php require __DIR__ . '/../vendor/autoload.php' ;
use Symfony \Component\HttpFoundation\Request ; $app = new Silex \Application (); $app -> register ( new Silex \Provider\TwigServiceProvider (), [
'twig.path' => __DIR__ . '/../views' ,
]); $app [ 'debug' ] = true ; $app -> get ( '/' , function () use ( $app ) {
return $app [ 'twig' ]-> render ( 'index.twig' );
}); $app -> post ( '/' , function ( Request $request ) use ( $app ) {
// TODO
}); $app -> run ();
Если вы посещаете приложение в своем браузере, вы должны увидеть форму загрузки файла. Если вы следите за новостями и используете Homestead Improved с Vagrant, вы найдете его по следующему URL:
http : //homestead.app/
Следующим шагом является загрузка файла. Silex делает это действительно легко; объект $request содержит компонент files , который мы можем использовать для доступа к любым загруженным файлам. Вот некоторый код для обработки загруженного файла (обратите внимание, что это идет по маршруту POST):
// Grab the uploaded file $file = $request -> files -> get ( 'upload' );
// Extract some information about the uploaded file $info = new SplFileInfo ( $file -> getClientOriginalName ());
// Create a quasi-random filename $filename = sprintf ( '%d.%s' , time (), $info -> getExtension ());
// Copy the file $file -> move ( __DIR__ . '/../uploads' , $filename );
Как вы можете видеть, мы генерируем квазислучайное имя файла, чтобы минимизировать конфликты имен файлов — но, в конечном счете, в контексте этого приложения не имеет значения, что мы называем загруженным файлом.
Получив копию файла в локальной файловой системе, мы можем создать экземпляр библиотеки Tessearct, передав ему путь к изображению, которое мы хотим проанализировать:
// Instantiate the Tessearct library $tesseract = new TesseractOCR ( __DIR__ . '/../uploads/' . $filename );
Выполнить OCR на изображении действительно просто. Мы просто вызываем метод recognize() :
// Perform OCR on the uploaded image $text = $tesseract -> recognize ();
Наконец, мы можем отобразить страницу результатов, передав ей результаты OCR:
return $app [ 'twig' ]-> render (
'results.twig' ,
[
'text' => $text ,
]
);
Попробуйте это на некоторых изображениях, и посмотрите, как это работает. Если у вас возникли проблемы с распознаванием изображений, вам может быть полезно обратиться к руководству по улучшению качества .
Практический пример
Давайте посмотрим на более практическое применение технологии OCR. В этом примере мы попытаемся найти и отформатировать номер телефона, встроенный в изображение.
Посмотрите на следующее изображение и попробуйте загрузить его в свое приложение:
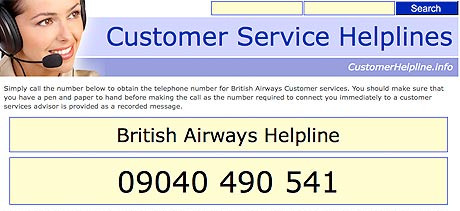
Результаты должны выглядеть так:
: ii ' i Customer Service Helplines
British Airways Helpline
09040 490 541
Он не подхватил основной текст, который мы могли ожидать из-за низкого качества изображения. Он идентифицировал номер телефона, но там также есть некоторый дополнительный «шум».
Чтобы попытаться извлечь соответствующую информацию, есть несколько вещей, которые мы можем сделать.
Вы можете указать Tesseract ограничить его вывод определенными диапазонами символов. Таким образом, мы можем сказать, чтобы он возвращал только цифры, используя следующую строку:
$tesseract -> setWhitelist ( range ( 0 , 9 ));
Однако есть проблема с этим. Вместо того, чтобы игнорировать нечисловые символы, он обычно интерпретирует буквы как цифры. Например, имя «Боб» можно интерпретировать как число «808».
Вместо этого давайте используем двухэтапный процесс:
- Попытка извлечь строки чисел, которые могут быть телефонными номерами
- Используйте библиотеку для проверки каждого кандидата по очереди, останавливаясь, когда мы находим действительный номер телефона
Для первой части мы можем использовать элементарное регулярное выражение. Чтобы попытаться определить, является ли строка чисел действительным номером телефона, мы можем использовать libphonenumber от Google .
Примечание : я написал о libphonenumber здесь на Sitepoint как часть статьи, озаглавленной Работа с телефонными номерами в JavaScript .
Давайте добавим порт PHP библиотеки libphonenumber в наш файл composer.json :
"giggsey/libphonenumber-for-php" : "~7.0"
Не забудьте обновить:
composer update
Теперь мы можем написать функцию, которая принимает строку и пытается извлечь из нее действительный номер телефона:
/** * Parse a string, trying to find a valid telephone number. As soon as it finds a * valid number, it'll return it in E1624 format. If it can't find any, it'll * simply return NULL. * * @param string $text The string to parse * @param string $country_code The two digit country code to use as a "hint" * @return string | NULL */
function findPhoneNumber ( $text , $country_code = 'GB' ) {
// Get an instance of Google's libphonenumber $phoneUtil = \libphonenumber\PhoneNumberUtil :: getInstance ();
// Use a simple regular expression to try and find candidate phone numbers preg_match_all ( '/(\+\d+)?\s*(\(\d+\))?([\s-]?\d+)+/' , $text , $matches );
// Iterate through the matches
foreach ( $matches as $match ) {
foreach ( $match as $value ) {
try {
// Attempt to parse the number $number = $phoneUtil -> parse ( trim ( $value ), $country_code );
// Just because we parsed it successfully, doesn't make it vald - so check it
if ( $phoneUtil -> isValidNumber ( $number )) {
// We've found a telephone number. Format using E.164, and exit
return $phoneUtil -> format ( $number , \libphonenumber\PhoneNumberFormat :: E164 );
}
} catch ( \libphonenumber\NumberParseException $e ) {
// Ignore silently; getting here simply means we found something that isn't a phone number
}
}
}
return null ;
}
Надеемся, что комментарии объяснят, что делает функция. Обратите внимание, что если библиотека не сможет проанализировать строку чисел как номер телефона, она выдаст исключение. Это не проблема как таковая; мы просто игнорируем это и переходим к следующему кандидату.
Если мы найдем номер телефона, мы вернем его в формате E.164 . Это обеспечивает международно-признанную версию номера, которую мы могли бы затем использовать для совершения звонка или отправки SMS.
Теперь мы можем использовать его следующим образом:
$text = $tesseract -> recognize (); $number = findPhoneNumber ( $text , 'GB' );
Мы должны предоставить libphonenumber «подсказку» о том, в какой стране находится телефонный номер. Вы можете изменить это для своей страны.
Мы могли бы обернуть все это в новый маршрут:
$app -> post ( '/identify-telephone-number' , function ( Request $request ) use ( $app ) {
// Grab the uploaded file $file = $request -> files -> get ( 'upload' );
// Extract some information about the uploaded file $info = new SplFileInfo ( $file -> getClientOriginalName ());
// Create a quasi-random filename $filename = sprintf ( '%d.%s' , time (), $info -> getExtension ());
// Copy the file $file -> move ( __DIR__ . '/../uploads' , $filename );
// Instantiate the Tessearct library $tesseract = new TesseractOCR ( __DIR__ . '/../uploads/' . $filename );
// Perform OCR on the uploaded image $text = $tesseract -> recognize (); $number = findPhoneNumber ( $text , 'GB' );
return $app -> json (
[
'number' => $number ,
]
);
});
Теперь у нас есть простой API — и, следовательно, ответ JSON, — который мы могли бы использовать, например, в качестве серверной части простого мобильного приложения для добавления контактов или осуществления вызовов с печатного номера телефона.
Резюме
OCR имеет много приложений — и его легче интегрировать в ваши приложения, чем вы могли ожидать. В этой статье мы установили пакет OCR с открытым исходным кодом; и, используя библиотеку-оболочку, интегрировал ее в очень простое PHP-приложение. Мы только коснулись поверхности того, что возможно, но, надеюсь, это дало вам некоторые идеи относительно того, как вы можете использовать эту технологию в своих собственных приложениях.