Индексирование является одной из наиболее важных концепций работы с MongoDB. Правильное понимание имеет решающее значение, поскольку индексирование может значительно повысить производительность и пропускную способность за счет сокращения количества документов, которые необходимо прочитать, и, следовательно, повышения производительности нашего приложения. Поскольку индексы могут быть немного сложными для понимания, в этой серии из двух частей мы рассмотрим их более подробно.
В этой статье мы рассмотрим следующие пять типов индексов:
- Индекс _id по умолчанию
- Вторичный индекс
- Составной индекс
- Multikey Index
- Multikey Compound Index
Есть и другие типы для обсуждения, но я логично сохранил их для второй части, чтобы обеспечить четкое понимание и избежать путаницы.
Хотя в коллекции можно определить более одного индекса, запрос может использовать только один индекс во время своего выполнения. Решение о выборе лучшего индекса из доступных опций принимается во время выполнения оптимизатором запросов MongoDB.
В этой статье предполагается, что у вас есть базовое понимание концепций MongoDB (например, коллекций, документов и т. Д.) И выполнения базовых запросов с использованием PHP (например, поиска и вставки). Если нет, я предлагаю вам прочитать наши статьи для начинающих: Введение в MongoDB и MongoDB Revisited .
Для серии мы предположим, что у нас есть коллекция с именем posts заполненная 500 документами, имеющими следующую структуру:
{ "_id": ObjectId("5146bb52d852470060001f4"), "comments": { "0": "This is the first comment", "1": "This is the second comment" }, "post_likes": 40, "post_tags": { "0": "MongoDB", "1": "Tutorial", "2": "Indexing" }, "post_text": "Hello Readers!! This is my post text", "post_type": "private", "user_name": "Mark Anthony" }
Теперь давайте подробно рассмотрим различные типы индексации.
Индекс _id по умолчанию
По умолчанию MongoDB создает индекс по умолчанию в поле _id для каждой коллекции. Каждый документ имеет уникальное поле _id в качестве первичного ключа, 12-байтовый ObjectID. Когда нет других доступных индексов, это используется по умолчанию для всех видов запросов.
Чтобы просмотреть индексы для коллекции, откройте оболочку MongoDB и выполните следующие действия:

Метод getIndexes() возвращает все индексы для нашей коллекции. Как видите, у нас есть индекс по умолчанию с именем _id_ . Поле key указывает, что индекс находится в поле _id , а значение 1 указывает возрастающий порядок. Мы узнаем о заказе в следующем разделе.
Вторичный индекс
Для случаев, когда мы хотим использовать индексирование для полей, отличных от _id field, мы должны определить пользовательские индексы. Предположим, мы хотим искать сообщения на основе поля user_name . В этом случае мы определим пользовательский индекс в поле user_name коллекции. Такие пользовательские индексы, отличные от индекса по умолчанию, называются вторичными индексами.
Чтобы продемонстрировать влияние индексации на базу данных, давайте кратко проанализируем производительность запросов без предварительной индексации. Для этого мы выполним запрос, чтобы найти все сообщения с user_name с «Jim Alexandar».
<?php // query to find posts with user_name "Jim Alexandar" $cursor = $collection->find( array("user_name" => "Jim Alexandar") ); // use explain() to get explanation of query indexes var_dump($cursor->explain());
Важный метод, часто используемый при индексировании, — метод explain() который возвращает информацию, относящуюся к индексации. Вывод вышеупомянутого explain() показан ниже:

Вот некоторые важные ключи, на которые стоит обратить внимание:
-
cursor— указывает индекс, используемый в запросе. BasicCursor указывает, что использовался индекс _id по умолчанию, и MongoDB пришлось искать всю коллекцию. В дальнейшем мы увидим, что когда мы применяем индексацию, вместо BasicCursor будет использоваться BtreeCursor . -
n— указывает количество документов, возвращенных запросом (в данном случае один документ). -
nscannedObjects— указывает количество документов,nscannedObjectsпо запросу (в этом случае были найдены все 500 документов коллекции). Это может быть операция с большими накладными расходами, если количество документов в коллекции очень велико. -
nscanned— указывает количество документов, отсканированных во время работы базы данных.
В идеале n должно быть равно или близко к nscanned , что означает, что было nscanned минимальное количество документов.
Теперь давайте выполним тот же запрос, но с использованием вторичного индекса. Чтобы создать индекс, выполните в оболочке MongoDB следующее:

Мы создали индекс для user_name field ensureIndex() коллекции posts используя метод ensureIndex() . Я уверен, что вы указали значение аргумента order для метода, который указывает на возрастающий (1) или убывающий (-1) порядок поиска. Чтобы лучше это понять, обратите внимание, что у каждого документа есть поле метки времени. Если мы хотим сначала получить самые последние сообщения, мы бы использовали нисходящий порядок. Для самых старых постов сначала мы бы выбрали возрастающий порядок.
После создания индекса для выполнения и анализа запроса используются те же методы find() и explain() , что и раньше. Вывод:
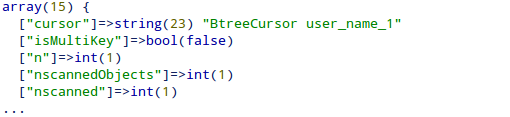
Выходные данные показывают, что запрос использовал BtreeCursor с именем user_name_1 (который мы определили ранее) и отсканировал только один документ в отличие от 500 документов, найденных в предыдущем запросе, без индексации.
Пока что следует понимать, что все индексы MongoDB используют структуру данных BTree в своем алгоритме, а BtreeCursor является курсором по умолчанию для него. Подробное обсуждение BTreeCursor выходит за рамки данной статьи, но это не влияет на дальнейшее понимание.
Приведенное выше сравнение показывает, как индексы могут значительно повысить производительность запросов.
Составной индекс
Будут случаи, когда запрос использует более одного поля. В таких случаях мы можем использовать составные индексы. Рассмотрим следующий запрос, в котором используются поля post_type и post_likes :
<?php // query to find posts with type public and 100 likes $cursor = $collection->find( array( "post_type" => "public", "post_likes" => 100 ), array() );
Анализ этого запроса с использованием BasicCursor explain() дает следующий результат, который показывает, что в запросе используется BasicCursor и все 500 документов сканируются для получения одного документа.

Это крайне неэффективно, поэтому давайте применим некоторые индексы. Мы можем определить составной индекс для полей post_type и post_likes следующим образом:

Анализ запроса теперь дает следующий результат:

Здесь очень важно отметить, что составные индексы, определенные для нескольких полей, могут использоваться для запроса подмножества этих полей. Например, предположим, что существует составной индекс {field1,field2,field3} . Этот индекс может быть использован для запроса:
-
field1 -
field1, field2 -
field1, field2, field3
Итак, если мы определили индекс {field1,field2,field3} , нам не нужно определять отдельные {field1} и {field1,field2} . Однако, если нам нужен этот составной индекс при запросе field2 и field2,field3 , мы можем использовать hint() если оптимизатор не выберет нужный индекс.
Метод hint() можно использовать, чтобы заставить MongoDB использовать заданный нами индекс и переопределить процесс выбора по умолчанию и оптимизации запросов. Вы можете указать имена полей, используемые в индексе в качестве аргумента, как показано ниже:
<?php // query to find posts with type public and 100 likes // use hint() to force MongoDB to use the index we created $cursor = $collection ->find( array( "post_type" => "public", "post_likes" => 100 ) ) ->hint( array( "post_type" => 1, "post_likes" => 1 ) );
Это гарантирует, что запрос использует составной индекс, определенный в post_type и post_likes .
Multikey Index
Когда индексирование выполняется для поля массива, оно называется индексом нескольких ключей. Рассмотрим наш post документ еще раз; мы можем применить многопользовательский индекс для post_tags . Индекс multikey будет индексировать каждый элемент массива, поэтому в этом случае будут созданы отдельные индексы для значений post_tags : MongoDB , Tutorial , Indexing и т. Д.

Однако индексы в полях массива должны использоваться очень избирательно, так как они занимают много памяти из-за индексации каждого значения.
Multikey Compound Index
Мы можем создать составной индекс с несколькими ключами, но с ограничением, что не более одного поля в индексе может быть массивом. Таким образом, если у нас есть field1 как строка и [field2, field3] как массив, мы не можем определить индекс {field2,field3} так как оба поля являются массивами.
В приведенном ниже примере мы создаем индекс для post_tags и post_tags :

Ограничения индексации и соображения
Важно знать, что индексирование нельзя использовать в запросах, в которых используются регулярные выражения, операторы отрицания (т. $ne , $not и т. Д.), Арифметические операторы (т. $mod и т. Д.), Выражения JavaScript в $where пункт, а в некоторых других случаях.
Индексирование также осуществляется за счет собственных затрат. Каждый индекс занимает место, а также вызывает дополнительные издержки при каждой операции вставки, обновления и удаления в коллекции. Вы должны учитывать соотношение чтение: запись для каждой коллекции; индексация полезна для коллекций с интенсивным чтением, но может не подходить для коллекций с интенсивным чтением.
MongoDB хранит индексы в оперативной памяти. Убедитесь, что общий размер индекса не превышает ограничение ОЗУ. Если это произойдет, некоторые индексы будут удалены из ОЗУ и, следовательно, запросы будут замедляться. Кроме того, коллекция может содержать не более 64 индексов.
Резюме
Вот и все для этой части. Подводя итог, индексы очень полезны для приложения, если выбран правильный подход к индексации. В следующей части мы рассмотрим использование индексов во встроенных документах, вложенных документах и упорядочении. Будьте на связи!
Изображение через Fotolia