Когда с нашими приложениями дела идут плохо — как они иногда делают, нравится нам это или нет — наши файлы журналов, как правило, являются одними из первых мест, куда мы идем, когда начинаем процесс устранения неполадок. Большое «но» здесь заключается в том, что, несмотря на тот факт, что файлы журналов содержат множество полезной информации о событиях, их обычно чрезвычайно трудно расшифровать.
Современная среда веб-приложений состоит из нескольких источников журналов, которые вместе выводят тысячи строк журнала, написанных на неразборчивом машинном языке. Если, например, у вас настроен стек LAMP, то вам нужно пройти через журналы PHP, Apache и MySQL. Добавьте журналы системы и среды в бой — вместе с журналами, специфичными для фреймворка, такими как журналы Laravel, — и вы получите бесконечную кучу машинных данных.
Поговорим о иголке в стоге сена.

Стек ELK ( Elasticsearch , Logstash и Kibana ) быстро становится самым популярным способом решения этой проблемы. По словам Elastic, самая популярная платформа для анализа журналов с открытым исходным кодом — 500 000 загрузок в месяц — ELK — отличный способ централизовать журналы из нескольких источников, определять корреляции и выполнять глубокий анализ данных.
Elasticsearch — это поисково-аналитический движок, основанный на Apache Lucene, который позволяет пользователям искать и анализировать большие объемы данных практически в реальном времени. Logstash может принимать и пересылать журналы из любого места в любое место. Kibana — это симпатичное лицо стека — пользовательский интерфейс, который позволяет легко запрашивать, визуализировать и исследовать данные Elasticsearch.
В этой статье описывается, как настроить ELK Stack в локальной среде разработки, пересылать журналы веб-сервера (в данном случае журналы Apache) в Elasticsearch с помощью Logstash, а затем анализировать данные в Kibana.
Установка Java
Для стека ELK требуется Java 7 и выше (поддерживаются только Java Oracle и OpenJDK), поэтому в качестве начального шага обновите систему и выполните следующее:
sudo apt-get install default-jre Установка ELK
Существует множество способов установки стека ELK — вы можете использовать Docker, Ansible, Vagrant, Microsoft Azure, AWS или размещенное решение ELK — просто сделайте свой выбор. Существует огромное количество руководств и руководств, которые помогут вам на этом пути, одним из которых является это руководство по стекам ELK, которое мы на Logz.io собрали вместе.
Установка Elasticsearch
Мы собираемся начать процесс установки с установки Elasticsearch. Существуют различные способы настройки Elasticsearch, но мы будем использовать Apt.
Сначала загрузите и установите открытый ключ подписи Elastic:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Затем сохраните определение репозитория в /etc/apt/sources.list.d/elasticsearch-2.x.list :
echo "deb http://packages.elastic.co/elasticsearch/2.x/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-2.x.list
И последнее, но не менее важное: обновите кэш репозитория и установите Elasticsearch:
sudo apt-get update && sudo apt-get install elasticsearch
Elasticsearch теперь установлен. Прежде чем мы перейдем к следующим компонентам, мы немного подправим файл конфигурации:
sudo nano /etc/elasticsearch/elasticsearch.yml
Некоторые общие конфигурации включают ограничение внешнего доступа к Elasticsearch, поэтому данные не могут быть взломаны или удалены через HTTP API:
network.host: localhost
Теперь вы можете перезапустить Elasticsearch:
sudo service elasticsearch restart
Чтобы убедиться, что Elasticsearch работает правильно, запросите следующий URL-адрес с помощью команды cURL:
sudo curl 'http://localhost:9200'
Вы должны увидеть следующий вывод в вашем терминале:
{ "name" : "Jebediah Guthrie", "cluster_name" : "elasticsearch", "version" : { "number" : "2.3.1", "build_hash" : "bd980929010aef404e7cb0843e61d0665269fc39", "build_timestamp" : "2016-04-04T12:25:05Z", "build_snapshot" : false, "lucene_version" : "5.5.0" }, "tagline" : "You Know, for Search" }
Для запуска службы при загрузке выполните:
sudo update-rc.d elasticsearch defaults 95 10
Установка Logstash
Logstash, «L» в «ELK Stack», используется в начале конвейера журналов, принимает и собирает данные перед отправкой в Elasticsearch.
Чтобы установить Logstash, добавьте определение хранилища в файл /etc/apt/sources.list :
echo "deb http://packages.elastic.co/logstash/2.2/debian stable main" | sudo tee -a /etc/apt/sources.list
Обновите систему, чтобы репозиторий был готов к использованию, а затем установите Logstash:
sudo apt-get update && sudo apt-get install logstash
Мы вернемся к Logstash позже, чтобы настроить доставку журналов в Elasticsearch.
Установка Кибана
Последняя часть головоломки — Kibana — красивое лицо стека ELK. Сначала создайте список источников Kibana:
echo "deb http://packages.elastic.co/kibana/4.5/debian stable main" | sudo tee -a /etc/apt/sources.list
Затем обновите и установите Kibana:
sudo apt-get update && apt-get install kibana
Настройте файл конфигурации /opt/kibana/config/kibana.yml адресу /opt/kibana/config/kibana.yml :
sudo vi /opt/kibana/config/kibana.yml
Раскомментируйте следующие строки:
server.port: 5601 server.host: “0.0.0.0”
И последнее, но не менее важное, начать Kibana:
sudo service kibana start
Вы можете получить доступ к Kibana в своем браузере по адресу http://localhost:5601/ (измените URL, если вы используете виртуальную машину типа Homestead Improved для того, какой хост / порт вы настроили):
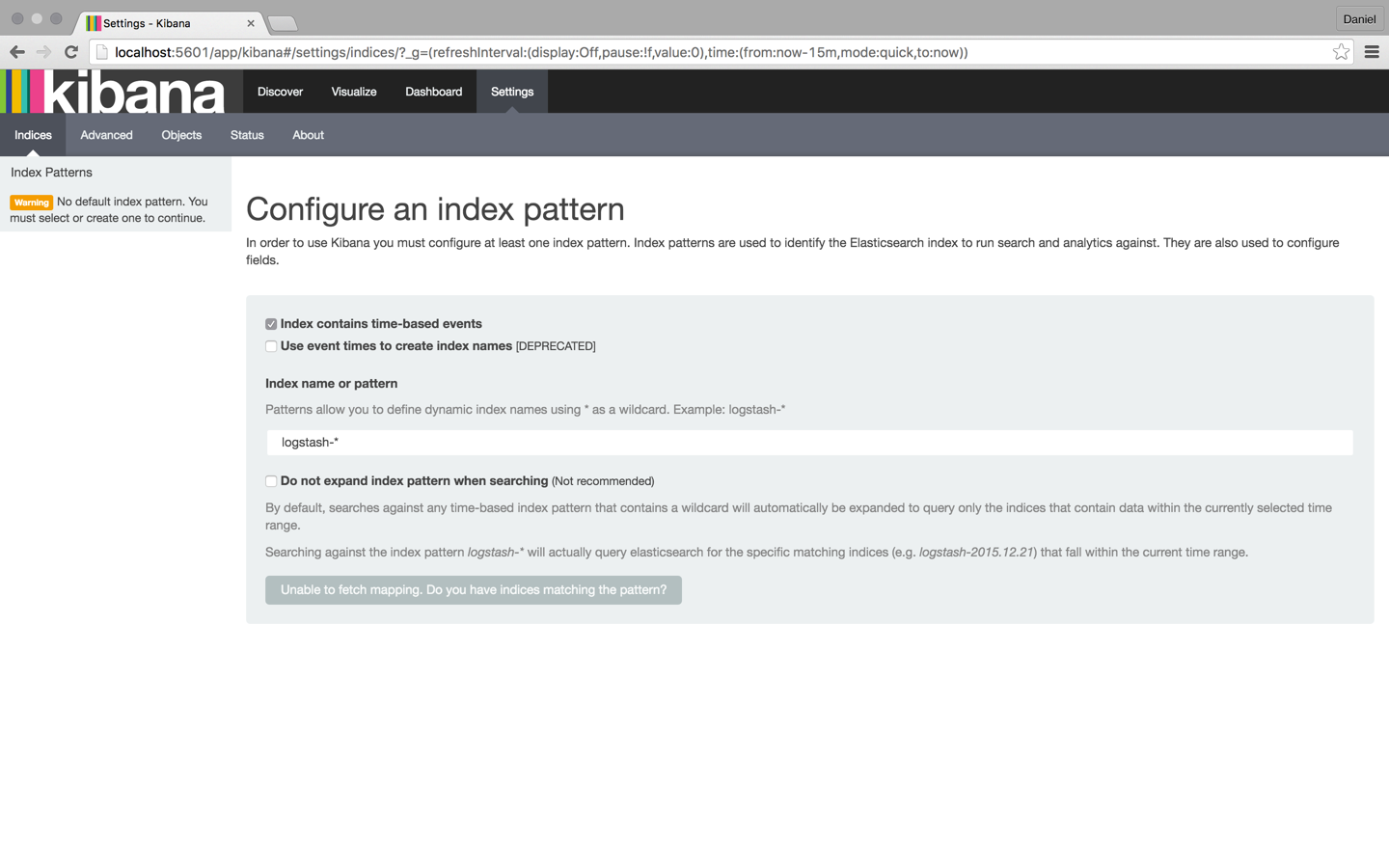
Чтобы начать анализ журналов в Кибане, необходимо определить хотя бы один шаблон индекса. Индекс — это то, как Elasticsearch организует данные, и его можно сравнить с базой данных в мире RDBMS с отображением, определяющим несколько типов.
Вы заметите, что, поскольку мы еще не отправили какие-либо журналы, Kibana не может получить сопоставление (как показано серой кнопкой в нижней части страницы). Мы позаботимся об этом в следующие несколько шагов.
Совет: по умолчанию Kibana подключается к экземпляру Elasticsearch, работающему на локальном хосте, но вы можете подключиться к другому экземпляру Elasticsearch. Просто измените URL-адрес Elasticsearch в файле конфигурации Kibana, который вы редактировали ранее, а затем перезапустите Kibana.
Доставка журналов
Наш следующий шаг — настроить конвейер журналов в Elasticsearch для индексации и анализа с использованием Kibana. Существуют различные способы пересылки данных в Elasticsearch, но мы собираемся использовать Logstash.
Файлы конфигурации Logstash написаны в формате JSON и находятся в /etc/logstash/conf.d . Конфигурация состоит из трех разделов плагина: вход, фильтр и выход.
Создайте файл конфигурации с именем apache-logs.conf :
sudo vi /etc/logstash/conf.d/apache-logs.conf
Наша первая задача — настроить секцию ввода, которая определяет, откуда берутся данные.
В этом случае мы собираемся определить путь к нашему журналу доступа Apache, но вы можете ввести путь к любому другому набору файлов журналов (например, путь к журналам ошибок PHP).
Однако перед тем, как сделать это, я рекомендую немного изучить поддерживаемые входные плагины и узнать, как их определить. В некоторых случаях рекомендуются другие средства пересылки журналов, такие как Filebeat и Fluentd .
Входная конфигурация:
input { file { path => "/var/log/apache2/access.log" type => "apache-access" } }
Наша следующая задача — настроить фильтр.
Плагины фильтров позволяют нам брать наши необработанные данные и пытаться понять их. Одним из таких плагинов является Grok — плагин, используемый для получения структуры из неструктурированных данных. Используя grok, вы можете определить поиск и извлечь часть ваших строк журнала в структурированные поля.
filter { if [type] == "apache-access" { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } } }
Последний раздел файла конфигурации Logstash — это раздел «Вывод», который определяет местоположение, куда отправляются журналы. В нашем случае это наш локальный экземпляр Elasticsearch на нашем локальном хосте:
output { elasticsearch {} }
Вот и все. Как только вы закончите, запустите Logstash с новой конфигурацией:
/opt/logstash/bin/logstash -f /etc/logstash/conf.d/apache-logs.conf
Вы должны увидеть следующий вывод JSON из Logstash, указывающий, что все в порядке:
{ "message" => "127.0.0.1 - - [24/Apr/2016:11:41:59 +0000] \"GET / HTTP/1.1\" 200 11764 \"-\" \"curl/7.35.0\"", "@version" => "1", "@timestamp" => "2016-04-24T11:43:34.245Z", "path" => "/var/log/apache2/access.log", "host" => "ip-172-31-46-40", "type" => "apache-access", "clientip" => "127.0.0.1", "ident" => "-", "auth" => "-", "timestamp" => "24/Apr/2016:11:41:59 +0000", "verb" => "GET", "request" => "/", "httpversion" => "1.1", "response" => "200", "bytes" => "11764", "referrer" => "\"-\"", "agent" => "\"curl/7.35.0\"" }
Обновите Kibana в своем браузере, и вы заметите, что шаблон индекса для наших журналов Apache был идентифицирован:
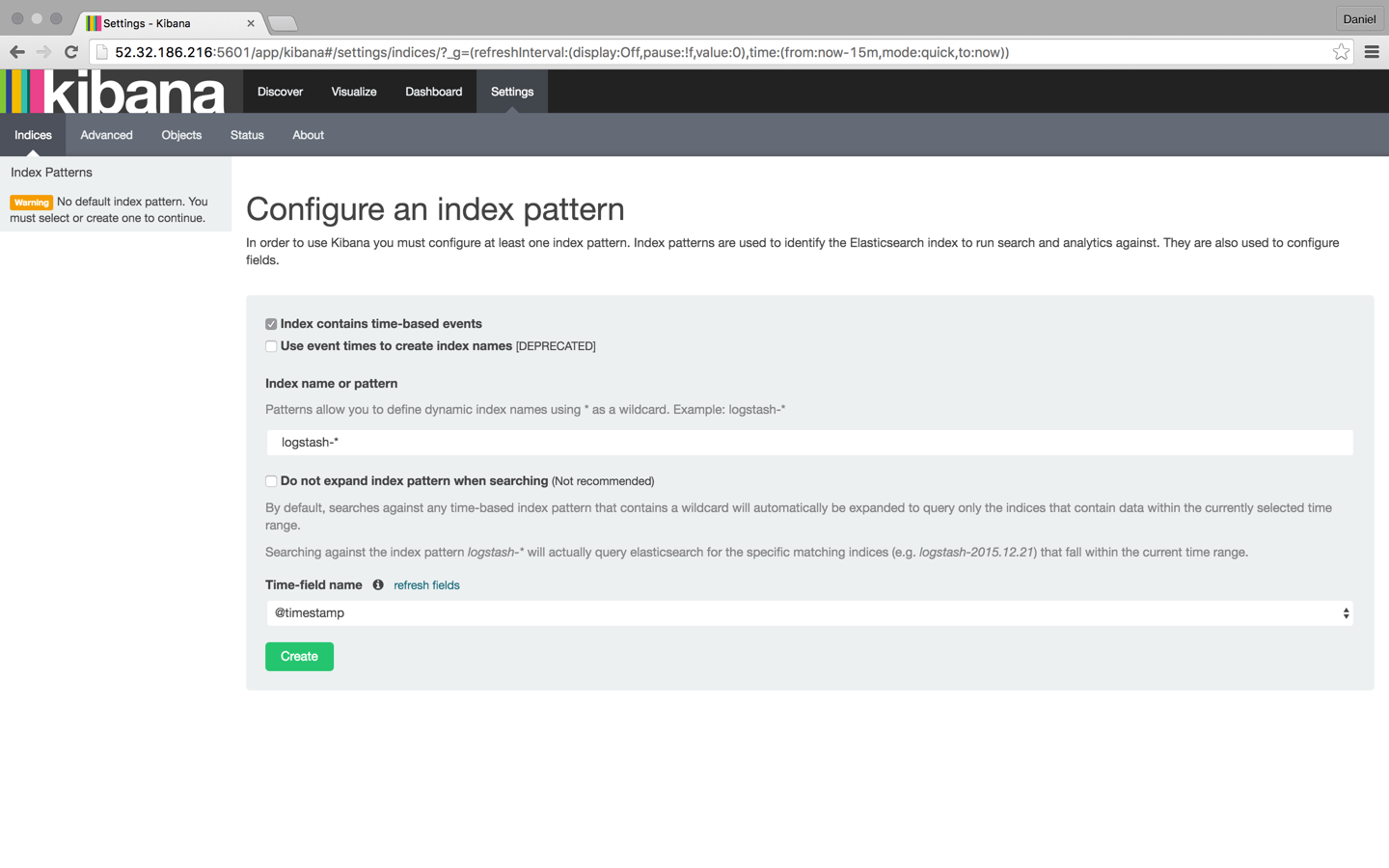
Нажмите кнопку « Создать» , а затем выберите вкладку «Обнаружение»:
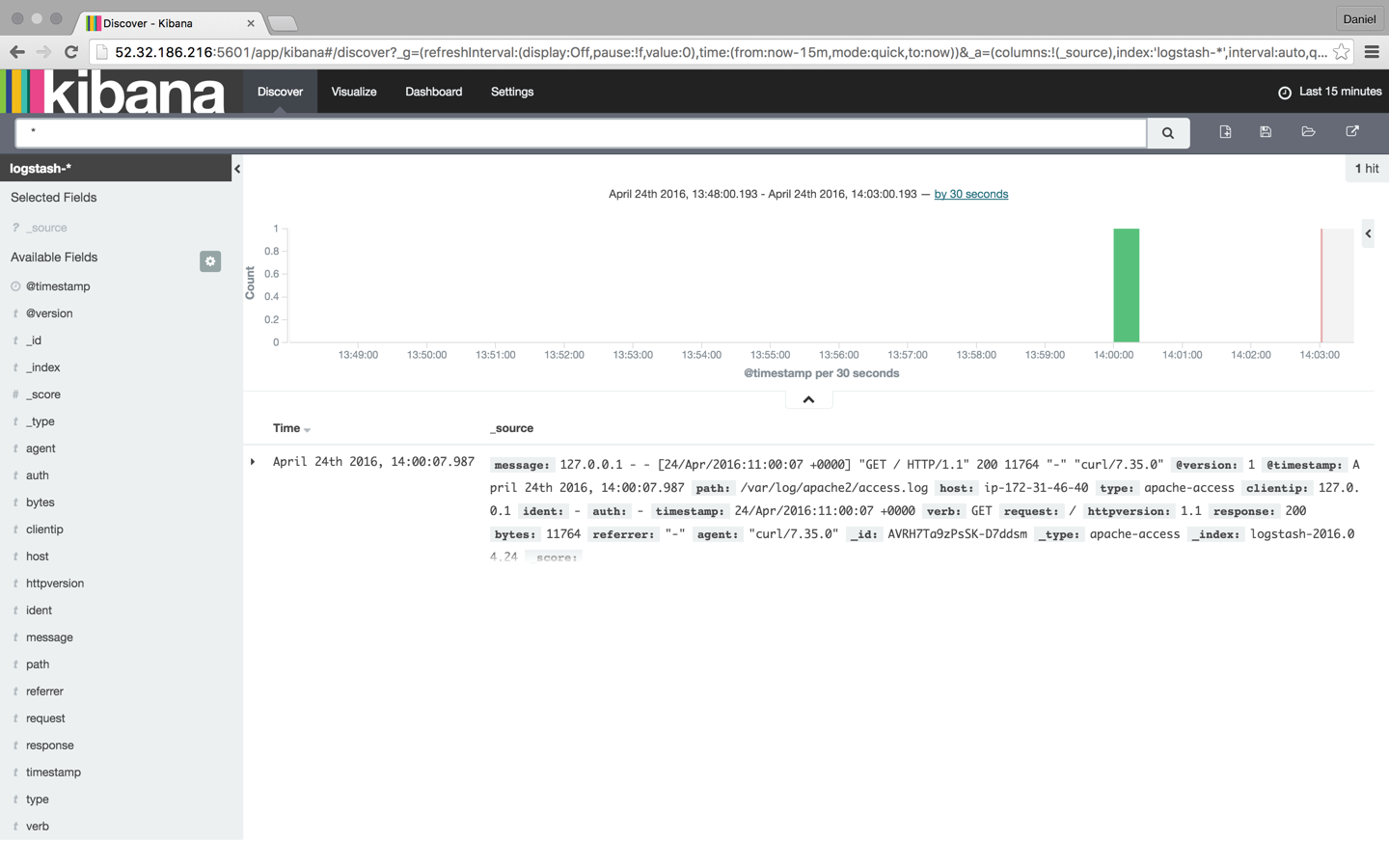
С этого момента Logstash настраивает журнал доступа Apache для сообщений, чтобы любые новые записи были перенаправлены в Elasticsearch.
Анализировать логи
Теперь, когда наш трубопровод запущен, пришло время повеселиться.
Чтобы было немного интереснее, давайте смоделируем шум на нашем веб-сервере. Для этого я собираюсь скачать несколько примеров журналов Apache и вставить их в журнал доступа Apache. Logstash уже следит за этим журналом, поэтому эти сообщения будут проиндексированы в Elasticsearch и отображены в Kibana:
wget http://logz.io/sample-data sudo -i cat /home/ubuntu/sample-data >> /var/log/apache2/access.log exit
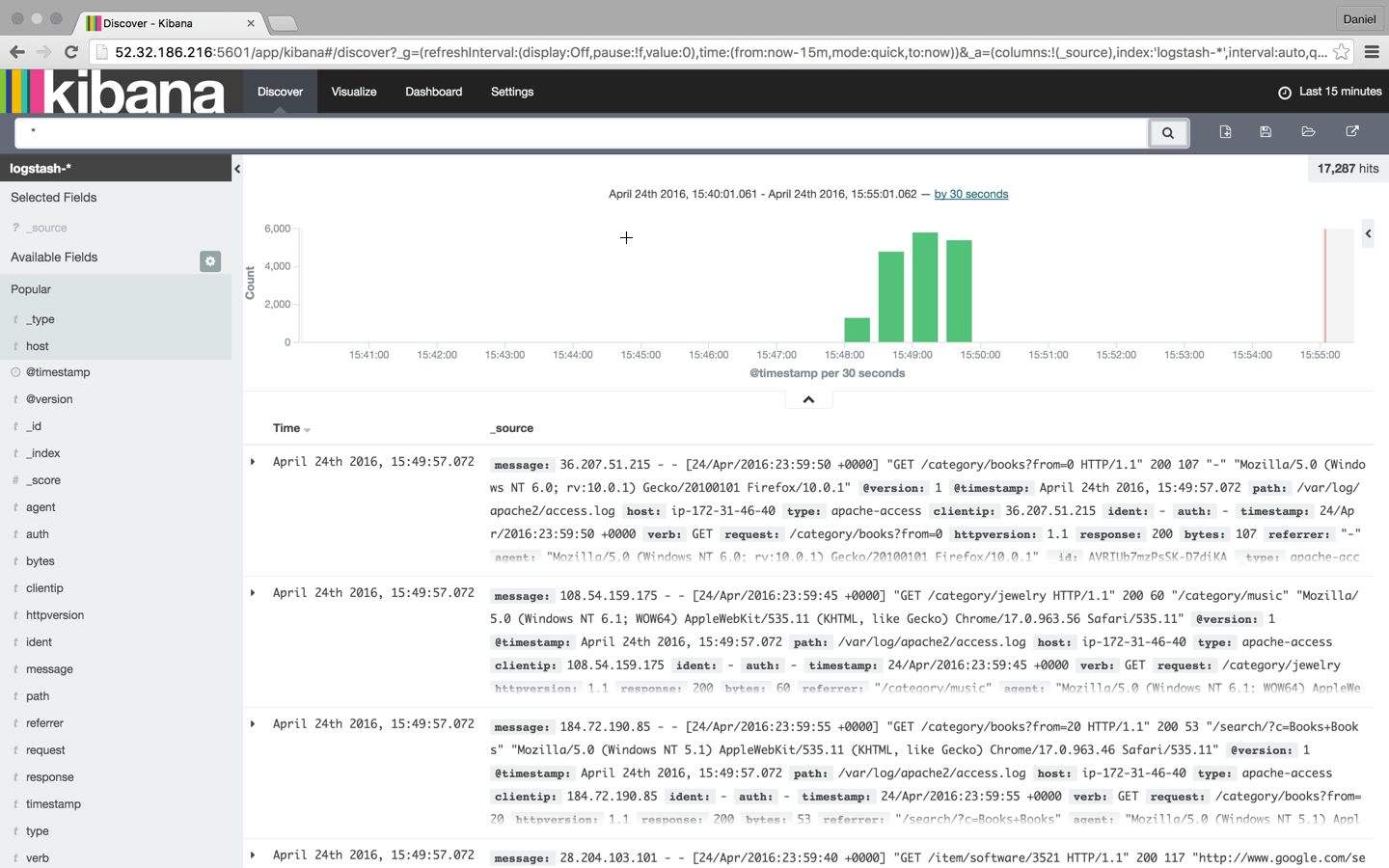
Поиск
Поиск — это хлеб с маслом из стека ELK, и это искусство само по себе. В Интернете доступно большое количество документации, но я подумал, что смогу охватить все необходимое, чтобы у вас была прочная база для начала геологоразведочных работ.
Давайте начнем с нескольких простых поисков.
Самый простой поиск — это поиск по «свободному тексту», который выполняется по всем проиндексированным полям. Например, если вы анализируете журналы веб-сервера, вы можете выполнить поиск для определенного типа браузера (поиск выполняется с помощью широкого поля поиска в верхней части страницы):
Chrome
Важно отметить, что поиск в свободном тексте НЕ учитывает регистр, если вы не используете двойные кавычки, и в этом случае результаты поиска показывают точное совпадение с вашим запросом.
“Chrome”
Далее идут поиски на уровне поля.
Для поиска значения в определенном поле необходимо добавить имя поля в качестве префикса к значению:
type:apache-access
Скажем, например, что вы ищете конкретный ответ веб-сервера. Введите response:200 чтобы ограничить результаты теми, которые содержат этот ответ.
Вы также можете искать диапазон в поле. Если вы используете скобки [], результаты будут включительно. Если вы используете фигурные скобки {}, результаты исключат указанные значения в запросе.
Теперь пришло время заняться этим на ступеньку выше.
Следующие типы поиска включают использование логических операторов. Они интуитивно понятны, но требуют некоторого изящества, потому что они чрезвычайно чувствительны к синтаксису.
Эти операторы включают использование логических операторов AND, OR и NOT:
type:apache-access AND (response:400 OR response:500)
В приведенном выше поиске я ищу журналы доступа Apache с ответом 400 или 500. Обратите внимание на использование скобок в качестве примера того, как могут быть построены более сложные запросы.
Доступно еще много вариантов поиска (для получения дополнительной информации я рекомендую обратиться к руководству Logib.io по Kibana ), например регулярные выражения, нечеткие поиски и поиски близости, но как только вы определили необходимые данные, вы можете сохранить поиск на будущее. ссылка и в качестве основы для создания визуализаций Kibana.
Визуальное
Одной из наиболее ярких особенностей стека ELK в целом и Kibana в частности является возможность создавать красивые визуализации с использованием данных. Затем эти визуализации можно объединить в сводную панель, которую можно использовать для получения полного представления обо всех различных файлах журнала, поступающих в Elasticsearch.
Чтобы создать визуализацию, выберите вкладку «Визуализация» в Kibana:
Есть несколько типов визуализации, которые вы можете выбрать, и какой тип вы выберете, будет сильно зависеть от цели и конечного результата, которого вы пытаетесь достичь. В этом случае я собираюсь выбрать хорошую старую круговую диаграмму.
Затем у нас есть другой выбор — мы можем создать визуализацию либо из сохраненного поиска, либо из нового поиска. В этом случае мы идем с последним.
Наш следующий шаг — настроить различные метрики и агрегаты для осей X и Y графа. В этом случае мы будем использовать весь индекс в качестве базы поиска (не вводя поисковый запрос в поле поиска), а затем сопоставим данные с типом браузера: Chrome, Firefox, Internet Explorer и Safari:
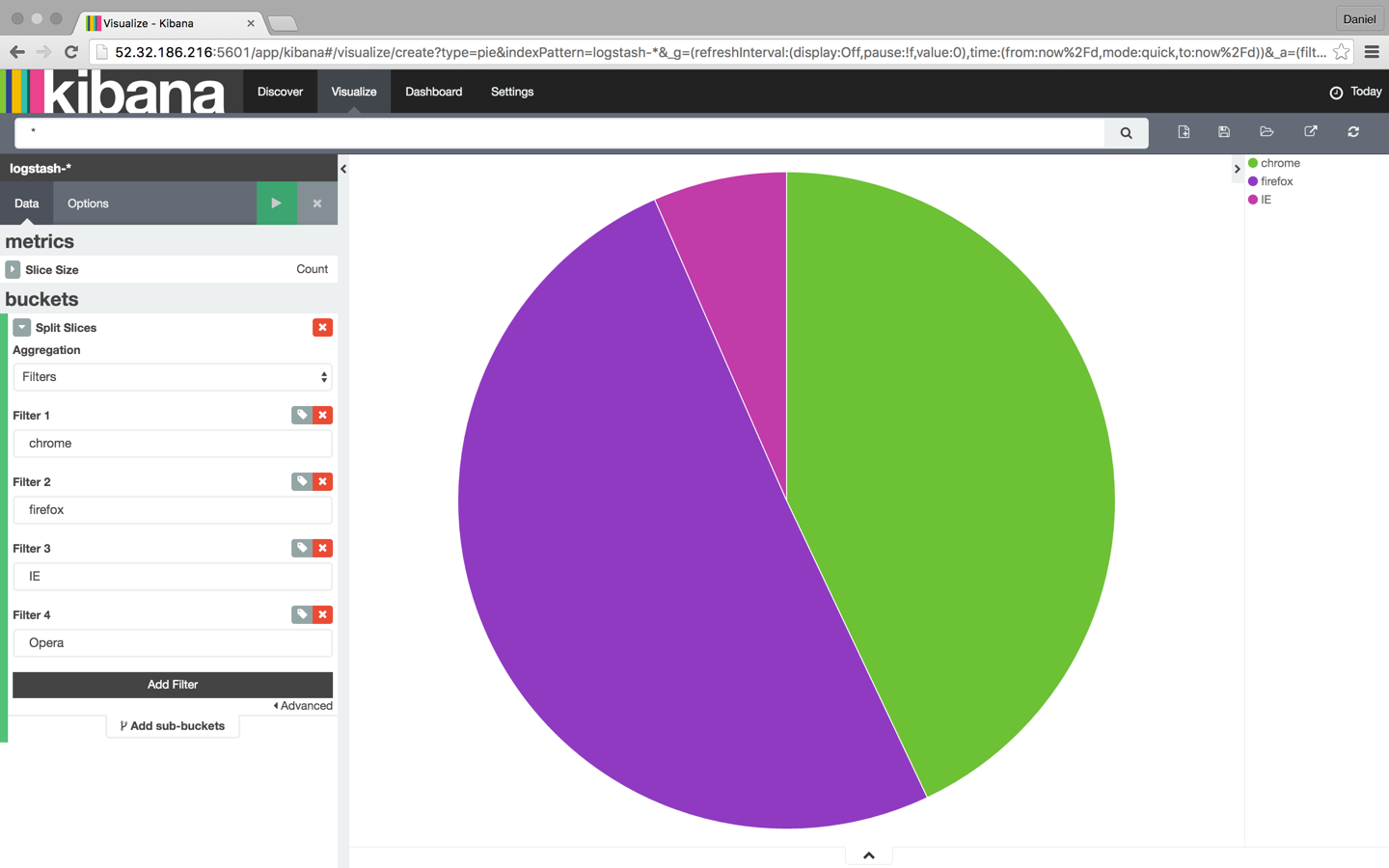
Как только вы закончите, сохраните визуализацию. Затем вы можете добавить его на пользовательскую панель инструментов на вкладке «Панель инструментов» в Kibana.
Визуализации — это невероятно богатые инструменты, и они — лучший способ понять тенденции в ваших данных.
Вывод
Стек ELK становится способом анализа и управления журналами. Тот факт, что стек является открытым исходным кодом и поддерживается сильным сообществом и быстрорастущей экосистемой, способствует его популярности.
DevOps — не единственная сфера анализа логов, и ELK используется разработчиками, системными администраторами, SEO-экспертами и маркетологами. Разработка на основе журналов — процесс разработки, при котором код отслеживается с использованием метрик, оповещений и журналов — набирает обороты во все большем количестве научно-исследовательских групп, и не будет большой натяжкой связывать это с растущей популярностью ELK ,
Конечно, ни одна система не является идеальной, и есть недостатки, которые пользователи должны избегать, особенно при работе с большими производственными операциями. Но это не должно удерживать вас от попыток, особенно потому, что существует множество источников информации, которые помогут вам в этом процессе.
Удачи и счастливого индексирования!
Эта статья была рецензирована Кристофером Томасом , Юнесом Рафи и Скоттом Молинари . Спасибо всем рецензентам SitePoint за то, что сделали контент SitePoint как можно лучше!