В первой части этой серии мы узнали, как извлечь упакованные объекты из устаревшей базы данных Access. Во второй части мы узнаем, как извлечь документы Acrobat PDF и кратко рассмотрим выбор форматов изображений.
Единственное сходство, которое имеют PDF, GIF, PNG и т. Д. При хранении в базе данных Access, заключается в том, что все они заключены в контейнер OLE, состоящий из заголовка переменной длины и трейлера. Как мы увидим, трейлер можно игнорировать, как это было с пакетом, рассмотренным в части 1. Заголовок более полезен, но не содержит всей необходимой нам информации.
Adobe Acrobat Documents
В тестовой базе данных, использованной для этой статьи, в записи № 13 хранится файл PDF:
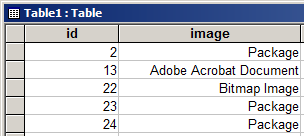
Идентификация документа Adobe Acrobat (PDF) в поле объекта OLE базы данных Access выполняется с помощью того же метода, который мы изучили в части 1 — проверять первые пятьдесят или около того байтов в поисках распознаваемой последовательности символов.
Применение того же метода извлечения фрагмента данных из поля OLE, затем преобразование его из шестнадцатеричного в десятичное и отображение его в шестнадцатеричном просмотрщике, дает понять, что, хотя у нас определенно есть PDF, сохраненный в поле, у нас нет другого информация, такая как оригинальное имя PDF или его оригинальный размер файла:
К счастью, есть еще один метод, который мы можем использовать для извлечения PDF. Каждый PDF всегда начинается с последовательности символов% PDF и заканчивается последовательностью %% END. Это можно легко проверить, загрузив небольшой PDF-файл в текстовом редакторе. В качестве альтернативы загрузите один в шестнадцатеричный просмотрщик

Здесь я показал только первые и последние несколько байтов, так как именно здесь находятся разделители PDF. Следующий шаг — применить этот метод к содержимому поля OLE и найти местоположение начала и конца и внедренного PDF:

Обратите внимание, что это шестнадцатеричные последовательности символов, которые мы должны искать; то есть при использовании PHP-функции strpos()
Так что у нас сейчас? Мы определили объект OLE как тип документа Acrobat, и у нас есть начальное и конечное расположение внедренного файла. Таким образом, у нас есть все, что нужно для извлечения исходного файла из поля OLE с помощью функции PHP substr()
Другие типы объектов
Прежде чем обсуждать популярные типы изображений, стоит потратить некоторое время на то, чтобы улучшить оператор switch Было бы гораздо полезнее, если бы какие-либо неизвестные типы OLE были извлечены и сохранены на диск для последующего анализа. Новая функция extractUnknown() Это позволяет нам позже просматривать любой неизвестный тип OLE в шестнадцатеричном средстве просмотра, чтобы определить тип внедренного объекта. Нам понадобится это в следующем разделе, чтобы определить, какие записи имеют встроенные изображения.
<?php
function extractUnknown($id, $data) {
// convert entire object to decimal and save to disk
file_put_contents($id . ".txt", hex2bin($data));
}
Популярные типы изображений
Невозможно с уверенностью сказать, как типы изображений будут идентифицироваться в заголовке OLE в любой заданной базе данных Access. Возможно, изображения будут идентифицированы как «Paint Shop Pro 6», или они могут быть связаны с каким-либо другим программным обеспечением для редактирования изображений. Это полностью зависит от того, какое программное обеспечение было известно системе, которая использовалась для хранения изображений, и от любых файловых ассоциаций, которые были настроены.
Чтобы узнать, что это за неизвестные типы, мы можем составить список, выполнив каждую запись с неизвестным типом OLE через extractUnknown() Это будет отличаться от множества существующих в настоящее время баз данных Access.
Форматы изображений, которые мы рассмотрим здесь: BMP, GIF, JPEG и PNG.
GIF, JPEG, PNG
«Хорошие новости, все!» Эти три типа изображений могут обрабатываться одинаково. Более того, это точно такой же метод, который использовался ранее для извлечения встроенного PDF. Сначала нам нужно найти начальную позицию внедренного изображения, затем конечную позицию, а затем извлечь все, что находится между этими двумя точками. Разница в том, как мы идентифицируем внедренный объект. Следующая таблица суммирует эти важные детали:

BMP
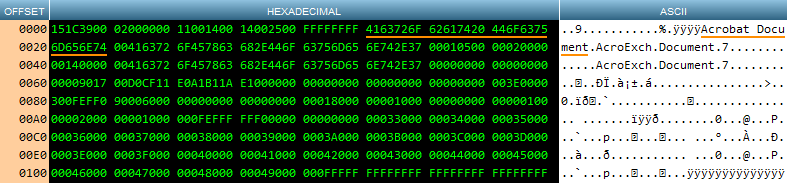
Идентификация разделителей встроенного BMP похожа, но требует немного больше работы. Найти начальную позицию так же легко, как и для типов файлов, описанных выше, но для определения конечной позиции требуется немного математики. Давайте посмотрим на два важных элемента в шестнадцатеричном вьюере:

Первые два байта (BM в ASCII), подчеркнутые оранжевым, являются начальным местоположением встроенного BMP. Следующие два байта, подчеркнутые желтым, представляют собой исходный размер BMP, сохраненный в формате с прямым порядком байтов. Размер должен быть преобразован в формат с прямым порядком байтов, а затем умножен на два, потому что объект хранится в шестнадцатеричном формате.
Учитывая, что теперь у нас есть начальная позиция и размер внедренного объекта, мы можем использовать тот же метод для извлечения BMP, который мы использовали в части 1 для извлечения объекта из пакета.
Собираем все вместе
Далее следует скрипт PHP из части 1, обновленный для включения новых функций, описанных выше. Базовая структура идентична его предыдущей версии, а дополнительные условия в операторе switch () показывают, насколько легко расширить базовую логику сценария для размещения других типов OLE.
<?php $offset = array( "Packager Shell Object" =--> 168,
"Package" => 140
);
if (!function_exists("hex2bin")) {
function hex2bin($hexStr) {
$hexStrLen = strlen($hexStr);
$binStr = "";
$i = 0;
while ($i < $hexStrLen) { $a = substr($hexStr, $i, 2); $c = pack("H*", $a); $binStr .= $c; $i += 2; } return $binStr; } } $dbName = "db1.mdb"; $db = new PDO("odbc:DRIVER={Microsoft Access Driver (*.mdb)}; DBQ=$dbName; Uid=; Pwd=;"); $sql = "SELECT * FROM Table1"; foreach ($db->query($sql) as $row) {
$objName = "";
switch (getOLEType($row["image"])) {
case "Packager Shell Object":
list($objName, $objData) = extractPackage($row["image"], $offset["Packager Shell Object"]);
break;
case "Package":
list($objName, $objData) = extractPackage($row["image"], $offset["Package"]);
break;
case "Acrobat Document":
list($objName, $objData) = extractPDF($row["id"], $row["image"]);
break;
case "Paint Shop Pro 6":
case "Bitmap Image":
list($objName, $objData) = extractImage($row["id"], $row["image"]);
break;
default:
list($objName, $objData) = extractUnknown($row["id"], $row["image"]);
}
if ($objName != "") {
file_put_contents($objName, $objData);
}
}
function extractUnknown($id, $data) {
// convert entire object to decimal and save to disk
file_put_contents($id . ".txt", hex2bin($data));
}
function extractPackage($data, $offset) {
// usable header size
$headerBlock = 500;
// find name
$tmp = substr($data, $offset, 255);
$nullPos = findNullPos($tmp);
$name = substr($tmp, 0, $nullPos);
$pos = $offset + strlen($name);
// find data
// 1st full path
list($path1, $nameLen) = findFileName($data, $name, $pos, $headerBlock);
$pos = $path1 + $nameLen;
// 2nd full path
list($path2, $nameLen) = findFileName($data, $name, $pos, $headerBlock);
// check if only one full path
if ($path2 > $pos) {
$pos = $path2 + strlen($name);
}
$oleSizePos = $pos + 2;
$oleObjSize = flipEndian(substr($data, $oleSizePos, 8), 8);
$oleHeaderEnd = $oleSizePos + 8;
$objName = hex2bin(substr($tmp, 0, $nullPos));
// extract object
$objData = getBlob($data, $oleHeaderEnd, hexdec($oleObjSize) * 2);
return array($objName, $objData);
}
function extractPDF($id, $data) {
$delimiter = array(
"pdfStart" => "25504446",
"pdfEnd" => "2525454F46"
);
// %PDF - start block common to all PDFs
$offsetStart = strpos($data, $delimiter["pdfStart"], 0);
// %%EOF - end block common to all PDFs
$offsetEnd = strpos($data, $delimiter["pdfEnd"], $offsetStart) + 12;
$objData = getBlob($data, $offsetStart, $offsetEnd - $offsetStart);
return array($id . ".pdf", $objData);
}
function extractImage($id, $data) {
$delimiter = array(
"bmpStart" => "424D",
"gifStart" => "4749463839",
"gifEnd" => "003B",
"jpgStart" => "FFD8",
"jpgEnd" => "FFD9",
"pngStart" => "89504E47",
"pngEnd" => "49454E44AE426082"
);
$objName = "";
if (strpos($data, $delimiter["bmpStart"], 0) !== false) { // is object a BMP
list($objName, $objData) = extractBMP($id, $data, $delimiter["bmpStart"]);
}
elseif (strpos($data, $delimiter["gifStart"], 0) !== false) { // is object a GIF89
list($objName, $objData) = extractGIF($id, $data, $delimiter["gifStart"], $delimiter["gifEnd"]);
}
elseif (strpos($data, $delimiter["jpgStart"], 0) !== false) { // is object a JPEG
list($objName, $objData) = extractJPEG($id, $data, $delimiter["jpgStart"], $delimiter["jpgEnd"]);
}
elseif (strpos($data, $delimiter["pngStart"], 0) !== false) { // is object a PNG
list($objName, $objData) = extractPNG($id, $data, $delimiter["pngStart"], $delimiter["pngEnd"]);
}
else {
// other image types in here
}
// save to disk if object was found
if ($objName != "") {
file_put_contents($objName, $objData);
}
}
function extractBMP($id, $data, $bmpStart) {
$oleObjStart = strpos($data, $bmpStart, 0);
$oleObjSize = hexdec( flipEndian(substr($data, $oleObjStart+4, 8), 8) );
// extract object
$objData = getBlob($data, $oleObjStart, $oleObjSize * 2);
return array($id.".bmp", $objData);
}
function getBlob($data, $start, $end) {
return hex2bin(substr($data, $start, $end));
}
function flipEndian($data, $size) {
$str = "";
for ($i = $size - 2; $i >= 0; $i -= 2) {
$str .= substr($data, $i, 2);
}
return $str;
}
function findNullPos($str) {
// must start on a two-character boundary
return floor((strpos($str, "00") + 1) / 2) * 2;
}
function getOLEType($data) {
// fixed position of OLE type
$offset = 40;
$tmp = substr($data, $offset, 255);
$nullPos = findNullPos($tmp);
$tmp = substr($tmp, 0, $nullPos);
$type = hex2bin($tmp);
return $type;
}
function hexStrToCase($str, $case) {
$alphabet = 32;
$tmp = "";
$splitHex = array();
$splitHex = str_split($str, 2);
$splitTest = hex2bin($splitHex[0]);
foreach ($splitHex as $key => $value) {
switch ($case) {
case "upper":
if ((intval($value, 16) >= ord("a")) && (intval($value, 16) <= ord("z"))) { $splitHex[$key] = dechex(intval($value, 16) - $alphabet); } break; case "lower": if ((intval($value, 16) >= ord("A")) && (intval($value, 16) <= ord("Z"))) { $splitHex[$key] = dechex(intval($value, 16) + $alphabet); } break; } } $tmp = strtoupper(implode($splitHex)); return $tmp; } function hexStrToTilda1($str) { $strDot = "2E"; $strTilda1 = "7E31"; $tmp = hexStrToCase($str, "upper"); if (strlen($tmp) > 24) {
$dotPos = strrpos($tmp, $strDot);
$tmp = substr($tmp, 0, 12) . $strTilda1 . substr($tmp, $dotPos, 8);
}
return $tmp;
}
function findFileName($data, $str, $offset, $headerBlock) {
$strLen = 0;
$tmp = substr($data, 0, $headerBlock);
$strUpper = hexStrToCase($str, "upper");
$strLower = hexStrToCase($str, "lower");
$strTilda1 = hexStrToTilda1($str);
$strPos = stripos($tmp, $str, $offset);
if ($strPos === false) {
$strPos = stripos($tmp, $strUpper, $offset);
if ($strPos === false) {
$strPos = stripos($tmp, $strLower, $offset);
if ($strPos === false) {
$strPos = stripos($tmp, $strTilda1, $offset);
$strLen = strlen($strTilda1);
}
else {
$strLen = strlen($strLower);
}
}
else {
$strLen = strlen($strUpper);
}
}
else {
$strLen = strlen($str);
}
return array($strPos, $strLen);
}
Вы заметите, что я не включил код для функций extractGIF()extractJPEG()extractPNG() Это потому, что я оставляю это как упражнение для вас, коллег-программистов на PHP — код будет очень похож на то, что мы рассмотрели для других типов объектов OLE.
Резюме
В этой статье мы рассмотрели основные элементы извлечения PDF-файлов из полей OLE в базе данных Microsoft Access с использованием PHP. Мы также узнали, как идентифицировать определенные форматы изображений и как извлечь их из их OLE-контейнера.
Завершив это введение, состоящее из двух частей, о том, как объекты OLE хранятся в базе данных Microsoft Access и могут быть извлечены из нее, у нас теперь есть еще один инструмент, помогающий нам перейти от устаревших баз данных Access.
Вы можете получить код для этой серии на GitHub. Репо имеет две ветви — часть-1 для кода, сопровождающего первую часть, и часть-2 для кода для этой части.
Изображение через Fotolia