Вас интересуют политические события в мире? Хотите поиграть с одной из крупнейших в мире баз данных? Если вы ответили «да» на любой из этих вопросов, продолжайте читать — это вас заинтересует!
Эта статья посвящена обещанию использовать GDELT с PHP.
Я покажу вам простой пример того, как использовать GDELT через BigQuery с PHP и как визуализировать результаты на веб-странице. По пути я расскажу вам еще немного о GDELT.
GDELT
GDelt («Глобальная база данных событий, языка и тона») — крупнейшая в мире база данных открытых данных о политических событиях. Он был разработан Kalev Leetaru ( личный веб-сайт ) на основе работы Филиппа А. Шредта и других в 2011 году. Данные доступны для скачивания через zip-файлы и, начиная с 2014 года, доступны для запросов через веб-интерфейс Google BigQuery и через его API, а также с аналитической службой GDELT .
Проект GDELT :
отслеживает мировые трансляции, печатные и веб-новости почти со всех уголков каждой страны на более чем 100 языках и идентифицирует людей, местоположения, организации, количество, темы, источники, эмоции, цитаты, изображения и события, которые заставляют наше глобальное общество каждую секунду каждый день создаем бесплатную открытую платформу для вычислений по всему миру.
Интернет Эксперименты
Все данные GDELT были доступны через BigQuery. Эта база данных «больших данных» имеет веб-интерфейс, который позволяет просматривать структуры таблиц, просматривать данные и делать запросы, используя функцию автозаполнения.
Чтобы поэкспериментировать с онлайн-набором данных GDELT, вам необходимо иметь учетную запись Google. Перейдите на панель инструментов BigQuery .
Если у вас еще нет проекта Google Cloud, вам будет предложено создать его. Это обязательно. Этот проект станет вашей рабочей средой, поэтому вы можете также выбрать правильное название для него.
Вы можете создавать свои собственные запросы через «Составить запрос». Вот этот, например:
SELECT EventCode, Actor1Name, Actor2Name, SOURCEURL, SqlDate FROM [gdelt-bq:gdeltv2.events] WHERE Year = 2016 LIMIT 20 GDELT Инструменты и API
GDELT позволяет быстро создавать визуализации на своем веб-сайте. Перейдите на страницу анализа , создайте выделение, и вам будет отправлена ссылка на визуализацию.
GDELT недавно начал открывать два API, которые позволяют вам создавать пользовательские каналы данных из одного URL. Эти каналы могут быть переданы непосредственно в CartoDB для создания визуализации в реальном времени.
- GKG GeoJSON создает каналы графа знаний ( учебник )
- API полнотекстового поиска создает каналы новостей за последние 24 часа
Вы можете запросить GDELT и создать визуализации, используя инструменты, доступные каждому. Посмотрите этот недавний пример, демонстрируя беженцам некоторую любовь, которую Кеннет Дэвис сделал с данными из API GDELT Global Knowledge Graph и визуализировал с помощью CartoDB . Или этот, Как Мир видит Хиллари Клинтон и Дональда Трампа, которые CuriousGnu сделал, загрузив результаты запроса в виде файла CSV и импортировав его в CartoDB.
Концепции: Онтология CAMEO
Чтобы работать с GDELT, вам необходимо знать хотя бы некоторые основные понятия. Эти концепции были созданы Филиппом А. Шродтом и образуют онтологию CAMEO (для наблюдения за конфликтами и посредническими событиями).
- Событие — это политическое взаимодействие двух сторон. Его код события описывает тип события, то есть 1411: «Демонстрация или демонстрация смены руководства».
- Актер является одним из 2 участников мероприятия. Актером является либо страна («местная»), либо иная («международная», то есть организация, движение или компания). Коды акторов — это последовательности из одного или нескольких трехбуквенных сокращений. Например, каждый следующий триплет определяет актера дальше. НПО = неправительственная организация, NGOHLHRCR (NGO HLH RCR) = неправительственная организация / здравоохранение / Красный Крест.
- Тон события — это показатель от -100 (крайне отрицательный) до +100 (крайне положительный). Значения между -5 и 5 являются наиболее распространенными.
- Шкала Голдштейна события — это показатель от -10 до +10, который отражает вероятное влияние этого типа события на стабильность страны.
Полная кодовая книга CAMEO со всеми кодами глаголов событий и типов актеров находится здесь .
Создать учетную запись для BigQuery
Если вы хотите использовать BigQuery для доступа к GDELT из приложения, вы будете использовать облачную платформу Google. Я расскажу вам, как создать учетную запись BigQuery, но ваша ситуация, вероятно, несколько отличается от того, что я описываю здесь. Google время от времени меняет свой пользовательский интерфейс.
Вам понадобится аккаунт Google. Если у вас его нет, вы должны его создать . Затем введите консоль, где вам будет предложено создать проект, если у вас его еще нет.
Проверьте консоль. В левом верхнем углу вы увидите меню гамбургера (значок с тремя горизонтальными линиями), которое дает доступ ко всем частям платформы.
Используя ваш проект, перейдите в библиотеку API и включите API BigQuery.
Затем создайте служебную учетную запись для своего проекта и назначьте ей учетную запись BigQuery User. Это позволяет ему выполнять запросы. Вы можете изменить разрешения позже на вкладке IAM. В качестве «участника» выберите идентификатор своей учетной записи.
Ваша служебная учетная запись позволяет вам создать ключ (через раскрывающееся меню), файл JSON, который вы загружаете и сохраняете в безопасном месте. Вам нужен этот ключ в вашем коде PHP.
Наконец, вам нужно настроить платежную учетную запись для вашего проекта. Это может вас удивить, поскольку доступ к GDELT бесплатен до 1 терабайта в месяц, но это необходимо, даже если Google не будет взимать с вас плату за что-либо.
Google предоставляет бесплатный пробный аккаунт на 3 месяца. Вы можете использовать его для экспериментов. Если вы действительно начнете использовать приложение, вам нужно будет предоставить данные кредитной карты или банковского счета.
Доступ к данным с помощью PHP
Ранее вы обращались к BigQuery через PHP-клиент API Google, но теперь предпочтительной библиотекой является клиентская библиотека Google Cloud для PHP .
Мы можем установить его с помощью Composer :
composer require google/cloud
Сам код на удивление прост. Замените путь к ключу проекта на тот, который вы скачали с консоли Google Cloud.
use Google\Cloud\BigQuery\BigQueryClient; // setup Composer autoloading require_once __DIR__ . '/vendor/autoload.php'; $sql = "SELECT theme, COUNT(*) as count FROM ( select SPLIT(V2Themes,';') theme from [gdelt-bq:gdeltv2.gkg] where DATE>20150302000000 and DATE < 20150304000000 and AllNames like '%Netanyahu%' and TranslationInfo like '%srclc:heb%' ) group by theme ORDER BY 2 DESC LIMIT 300 "; $bigQuery = new BigQueryClient([ 'keyFilePath' => __DIR__ . '/path/to/your/google/cloud/account/key.json', ]); // Run a query and inspect the results. $queryResults = $bigQuery->runQuery($sql); foreach ($queryResults->rows() as $row) { print_r($row); }
Изучение наборов данных
Мы можем даже запросить метаданные. Начнем с перечисления наборов данных проекта. Набор данных — это коллекция таблиц.
$bigQuery = new BigQueryClient([ 'keyFilePath' => '/path/to/your/google/cloud/account/key.json', 'projectId' => 'gdelt-bq' ]); /** @var Dataset[] $datasets */ $datasets = $bigQuery->datasets(); $names = array(); foreach ($datasets as $dataset) { $names[] = $dataset->id(); } print_r($names);
Обратите внимание, что мы должны указывать идентификатор проекта ( gdelt-bq ) в конфигурации клиента при запросе метаданных.
Это результат нашего кода:
Array ( [0] => extra [1] => full [2] => gdeltv2 [3] => gdeltv2_ngrams [4] => hathitrustbooks [5] => internetarchivebooks [6] => sample_views )
Маленькая история
Данные о политических событиях хранились десятилетиями. Важной вехой в этой области стало внедрение программы Интегрированной системы раннего оповещения о кризисах ( ICEWS ) в 2010 году.
Интересным и порой забавным обзором сбора данных о глобальных событиях, написанным Филиппом А. Шродтом, является « Автоматизированное производство больших объемов данных о политических событиях, происходящих практически в реальном времени» .
Новости постоянно собираются из самых разных источников, таких как AfricaNews, Agence France Presse, Associated Press Online, BBC Monitoring, Christian Science Monitor, United Press International и Washington Post. Данные собраны из нескольких источников новостей. Раньше они кодировались вручную, но теперь это делается с помощью различных методов обработки естественного языка (NLP).
GDELT 1 проанализировал новости с помощью библиотеки C ++ под названием TABARI и передал закодированные данные в базу данных. TABARI анализирует статьи с использованием поверхностного анализатора на основе шаблонов и выполняет распознавание именованных объектов. В настоящее время он охватывает период с 1979 года по сегодняшний день.
Раннее представление GDELT Leetaru и Schrodt, описывающее источники новостей и методы кодирования, можно прочитать здесь .
В феврале 2015 года был выпущен GDELT 2.0. TABARI был заменен библиотекой PETRARCH (написанной на Python). Теперь используется синтаксический анализатор Stanford CoreNLP, а статьи переводятся. Если вы хотите узнать больше о причинах этого изменения, вы можете прочитать очень просвещающие слайды Филиппа А. Шредта об этом. GDELT 2 также расширяет данные о событиях графом глобальных знаний .
В сентябре 2015 года данные из интернет-архива и Hathi Trust были включены в базу данных GDELT BigQuery.
Наборы данных GDELT
Обзор наборов данных находится на этой странице веб-сайта проекта GDELT .
Наборы данных сгруппированы следующим образом:
- Исходный набор данных GDELT 1: полный . Посмотрите в этом блоге пример Калева Летару.
- Наборы данных GDELT 2: gdeltv2 и gdeltv2_ngrams
- Набор данных Hathi Trust Books: hathitrustbooks
- Интернет архив данных: интернетархивбуки . На этой странице показан пример запроса к данным книги из интернет-архива.
Документация о таблицах и полях наборов данных GDELT (1 и 2) доступна в разделе документации на веб-сайте проекта GDELT .
Документацию о таблицах и полях интернет-архива и архива книги HathiTrust можно найти на странице интернет-архива + HathiTrust .
Это бесплатно?
Более 1 ТБ Google взимает 5 долларов США за ТБ.
Когда я услышал, что первый обработанный терабайт данных в месяц бесплатен, я подумал: 1 ТБ данных должно хватить кому угодно! Я ввел данные собственного банковского счета и разместил пару простых запросов.
Через неделю, когда начался новый месяц, я получил сообщение из Google Cloud:
«Мы скоро автоматически выставим вам счет»
Я был обвинен за € 10,96! Как это случилось? Это когда я посмотрел немного ближе к ценам.
Страница Google Cloud о ценах на самом деле довольно понятна. В контексте запросов к GDELT вы не платите за загрузку, копирование и экспорт данных. Вы также не платите за операции с метаданными (например, перечисление таблиц). Вы просто платите за запросы. Точнее:
Цена запроса относится к стоимости выполнения ваших команд SQL и пользовательских функций. BigQuery взимает плату за запросы, используя одну метрику: количество обработанных байтов.
Это не размер запроса и не размер результирующего набора (как вы могли бы предположить), а размер данных, перекачиваемых BigQuery при его обработке. Глядя на свою панель для выставления счетов, я увидел, что Google снял с меня плату
BigQuery Analysis: 3541.117 Gibibytes
BigQuery обработал 3541 Gibibytes для моих запросов! Разделив на 1024, он конвертируется в 3 45812207 терабайт (тибибайт может быть более точным ). Отбросив первый бесплатный туберкулез и переведя в евро (курс на тот момент = 0,892), я получил 10,96 €. Я подсчитал, что стоимость одного примера запроса GDELT, упомянутого выше (запроса с подзапросом), составляет внушительные 2,20 доллара!
Надеюсь, я вас не напугала. Можно создавать полезные запросы, которые не занимают так много памяти, но вам нужно кешировать свои результаты и быть осторожным при ручной обработке вашего запроса. BigQuery помогает нам в этом отношении. В ответ на запрос, рядом с результирующими строками, он также предоставляет нам информацию «totalBytesProcessed». Из этого можно рассчитать стоимость в долларах:
$results = $bigQuery->runQuery($sql); $info = $results->info(); $tb = ($info['totalBytesProcessed'] / Constants::BYTES_PER_TEBIBYTE); // 1099511627776 $cost = $tb * Constants::DOLLARS_PER_TEBIBYTE; // 5
Запросы в BigQuery
Нижняя часть страницы о выставлении счетов очень информативна. Он учит нас, что BigQuery загружает полный столбец данных каждый раз, когда это необходимо, но только одну запись. Так, например, я побежал:
SELECT Actor1Name FROM [gdelt-bq:gdeltv2.events] WHERE GLOBALEVENTID = 526870433
В реляционной базе данных это будет очень быстрый запрос, использующий индекс GLOBALEVENTID для поиска и возврата одной записи. В BigQuery он загружает полный столбец данных объемом 3,02 ГБ и запускается (!) За несколько секунд — BigQuery не использует индексы. Всякий раз, когда ему нужен столбец, он читает полный столбец. Когда столбец действительно большой, он разделяется на несколько машин, и эти машины будут работать параллельно для решения вашего запроса. BigQuery не был оптимизирован для небольших таблиц, но он может выполнять запросы к петабайтам данных за считанные секунды.
Чтобы узнать подробности об архитектуре BigQuery, вы можете прочитать эту статью или эту книгу в Google BigQuery Analytics .
Визуализация
Когда я писал эту статью, я думал о дополнительной ценности, которую может иметь сценарийный подход к GDELT. Я думаю, что это тот факт, что вы имеете полный контроль над запросом и визуализацией! Будучи не слишком изобретательным, я решил создать график всех боев, о которых сообщалось за последние два дня, просто в качестве примера.
GDELT помогает вам создавать модные визуализации , но для них нет API. Тем не менее, веб-сайт показывает нам, с какими инструментами они были сделаны. Мы можем использовать те же инструменты для создания графиков сами.
Я выбрал карту тепла, потому что она лучше всего отражала мои намерения. В разделе «Вывод» я обнаружил, что он использует heatmap.js для создания наложения на Google Maps. Я скопировал код из heatmap.js в свой проект и настроил его под свои нужды.
Для использования Google Maps требуется ключ API. Вы можете получить один здесь .
Я поместил код для примера тепловой карты боев GDELT на Github .

Запрос выбирает географические координаты всех событий «бой» (серия из 190 кодов событий), добавленных между теперь и два дня назад, и группирует их по географическим координатам. Он принимает только корневые события, пытаясь отфильтровать релевантное от несущественного. Я также добавил SOURCEURL в мой выбор. Я использовал это для создания кликабельных маркеров на карте, показывающих при более глубоком уровне масштабирования, которые позволяют вам посетить исходную статью о событии.
SELECT MAX(ActionGeo_Lat) as lat, MAX(ActionGeo_Long) as lng, COUNT(*) as count, MAX(SOURCEURL) as source, GROUP_CONCAT(UNIQUE(EventCode)) as codes FROM [gdelt-bq:gdeltv2.events] WHERE SqlDate > {$from} AND SqlDate < {$to} AND EventCode in ('190', '191','192', '193', '194', '195', '1951', '1952', '196') AND IsRootEvent = 1 AND ActionGeo_Lat IS NOT NULL AND ActionGeo_Long IS NOT NULL GROUP BY ActionGeo_Lat, ActionGeo_Long
Я обнаружил, что многие события по-прежнему не имеют отношения к тому, что я имел в виду, поэтому, чтобы сделать это правильно, мне пришлось бы еще больше подправить свой запрос. Кроме того, многие статьи обрабатывали одно и то же событие, и я выбрал только одну из них для отображения на карте.
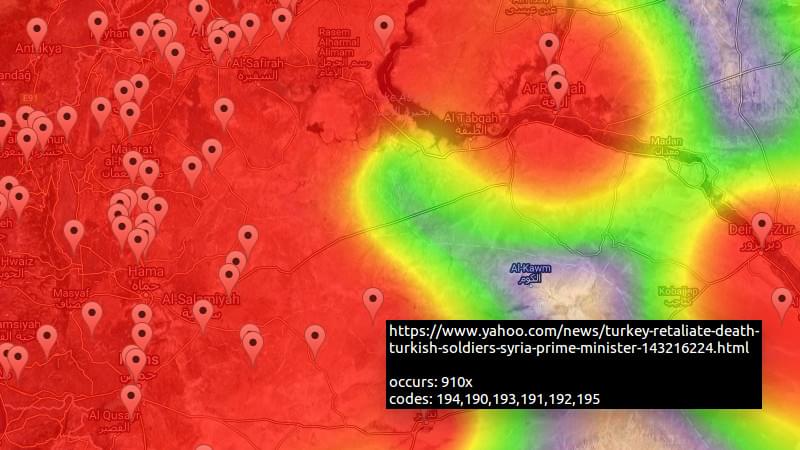
Что касается затрат? Этот пример запроса занимает всего несколько гигабайт для обработки. Поскольку он кэшируется, его нужно выполнять не чаще одного раза в день. Таким образом, он остается значительно ниже предела в 1 ТБ и не стоит мне ни копейки!
Слово предостережения
Будьте осторожны с наивным использованием данных, предоставляемых GDELT.
- Тот факт, что количество событий определенного явления увеличивается с годами, не означает, что это явление увеличивается. Это может означать, что стало доступно больше данных или что больше источников реагируют на это явление.
- Данные не проверены, ни один человек не выбрал соответствующие части из несущественных.
- Во многих случаях актеры неизвестны.
Вывод
GDELT, безусловно, предоставляет огромное количество информации. В этой статье я только поверхностно рассмотрел все идеи, проекты и инструменты, которые в нем содержатся. Веб-сайт GDELT предоставляет несколько способов создания визуализаций без необходимости кодирования.
Если вам нравится кодирование или вы считаете, что доступных инструментов недостаточно для ваших нужд, вы можете следовать приведенным выше советам. Поскольку GDELT доступен через BigQuery, легко извлечь нужную информацию с помощью простого SQL. Будьте осторожны, хотя! Использование BigQuery стоит денег, если вы не подготовили свои запросы хорошо и не использовали кеширование.
На этот раз я просто создал простую визуализацию запроса, зависящего от времени. На практике исследователь должен сделать гораздо больше настроек, чтобы получить абсолютно правильные результаты и отобразить их осмысленно.
Если эта статья вдохновила вас на создание нового PHP-приложения, поделитесь им с нами в разделе комментариев ниже. Мы хотели бы знать, как GDELT используется во всем мире.
Весь код из этого поста можно найти в соответствующем репозитории Github .