Недавно я искал хостинг для разрабатываемого приложения. Я решил исследовать Orchestra.io , так как ожидал, что он будет получать скачки трафика в определенных точках в течение каждого года, и мне нужно было соответственно масштабировать приложение. В процессе просмотра документации для Orchestra.io я обнаружил, что она не позволяет загружать файлы . Вместо этого рекомендуется использовать Amazon S3 для файлового хостинга.
Если вы не знакомы с ним, S3 — это веб-сервис онлайн-хранилища, который является частью Amazon Web Services (AWS). Он обеспечивает доступ к довольно дешевому хранилищу через различные интерфейсы веб-служб. В этой статье будет показано, как зарегистрировать учетную запись Amazon S3 и использовать пакет PEAR’s Services_Amazon_S3
Регистрация на Amazon S3
Первым шагом в этом процессе является регистрация собственной учетной записи S3 по адресу aws.amazon.com/s3 . Оказавшись там, найдите и нажмите кнопку «Зарегистрироваться сейчас» справа, а затем просто следуйте предоставленным инструкциям.
Вскоре после этого вы получите электронное письмо по указанному вами адресу с дальнейшими инструкциями. Если вы этого не сделаете или потеряете свою копию, просто перейдите на консоль управления AWS по адресу console.aws.amazon.com/s3 . Эта область сайта предоставит вам ваши идентификаторы доступа, учетные данные, необходимые для того, чтобы вы могли записывать данные в S3. Если вы использовали API веб-службы, для которого требовался токен доступа, эти идентификаторы доступа служат той же цели. После того, как вы открыли страницу консоли, посмотрите в верхнем правом углу меню с вашим именем. Нажмите на него, чтобы развернуть его, и выберите опцию «Учетные данные безопасности».

Перейдя на страницу «Учетные данные безопасности», прокрутите вниз и найдите раздел «Учетные данные для доступа». Здесь вы увидите свой идентификатор ключа доступа. Нажмите на ссылку «Показать» рядом с ней, чтобы отобразить ваш секретный ключ доступа. Эти две части информации — все, что нужно для доступа к вашей учетной записи S3. Будьте уверены, чтобы сохранить их в безопасности.
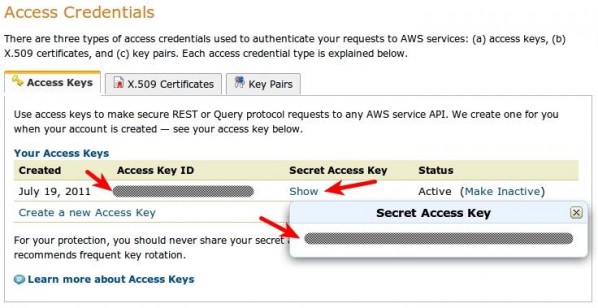
Две вкладки рядом с вкладками «Ключи доступа» относятся к сервисам, отличным от S3. В частности, сертификаты X.509 используются для создания безопасных запросов при использовании API-интерфейсов AWS SOAP (за исключением тех, что для S3 и Mechanical Turk — вместо них используются ключи доступа), а пары ключей используются для Amazon CloudFront и EC2.
Теперь, когда у вас есть идентификаторы доступа, вернитесь на страницу консоли. Слева вы найдете список ведер, который будет пустым. Bucket — это просто именованный контейнер для набора файлов. Если вы используете S3 на нескольких сайтах, этот механизм может помочь вам сохранить ваши файлы для каждого сайта отдельными и организованными. Вам нужно будет создать ведро, прежде чем продолжить.
Установка Services_Amazon_S3
Затем вам нужно установить пакет PEAR Services_Amazon_S3 Возможно, но маловероятно, что на вашем сервере он уже есть, если у вас нет прав администратора. Таким образом, вам, вероятно, понадобится локальная копия PEAR, подходящая для среды общего хостинга.
Самый простой способ сделать это — создать эту установку на компьютере, для которого у вас есть права администратора и существующую установку PEAR, а затем скопировать эту установку в нужную среду хостинга. В системе * NIX это может быть достигнуто путем запуска следующих команд из терминала:
root @ foobox: ~ # pear config-create `pwd` .pearrc root @ foobox: ~ # pear -c .pearrc install -o Services_Amazon_S3
Это создаст каталог pear В этом каталоге находится каталог php, содержащий фактический код PHP для установленного пакета PEAR и его зависимости. Это единственный каталог, в котором вам нужно использовать код S3 в вашем собственном коде; Вы можете скопировать его или его содержимое как есть в любой каталог вашего проекта, зарезервированный для сторонних зависимостей.
Чтобы фактически использовать код, вам нужно добавить каталог, содержащий подкаталог Servicesinclude_path Если /path/to/dirServicesinclude_path
<?php
set_include_path(get_include_path() . PATH_SEPARATOR . "/path/to/dir");
В оставшейся части этой статьи предполагается, что у вас есть подходящий автозагрузчик для загрузки классов из этого каталога по мере их использования.
Использование Services_Amazon_S3
Существует два способа использования Services_Amazon_S3 Хотя код, использующий потоки, может быть более кратким, он также может быть подвержен ошибкам в ядре PHP, связанным с контекстами потоков. Примером этого является ошибка, исправленная в PHP 5.3.4, когда функция copy()$context Рекомендуется проверить журнал изменений PHP относительно своей версии PHP, прежде чем решить, какой метод использовать.
Использование S3 Stream Wrapper
Давайте сначала посмотрим на метод потоков. В дополнение к идентификатору ключа доступа и секретному ключу доступа, S3 нуждается в двух частях информации о файле: строка, определяющая, кто имеет доступ к файлу (который по умолчанию является private При использовании обертки потоков вся эта информация передается с использованием потоковых контекстов. Давайте посмотрим, как может выглядеть обработка загрузки файла:
<?php
if (is_uploaded_file($_FILES["fieldname"]["tmp_name"])) {
Services_Amazon_S3_Stream::register();
$context = stream_context_create(array(
"s3" => array(
"access_key_id" => "access_key_id",
"secret_access_key" => "secret_access_key",
"content_type" => $_FILES["fieldname"]["type"],
"acl" => "public-read")));
copy($_FILES["fieldname"]["tmp_name"],
"s3://bucketname/" . $_FILES["fieldname"]["name"],
$context);
}
Этот код обрабатывает загрузку файла, отправленную с использованием формы HTML. Эта форма содержит поле файла с именем fieldname Опция контекста content_type$_FILES Параметр контекста acl В этом случае, поскольку я использовал S3 для размещения общедоступных статических файлов, я использовал простой public-readACL, который позволяет любому просматривать его. Контроль доступа S3 обеспечивает гораздо более детальные разрешения; Мой был очень распространенным, но простым вариантом использования.
После создания контекста потока файл можно загрузить на S3 с помощью функции copy() Источником является путь, предоставленный $_FILES после завершения запроса эта копия будет удалена. Место назначения ссылается на оболочку s3bucketname$_FILES
Обратите внимание, что вместо простого имени можно указать относительный путь. Если строгий режим отключен (что по умолчанию), S3 просто примет путь и будет использовать соответствующую структуру каталогов в консоли AWS. В этом случае каталоги не нужно создавать заранее.
Еще одно обстоятельство моего конкретного случая использования состояло в том, что ранее на S3 мог быть загружен файл, который соответствовал конкретной записи в базе данных. Несколько расширений файлов были поддержаны и поддерживаются, когда файлы были загружены на S3. Таким образом, имя файла для записи не всегда будет одинаковым, и мне нужно будет удалить любой существующий файл, соответствующий записи, перед загрузкой нового.
Если бы я сохранил имя любого существующего файла для записи, это было бы относительно тривиально. Иначе, это было бы немного неуклюже из-за того, как потоковая обертка использует API; Мне пришлось перебирать файлы в каталоге, чтобы найти файл, соответствующий заданному префиксу, который указывает, что он соответствует записи. Вот как справиться с обеими ситуациями:
<?php
// If the existing filename is known...
unlink("s3://bucketname/path/to/file");
// If the existing filename is not known...
$it = new DirectoryIterator("s3://bucketname/path/to/dir");
foreach ($it as $entry) {
$filename = $entry->getFilename();
if (strpos($filename, $prefix) === 0) {
unlink("s3://bucketname/path/to/dir/$filename");
break;
}
}
Использование S3 API
Та же самая загрузка файла с использованием S3 API будет выглядеть так:
<?php
$s3 = Services_Amazon_S3::getAccount("access_key_id", "secret_access_key");
$bucket = $s3->getBucket("bucketname");
$object = $bucket->getObject($_FILES["fieldname"]["name"]);
$object->acl = "public-read";
$object->contentType = $_FILES["fieldname"]["type"];
$object->data = file_get_contents($_FILES["fieldname"]["tmp_name"]);
$object->save();
Вся та же информация предоставляется в коде, это просто делается с помощью вызовов методов и присвоений значений общедоступным свойствам вместо потоковых контекстов и URL-адресов. Опять же, в этом примере вместо имени можно указать относительный путь внутри сегмента. Как вы можете видеть, использование API для загрузки файлов требует немного большего скачка в смысле извлечения объектов и ручного чтения данных файла перед явным сохранением объекта на S3.
Тем не менее, API делает удаление существующего файла с заданным префиксом немного проще, чем с помощью потоковой оболочки s3 После получения объекта, представляющего корзину, содержащую файл, вы можете просто сделать это:
<?php
foreach ($bucket->getObjects($prefix) as $object) {
$object->delete();
}
Резюме
Пакет Services_Amazon_S3 Он обрабатывает все низкоуровневые детали взаимодействия с S3 для вас, оставляя вам возможность указать, с какими данными вы хотите работать и какую операцию вы хотите выполнить.
Какой метод вы выбираете, потоковый или API, действительно зависит от того, как вы используете S3 и каковы ваши личные предпочтения. Как показано в этой статье, код может быть более или менее подробным с любым методом в зависимости от того, что вы делаете.
Надеемся, что эта статья немного ознакомила вас с возможностями S3 как сервиса. Я рекомендую вам прочитать больше о S3 , изучить примеры и документацию по API для Services_Amazon_S3
Изображение с помощью Marcin Balcerzak / Shutterstock