Многопоточное приложение состоит из двух или более частей, которые могут работать параллельно. Это позволяет приложению лучше использовать ядра внутри процессора устройства. Это позволяет выполнять задачи быстрее и обеспечивает более плавный и отзывчивый опыт для пользователя.
Кодирование для параллелизма в Java может быть болезненным, но благодаря RxJava теперь это сделать намного проще. С RxJava вам просто нужно объявить поток, в котором вы хотите, чтобы задача была выполнена (декларативно) вместо создания и управления потоками (обязательно).
RxJava использует Schedulers вместе с операторами параллельной subscribeOn() на subscribeOn() и observeOn() для достижения этой цели. В этом учебном пособии вы узнаете о Schedulers , операторе subscribeOn() операционном observeOn() , а также о том, как использовать оператор flatMap() для достижения параллелизма. Но сначала давайте начнем с Schedulers в RxJava .
Предпосылки
Чтобы следовать этому уроку, вы должны быть знакомы с:
Ознакомьтесь с другими нашими статьями, чтобы освоить основы RxJava и лямбда-выражений.
-
 Android SDKНачните с RxJava 2 для Android
Android SDKНачните с RxJava 2 для Android -
Android SDKФункциональные приложения для Android в Котлине: Lambdas, Null Safety и многое другое


Планировщики в RxJava 2
Schedulers в RxJava используются для выполнения единицы работы над потоком. Scheduler предоставляет абстракцию для механизма потоков Android и Java. Если вы хотите запустить задачу и используете Scheduler для ее выполнения, Scheduler переходит в свой пул потоков (набор потоков, готовых к использованию), а затем запускает задачу в доступном потоке.
Вы также можете указать, что задача должна выполняться в одном конкретном потоке. (Существует два оператора, subscribeOn() и observeOn() , которые можно использовать для указания, в каком потоке из пула потоков Scheduler должна быть выполнена задача.)
Как вы знаете, в Android длительные процессы или задачи с интенсивным использованием процессора не должны выполняться в главном потоке. Если подписка Observer на Observable проводится в основном потоке, любой связанный оператор также будет работать в основном потоке. В случае длительной задачи (например, выполнение сетевого запроса) или задачи с интенсивным использованием ЦП (например, преобразование изображения) это будет блокировать пользовательский интерфейс до завершения задачи, что приведет к ужасному диалоговому окну ANR (приложение не отвечает) и приложение вылетает. Вместо этого эти операторы могут быть переключены на другой поток с observeOn() оператора observeOn() .
В следующем разделе мы собираемся исследовать различные виды Schedulers и их использование.
Типы планировщиков
Вот некоторые из типов Schedulers доступных в RxJava и RxAndroid чтобы указать тип потока для выполнения задач.
-
Schedulers.immediate(): возвращаетSchedulerкоторый мгновенно выполняет работу в текущем потоке. Имейте в виду, что это заблокирует текущий поток, поэтому его следует использовать с осторожностью. -
Schedulers.trampoline(): планирование задач в текущем потоке. Эти задачи не выполняются сразу, а выполняются после того, как поток завершил свои текущие задачи. Это отличается отSchedulers.immediate()потому что вместо немедленного выполнения задачи он ожидает завершения текущих задач. -
Schedulers.newThread(): запускает новый поток и возвращаетSchedulerдля выполнения задачи в новом потоке для каждогоObserver. Вы должны быть осторожны при использовании этого, потому что новый поток не используется повторно, а вместо этого уничтожается. -
Schedulers.computation(): это дает намSchedulerкоторый предназначен для вычислительно-интенсивной работы, такой как преобразование изображений, сложные вычисления и т. Д. Эта операция полностью использует ядра ЦП. ЭтотSchedulerиспользует фиксированный размер пула потоков, который зависит от ядер ЦП для оптимального использования. Вы должны быть осторожны, чтобы не создавать больше потоков, чем доступные ядра ЦП, поскольку это может снизить производительность. -
Schedulers.io(): создает и возвращаетSchedulerпредназначенный для работы, связанной с вводом-выводом, такой как выполнение асинхронных сетевых вызовов или чтение и запись в базу данных. Эти задачи не загружают процессор или используютSchedulers.computation(). -
Schedulers.single(): создает и возвращаетSchedulerи выполняет несколько задач последовательно в одном потоке. -
Schedulers.from(Executor executor): это создастSchedulerкоторый будет выполнять задачу или единицу работы с даннымExecutor. -
AndroidSchedulers.mainThread(): это создастSchedulerкоторый выполняет задачу в главном потоке приложения Android. Этот тип планировщика предоставляется библиотекойRxAndroid.
Оператор subscribeOn()
Используя оператор одновременной subscribeOn() , вы указываете, что Scheduler должен выполнять операцию в Observable восходящем потоке. Затем он отправит значения Observers используя тот же поток. Теперь давайте посмотрим на практический пример:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
import android.os.Bundle;
import android.support.v7.app.AppCompatActivity;
import android.util.Log;
import io.reactivex.Observable;
import io.reactivex.ObservableOnSubscribe;
import io.reactivex.disposables.Disposable;
import io.reactivex.schedulers.Schedulers;
public class MainActivity extends AppCompatActivity {
private static final String[] STATES = { «Lagos», «Abuja», «Abia»,
«Edo», «Enugu», «Niger», «Anambra»};
private Disposable mDisposable = null;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Observable<String> observable = Observable.create(dataSource())
.subscribeOn(Schedulers.newThread())
.doOnComplete(() -> Log.d(«MainActivity», «Complete»));
mDisposable = observable.subscribe(s -> {
Log.d(«MainActivity», «received » + s + » on thread » + Thread.currentThread().getName());
});
}
private ObservableOnSubscribe<String> dataSource() {
return(emitter -> {
for(String state : STATES) {
emitter.onNext(state);
Log.d(«MainActivity», «emitting » + state + » on thread » + Thread.currentThread().getName());
Thread.sleep(600);
}
emitter.onComplete();
});
}
@Override
protected void onDestroy() {
if (mDisposable != null && !mDisposable.isDisposed()) {
mDisposable.dispose();
}
super.onDestroy();
}
}
|
В приведенном выше коде у нас есть статический ArrayList который содержит некоторые штаты в Нигерии. У нас также есть поле типа Disposable . Мы получаем экземпляр Disposable , вызывая Observable.subscribe() , и будем использовать его позже, когда вызовем метод dispose() для освобождения любых использованных ресурсов. Это помогает предотвратить утечки памяти. Наш dataSource() (который может возвращать данные из удаленного или локального источника базы данных) вернет ObservableOnSubscribe<T> : это необходимо для того, чтобы мы позже создали собственный Observable используя метод Observable.create() .
Внутри dataSource() мы перебираем массив, отправляя каждый элемент Observers , вызывая emitter.onNext() . После выдачи каждого значения мы спим потоком, чтобы смоделировать выполняемую интенсивную работу. Наконец, мы вызываем метод onComplete() чтобы сообщить Observers что мы завершили передачу значений, и они больше не должны ожидать.
Теперь наш dataSource() не должен выполняться в основном потоке пользовательского интерфейса. Но как это указано? В приведенном выше примере мы предоставили Schedulers.newThread() в качестве аргумента для subscribeOn() . Это означает, что dataSource() будет запущена в новом потоке. Также обратите внимание, что в приведенном выше примере у нас есть только один Observer . Если бы у нас было несколько Observers , каждый из них получал бы свой собственный поток.
Чтобы мы могли видеть, как это работает, наш Observer распечатывает значения, которые он получает в своем onNext() из Observable .
Когда мы запустим это и просмотрим наш logcat в Android Studio, вы увидите, что dataSource() метода dataSource() в Observer произошла в том же потоке — RxNewThreadScheduler-1 — в котором Observer их получил.
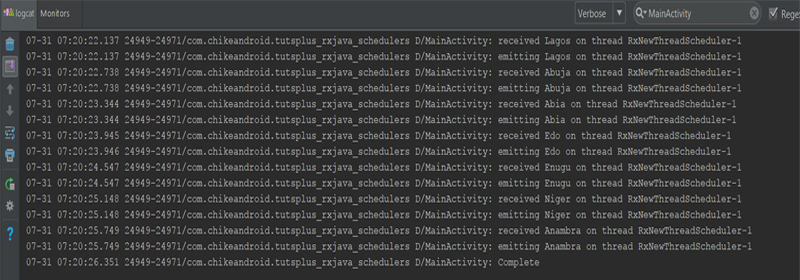
Если вы не укажете метод .subscribeOn() после метода Observable.create() , он будет выполнен в текущем потоке, который в нашем случае является основным, блокируя таким образом пользовательский интерфейс приложения.
Есть несколько важных деталей, о которых вы должны знать, касающихся оператора subscribeOn() . У вас должен быть только один subscribeOn() в цепочке Observable ; добавление еще одного в любом месте цепочки не будет иметь никакого эффекта вообще. Рекомендуемое место для размещения этого оператора максимально близко к источнику для ясности. Другими словами, поместите его первым в цепочке операторов.
|
1
2
3
4
5
6
|
Observable.create(dataSource())
.subscribeOn(Schedulers.computation()) // this has effect
.subscribeOn(Schedulers.io()) // has no effect
.doOnNext(s -> {
saveToCache(s);
})
|
Оператор observeOn()
Как мы видели, оператор параллелизма subscribeOn() будет Observable какой Scheduler использовать, чтобы продвигать выбросы по цепочке Observers к Observers .
С другой стороны, observeOn() оператора одновременного observeOn() состоит в том, чтобы переключать последующие выбросы в другой поток или Scheduler . Мы используем этот оператор, чтобы контролировать, какой поток нижестоящие потребители будут получать выбросы. Давайте посмотрим на практический пример.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
import android.os.Bundle;
import android.support.v7.app.AppCompatActivity;
import android.util.Log;
import android.widget.TextView;
import io.reactivex.Observable;
import io.reactivex.ObservableOnSubscribe;
import io.reactivex.android.schedulers.AndroidSchedulers;
import io.reactivex.disposables.Disposable;
import io.reactivex.schedulers.Schedulers;
public class ObserveOnActivity extends AppCompatActivity {
private Disposable mDisposable = null;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView textView = (TextView) findViewById(R.id.tv_main);
Observable<String> observable = Observable.create(dataSource())
.subscribeOn(Schedulers.newThread())
.observeOn(AndroidSchedulers.mainThread())
.doOnComplete(() -> Log.d(«ObserveOnActivity», «Complete»));
mDisposable = observable.subscribe(s -> {
Log.d(«ObserveOnActivity», «received » + s + » on thread » + Thread.currentThread().getName());
textView.setText(s);
});
}
private ObservableOnSubscribe<String> dataSource() {
return(emitter -> {
Thread.sleep(800);
emitter.onNext(«Value»);
Log.d(«ObserveOnActivity», «dataSource() on thread » + Thread.currentThread().getName());
emitter.onComplete();
});
}
// …
}
|
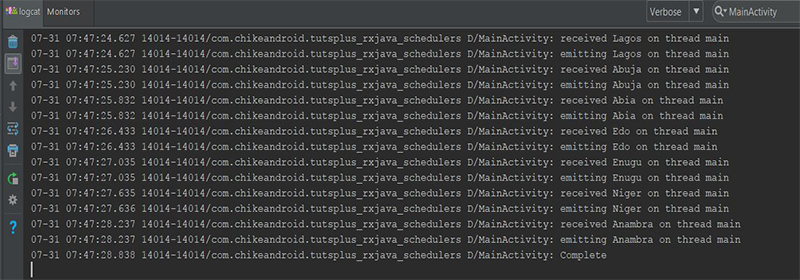
В приведенном выше коде мы использовали оператор observeOn() а затем передали ему AndroidSchedulers.mainThread() . Что мы сделали, так это переключили поток с Schedulers.newThread() на основной поток Android. Это необходимо, потому что мы хотим обновить виджет TextView и можем это делать только из основного потока пользовательского интерфейса. Обратите внимание, что если вы не переключитесь на основной поток при попытке обновить виджет TextView , приложение завершится CalledFromWrongThreadException и CalledFromWrongThreadException .
В отличие от оператора subscribeOn() оператор observeOn() может применяться несколько раз в цепочке операторов, тем самым изменяя Scheduler более одного раза.
|
1
2
3
4
5
6
7
8
9
|
Observable<String> observable = Observable.create(dataSource())
.subscribeOn(Schedulers.newThread())
.observeOn(Schedulers.io())
.doOnNext(s -> {
saveToCache(s);
Log.d(«ObserveOnActivity», «doOnNext() on thread » + Thread.currentThread().getName());
})
.observeOn(AndroidSchedulers.mainThread())
.doOnComplete(() -> Log.d(«ObserveOnActivity», «Complete»));
|
Этот код имеет два оператора observeOn() . Первый использует Schedulers.io() , что означает, что метод saveToCache() будет выполняться в потоке Schedulers.io() . После этого он переключается на AndroidSchedulers.mainThread() где Observers будут получать выбросы от восходящего потока.

Параллелизм с оператором flatMap ()
Оператор flatMap() — это еще один очень мощный и важный оператор, который можно использовать для достижения параллелизма. Определение в соответствии с официальной документацией выглядит следующим образом:
Преобразуйте предметы, испускаемые Обсерваторией, в Наблюдаемые, затем сведите выбросы из них в единую Наблюдаемую.
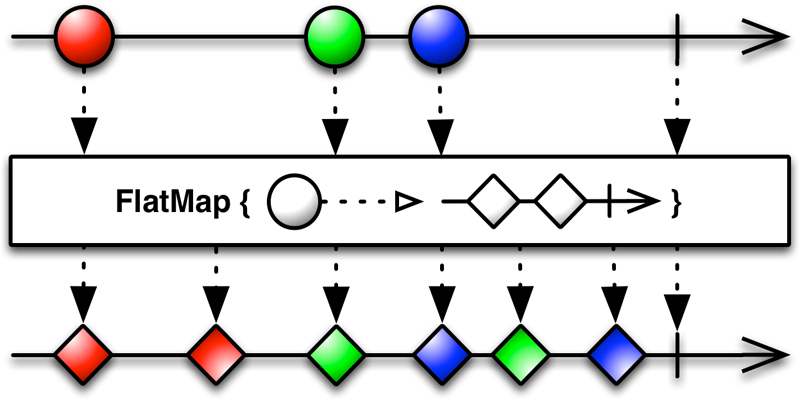
Давайте посмотрим на практический пример, который использует этот оператор:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
//…
@Override
protected void onCreate(Bundle savedInstanceState) {
// …
final String[] states = {«Lagos», «Abuja», «Imo», «Enugu»};
Observable<String> statesObservable = Observable.fromArray(states);
statesObservable.flatMap(
s -> Observable.create(getPopulation(s))
).subscribe(pair -> Log.d(«MainActivity», pair.first + » population is » + pair.second));
}
private ObservableOnSubscribe<Pair> getPopulation(String state) {
return(emitter -> {
Random r = new Random();
Log.d(«MainActivity», «getPopulation() for » + state + » called on » + Thread.currentThread().getName());
emitter.onNext(new Pair(state, r.nextInt(300000 — 10000) + 10000));
emitter.onComplete();
});
}
}
|
В Android Studio logcat будет напечатано следующее:
|
1
2
3
4
5
6
7
8
|
getPopulation() for Lagos called on main
Lagos population is 80362
getPopulation() for Abuja called on main
Abuja population is 132559
getPopulation() for Imo called on main
Imo population is 34106
getPopulation() for Enugu called on main
Enugu population is 220301
|
Из приведенного выше результата видно, что полученные результаты были в том же порядке, что и в массиве. Кроме того, метод getPopulation() для каждого состояния обрабатывался в одном и том же потоке — основном потоке. Это замедляет вывод, потому что они обрабатывались последовательно в главном потоке.
Теперь, чтобы мы достигли параллелизма с этим оператором, мы хотим, чтобы метод getPopulation() для каждого состояния (эмиссии из statesObservable ) обрабатывался в разных потоках. Это приведет к более быстрой обработке. Для этого мы будем использовать оператор flatMap() , поскольку он создает новую Observable для каждого излучения. Затем мы применяем к нему один оператор параллелизма subscribeOn() , передавая ему Scheduler .
|
1
2
3
4
|
statesObservable.flatMap(
s -> Observable.create(getPopulation(s))
.subscribeOn(Schedulers.io())
).subscribe(pair -> Log.d(«MainActivity», pair.first + » population is » + pair.second));
|
Поскольку каждое излучение создает Observable , flatMap() оператора flatMap() состоит в том, чтобы объединить их вместе и затем отправить их в виде единого потока.
|
1
2
3
4
5
6
7
8
|
getPopulation() for Lagos called on RxCachedThreadScheduler-1
Lagos population is 143965
getPopulation() for Abuja called on RxCachedThreadScheduler-2
getPopulation() for Enugu called on RxCachedThreadScheduler-4
Abuja population is 158363
Enugu population is 271420
getPopulation() for Imo called on RxCachedThreadScheduler-3
Imo population is 81564
|
В приведенном выше результате мы можем наблюдать, что метод getPopulation() каждого состояния обрабатывался в разных потоках. Это значительно ускоряет обработку, но также flatMap() что выбросы от оператора flatMap() , полученные Observer , не соответствуют порядку исходных выбросов в восходящем направлении.
Вывод
В этом руководстве вы узнали о том, как обрабатывать параллелизм с помощью RxJava 2: что это такое, различные доступные Schedulers и как использовать операторы параллелизма subscribeOn() и observeOn() . Я также показал вам, как использовать оператор flatMap() для достижения параллелизма.
А пока ознакомьтесь с другими нашими курсами и руководствами по языку Java и разработке приложений для Android!
-
Android SDKВведение в компоненты архитектуры Android
-
Android SDKЧто такое Android Instant Apps?
-
iOS SDK3 ужасные ошибки разработчиков iOS
-
Android SDKФункциональные приложения для Android в Котлине: Lambdas, Null Safety и многое другое
-
Android SDKНачните с RxJava 2 для Android


