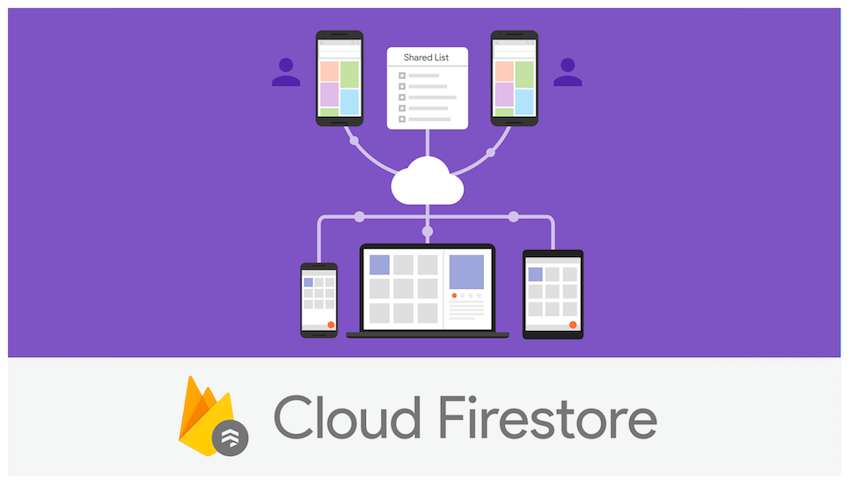
Мобильные кодеры уже много лет используют базу данных Firebase Realtime базы данных Google Mobile Backend as Service (MBaaS), помогая им сосредоточиться на создании функций для своих приложений, не беспокоясь о внутренней инфраструктуре и базе данных. Облегчая хранение и хранение данных в облаке и заботясь об аутентификации и безопасности, Firebase позволяет кодировщикам сосредоточиться на стороне клиента.
В прошлом году Google анонсировал еще одно серверное решение для баз данных, Cloud Firestore , созданное с нуля с обещанием большей масштабируемости и интуитивности. Однако это привело к некоторой путанице относительно его места по отношению к уже существующему флагманскому продукту Google, базе данных Firebase Realtime . В этом уроке будут изложены различия между двумя платформами и отличительные преимущества каждой из них. Вы узнаете, как работать со ссылками на документы Firestore, а также читать, писать, обновлять и удалять данные в режиме реального времени, создав простое приложение для напоминаний.
Цели этого урока
Это руководство познакомит вас с Cloud Firestore . Вы узнаете, как использовать платформу для сохранения и синхронизации базы данных в реальном времени. Мы рассмотрим следующие темы:
- что такое Cloud Firestore
- модель данных Firestore
- настройка Cloud Firestore
- создание и работа со ссылками Cloud Firestore
- чтение данных в режиме реального времени из Cloud Firestore
- создание, обновление и удаление данных
- фильтрация и составные запросы
Предполагаемые знания
В этом руководстве предполагается, что у вас есть опыт работы с Firebase и фон, развивающийся с помощью Swift и Xcode.
Что такое Cloud Firestore?
Как и база данных Firebase Realtime , Firestore предоставляет разработчикам мобильных приложений и веб-приложений кросс-платформенное облачное решение для сохранения данных в режиме реального времени, независимо от задержки в сети или подключения к Интернету, а также бесшовной интеграции с набором продуктов Google Cloud Platform. Наряду с этим сходством, есть определенные преимущества и недостатки, которые отличают одно от другого.
Модель данных
На фундаментальном уровне база данных реального времени хранит данные в виде одного большого монолитного иерархического дерева JSON, а Firestore организует данные в документах и коллекциях, а также в подколлекциях. Это требует меньше денормализации. Хранение данных в одном дереве JSON имеет преимущества простоты, когда речь идет о работе с простыми требованиями к данным; однако, это становится более громоздким в масштабе при работе с более сложными иерархическими данными.
Автономная поддержка
Оба продукта предлагают автономную поддержку, активно кэшируя данные в очередях, когда имеется скрытое или отсутствует сетевое подключение — синхронизация локальных изменений с серверной частью, когда это возможно. Firestore поддерживает автономную синхронизацию для веб-приложений в дополнение к мобильным приложениям, в то время как база данных реального времени включает только мобильную синхронизацию.
Запросы и транзакции
База данных реального времени поддерживает только ограниченные возможности сортировки и фильтрации — вы можете сортировать или фильтровать только на уровне свойств, но не оба одновременно, в одном запросе. Запросы также глубоки, что означает, что они возвращают большое поддерево результатов назад. Продукт поддерживает только простые операции записи и транзакции, которые требуют завершения обратного вызова.
Firestore, с другой стороны, вводит индексные запросы с составной сортировкой и фильтрацией, позволяя комбинировать действия для создания цепных фильтров и сортировки. Вы также можете выполнять поверхностные запросы, возвращающие под-коллекции вместо всей коллекции, которую вы получили бы с базой данных реального времени. Транзакции являются атомарными по своему характеру, независимо от того, отправляете ли вы пакетную операцию или одну операцию, транзакции повторяются автоматически до тех пор, пока не будут завершены. Кроме того, база данных Realtime поддерживает только отдельные транзакции записи, тогда как Firestore предоставляет пакетные операции атомарно.
Производительность и масштабируемость
База данных реального времени, как и следовало ожидать, достаточно надежна и имеет низкую задержку. Тем не менее, базы данных ограничены отдельными регионами, в зависимости от наличия зоны. Firestore, с другой стороны, размещает данные горизонтально в нескольких зонах и регионах, чтобы обеспечить истинную глобальную доступность, масштабируемость и надежность. На самом деле, Google пообещал, что Firestore будет более надежным, чем база данных в реальном времени.
Другим недостатком базы данных реального времени является ограничение в 100 000 одновременно работающих пользователей (100 000 одновременных подключений и 1000 операций записи в секунду в одной базе данных), после чего вам потребуется разделить базу данных (разделить базу данных на несколько баз данных) для поддержки большего количества пользователей. , Firestore автоматически масштабируется на несколько экземпляров без необходимости вмешательства.
Разработанный с нуля с учетом масштабируемости, Firestore имеет новую схематическую архитектуру, которая реплицирует данные в нескольких регионах, заботится об аутентификации и решает другие вопросы, связанные с безопасностью, все в своем клиентском SDK. Его новая модель данных более интуитивна, чем Firebase, более похожа на другие сопоставимые решения для баз данных NoSQL, такие как MongoDB, при этом обеспечивая более надежный механизм запросов.
Безопасность
Наконец, база данных Realtime, как вы знаете из наших предыдущих руководств, управляет безопасностью посредством каскадных правил с отдельными триггерами проверки. Это работает с правилами базы данных Firebase , проверяя ваши данные отдельно. Firestore, с другой стороны, предоставляет более простую, но более мощную модель безопасности, использующую преимущества облачных правил безопасности Firestore и Identity and Access Management (IAM) , с проверкой данных, выполняемой автоматически.
-
 Мобильная разработкаПравила безопасности Firebase
Мобильная разработкаПравила безопасности Firebase

Модель данных Firestore
Firestore — это база данных NoSQL на основе документов, состоящая из наборов документов, каждый из которых содержит данные. Поскольку это база данных NoSQL, вы не получите таблицы, строки и другие элементы, которые вы найдете в реляционной базе данных, а вместо этого наборы пар ключ / значение, которые вы найдете в документах.
Вы неявно создаете документы и коллекции, присваивая данные документу, и если документ или коллекция не существуют, они будут созданы автоматически для вас, поскольку коллекция всегда должна быть корневым (первым) узлом. Вот простой пример схемы Tasks для проекта, над которым вы будете работать в ближайшее время, состоящий из коллекции Tasks, а также многочисленных документов, содержащих два поля, имя (строку) и флаг того, выполнена ли задача (логическое значение) ,
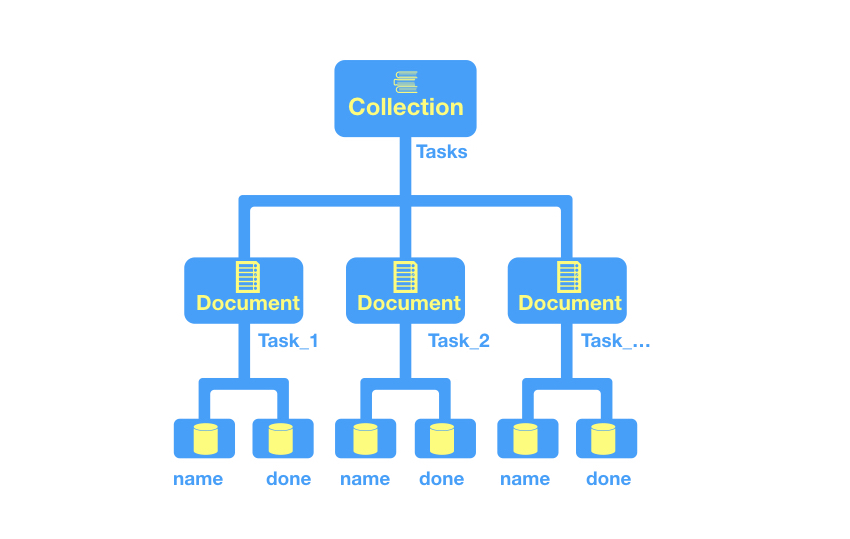
Давайте разложим каждый из элементов, чтобы вы могли лучше понять их.
Коллекции
Синонимы таблиц базы данных в мире SQL, коллекции содержат один или несколько документов. Коллекции должны быть корневыми элементами в вашей схеме и могут содержать только документы, но не другие коллекции. Однако вы можете обратиться к документу, который, в свою очередь, относится к коллекциям (подколлекциям).
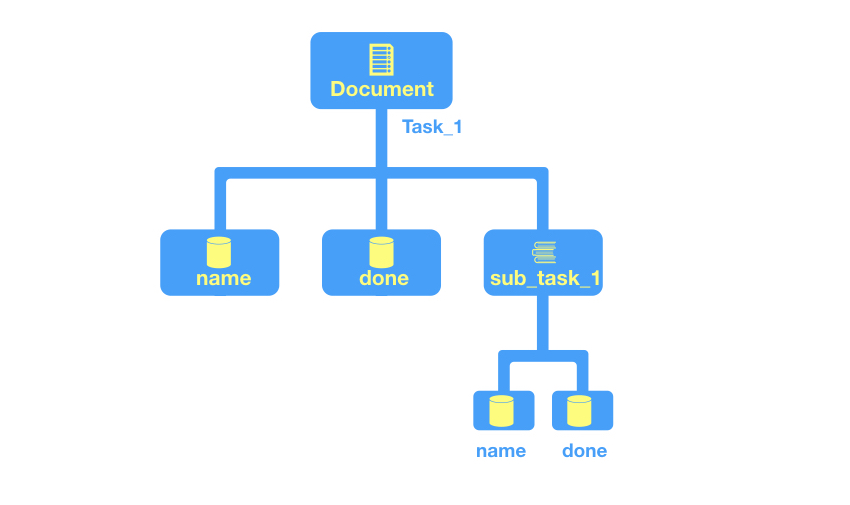
На приведенной выше диаграмме задача состоит из двух примитивных полей (имя и выполнено), а также подколлекции (подзадача), которая состоит из двух собственных примитивных полей.
документы
Документы состоят из пар ключ / значение, причем значения имеют один из следующих типов:
- примитивные поля (такие как строки, числа, логические)
- сложные вложенные объекты (списки или массивы примитивов)
- суб-коллекции
Вложенные объекты также называются картами и могут быть представлены в документе следующим образом. Ниже приведен пример вложенного объекта и массива соответственно:
|
1
2
3
4
5
6
7
8
9
|
ID: 2422892 //primitive
name: “Remember to buy milk”
detail: //nested object
notes: «This is a task to buy milk from the store»
created: 2017-04-09
due: 2017-04-10
done: false
notify: [«2F22-89R2», «L092-G623», «H00V-T4S1»]
…
|
Для получения дополнительной информации о поддерживаемых типах данных см. Документацию Google Types . Далее вы настроите проект для работы с Cloud Firestore.
Настройка проекта
Если вы работали с Firebase раньше, многое из этого должно быть вам знакомо. В противном случае вам нужно будет создать учетную запись в Firebase и следовать инструкциям в разделе «Настройка проекта» нашего предыдущего руководства « Начало работы с аутентификацией Firebase для iOS» .
Чтобы следовать этому уроку, клонируйте репозиторий проекта урока . Затем включите библиотеку Firestore добавив следующее в ваш Podfile :
|
1
2
|
pod ‘Firebase/Core’
pod ‘Firebase/Firestore’
|
Введите следующее в свой терминал, чтобы построить свою библиотеку:
|
1
|
pod install
|
Затем переключитесь на Xcode и откройте файл .xcworkspace . Перейдите к файлу AppDelegate.swift и введите в application:didFinishLaunchingWithOptions: method:
FirebaseApp.configure()
В вашем браузере перейдите на консоль Firebase и выберите вкладку База данных слева.
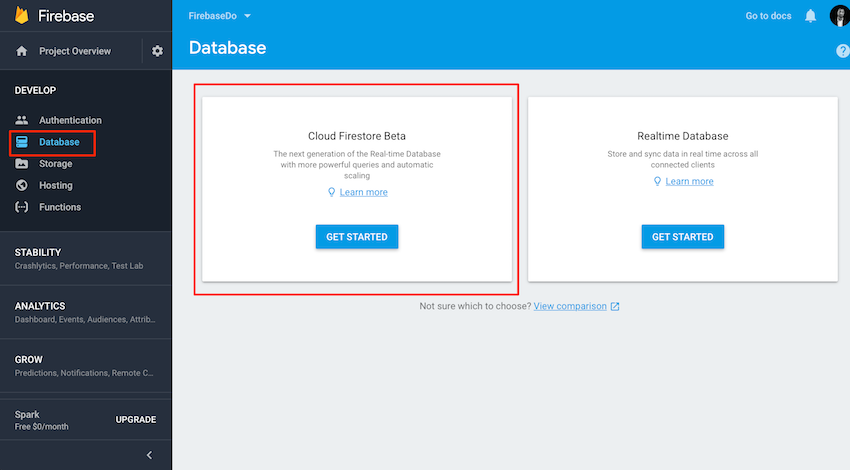
Убедитесь, что вы выбрали опцию « Запуск в тестовом режиме», чтобы у вас не возникало проблем с безопасностью во время эксперимента, и учитывайте уведомление о безопасности, когда вы переводите свое приложение в производство. Теперь вы готовы создать коллекцию и несколько образцов документов.
Добавление коллекции и образца документа
Для начала создайте исходную коллекцию Tasks , нажав кнопку Add Collection и присвоив ей имя, как показано ниже:
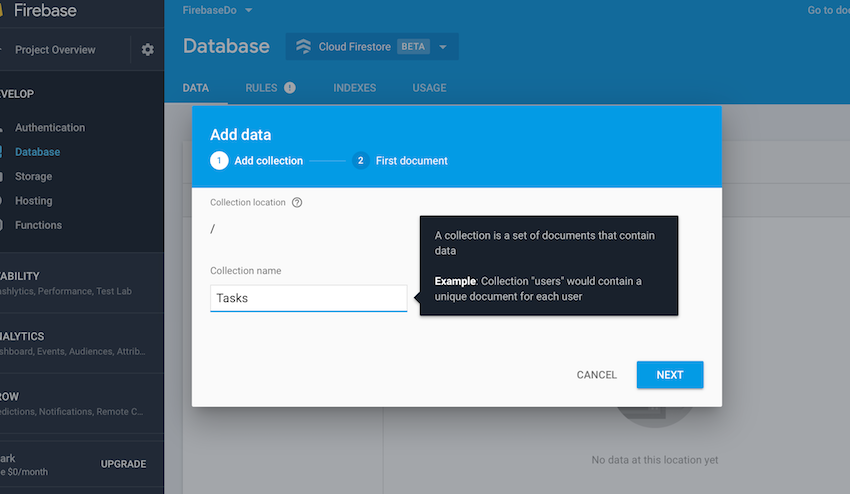
Для первого документа вы оставите Идентификатор документа пустым, что автоматически сгенерирует для вас идентификатор. Документ будет просто состоять из двух полей: name и done .
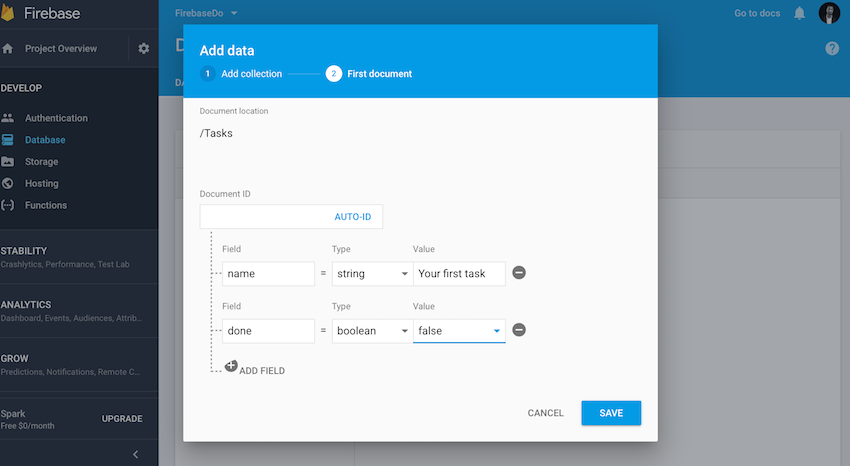
Сохраните документ, и вы сможете подтвердить коллекцию и документ вместе с автоматически сгенерированным идентификатором:
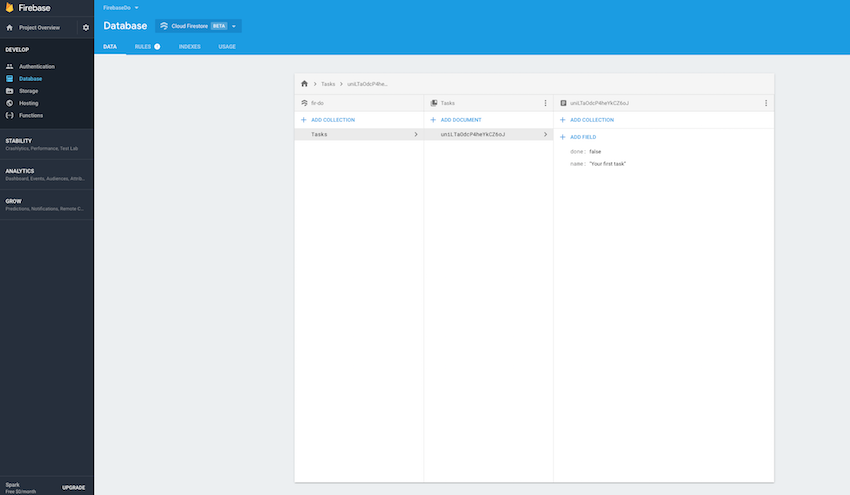
С базой данных, настроенной с образцом документа в облаке, вы готовы начать внедрять Firestore SDK в XCode.
Создание и работа с базами данных
Откройте файл MasterViewController.swift в XCode и добавьте следующие строки для импорта библиотеки:
|
1
2
3
4
5
6
7
8
9
|
import Firebase
class MasterViewController: UITableViewController {
@IBOutlet weak var addButton: UIBarButtonItem!
private var documents: [DocumentSnapshot] = []
public var tasks: [Task] = []
private var listener : ListenerRegistration!
…
|
Здесь вы просто создаете переменную слушателя, которая позволит вам в реальном времени инициировать соединение с базой данных, когда происходит изменение. Вы также создаете ссылку DocumentSnapshot которая будет содержать временный снимок данных.
Прежде чем продолжить работу с контроллером представления, создайте другой файл swift, Task.swift , который будет представлять вашу модель данных:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import Foundation
struct Task{
var name:String
var done: Bool
var id: String
var dictionary: [String: Any] {
return [
«name»: name,
«done»: done
]
}
}
extension Task{
init?(dictionary: [String : Any], id: String) {
guard let name = dictionary[«name»] as?
let done = dictionary[«done»] as?
else { return nil }
self.init(name: name, done: done, id: id)
}
}
|
Приведенный выше фрагмент кода содержит вспомогательное свойство (словарь) и метод (init), которые облегчат заполнение объекта модели. Вернитесь к контроллеру представления и объявите глобальную переменную-установщик, которая ограничит базовый запрос до 50 лучших записей в списке задач. Вы также будете удалять прослушиватель после установки переменной запроса, как didSet свойстве didSet ниже:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
fileprivate func baseQuery() -> Query {
return Firestore.firestore().collection(«Tasks»).limit(to: 50)
}
fileprivate var query: Query?
didSet {
if let listener = listener {
listener.remove()
}
}
}
override func viewDidLoad() {
super.viewDidLoad()
self.query = baseQuery()
}
override func viewWillDisappear(_ animated: Bool) {
super.viewWillDisappear(animated)
self.listener.remove()
}
|
Чтение данных в режиме реального времени из облачного Firestore
При наличии ссылки на документ в viewWillAppear(_animated: Bool) созданный ранее прослушиватель с результатами моментального снимка запроса и получите список документов. Это делается путем вызова query?.addSnapshotListener метода Firestore query?.addSnapshotListener :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
self.listener = query?.addSnapshotListener { (documents, error) in
guard let snapshot = documents else {
print(«Error fetching documents results: \(error!)»)
return
}
let results = snapshot.documents.map { (document) -> Task in
if let task = Task(dictionary: document.data(), id: document.documentID) {
return task
} else {
fatalError(«Unable to initialize type \(Task.self) with dictionary \(document.data())»)
}
}
self.tasks = results
self.documents = snapshot.documents
self.tableView.reloadData()
}
|
Приведенное выше закрытие присваивает snapshot.documents путем итеративного сопоставления массива и переноса его в новый объект экземпляра модели Task для каждого элемента данных в снимке. Таким образом, всего за несколько строк вы успешно прочитали все задачи из облака и присвоили их глобальным tasks массив.
Чтобы отобразить результаты, заполните следующее TableView методы делегата:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
override func numberOfSections(in tableView: UITableView) -> Int {
return 1
}
override func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
return tasks.count
}
override func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(withIdentifier: «Cell», for: indexPath)
let item = tasks[indexPath.row]
cell.textLabel!.text = item.name
cell.textLabel!.textColor = item.done == false ?
return cell
}
|
На этом этапе соберите и запустите проект, и в симуляторе вы сможете наблюдать за данными, появляющимися в режиме реального времени. Добавьте данные через консоль Firebase, и вы должны увидеть, что они мгновенно появляются в симуляторе приложения.
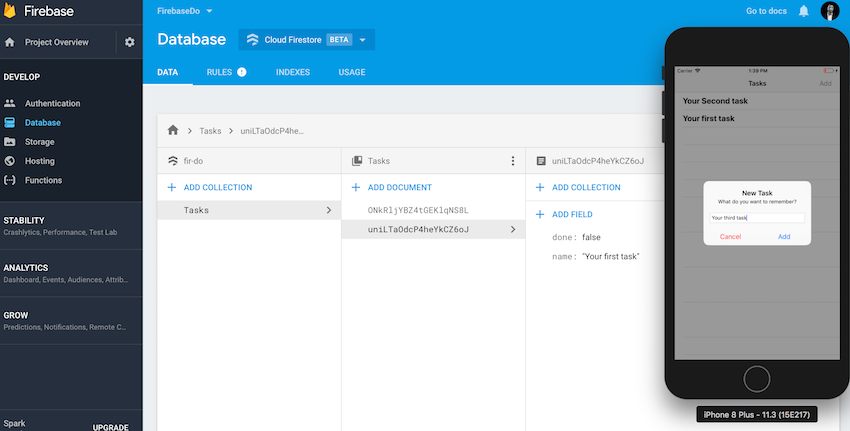
Создание, обновление и удаление данных
После успешного прочтения контента из серверной части, затем вы будете создавать, обновлять и удалять данные. Следующий пример иллюстрирует, как обновить данные, используя надуманный пример, в котором приложение позволяет только пометить элемент как выполненный, нажав на ячейку. Обратите внимание на свойство закрытия collection.document( ).updateData(["done": !item.done]) , которое просто ссылается на определенный идентификатор документа, обновляя каждое из полей в словаре:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
override func tableView(_ tableView: UITableView,
didSelectRowAt indexPath: IndexPath) {
let item = tasks[indexPath.row]
let collection = Firestore.firestore().collection(«Tasks»)
collection.document(item.id).updateData([
«done»: !item.done,
]) { err in
if let err = err {
print(«Error updating document: \(err)»)
} else {
print(«Document successfully updated»)
}
}
tableView.reloadRows(at: [indexPath], with: .automatic)
}
|
Чтобы удалить элемент, вызовите метод document( ).delete() :
|
01
02
03
04
05
06
07
08
09
10
11
|
override func tableView(_ tableView: UITableView, canEditRowAt indexPath: IndexPath) -> Bool {
return true
}
override func tableView(_ tableView: UITableView, commit editingStyle: UITableViewCellEditingStyle, forRowAt indexPath: IndexPath) {
if (editingStyle == .delete){
let item = tasks[indexPath.row]
_ = Firestore.firestore().collection(«Tasks»).document(item.id).delete()
}
}
|
Создание новой задачи будет включать добавление новой кнопки в вашу раскадровку и подключение ее IBAction к контроллеру представления, создав addTask(_ sender:) . Когда пользователь нажимает кнопку, он выводит на экран лист предупреждения, где пользователь может добавить новое имя задачи:
|
1
2
3
|
collection(«Tasks»).addDocument
(data: [«name»: textFieldReminder.text ??
«empty task», «done»: false])
|
Завершите финальную часть приложения, введя следующее:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
@IBAction func addTask(_ sender: Any) {
let alertVC : UIAlertController = UIAlertController(title: «New Task», message: «What do you want to remember?», preferredStyle: .alert)
alertVC.addTextField { (UITextField) in
}
let cancelAction = UIAlertAction.init(title: «Cancel», style: .destructive, handler: nil)
alertVC.addAction(cancelAction)
//Alert action closure
let addAction = UIAlertAction.init(title: «Add», style: .default) { (UIAlertAction) -> Void in
let textFieldReminder = (alertVC.textFields?.first)!
let db = Firestore.firestore()
var docRef: DocumentReference?
docRef = db.collection(«Tasks»).addDocument(data: [
«name»: textFieldReminder.text ??
«done»: false
]) { err in
if let err = err {
print(«Error adding document: \(err)»)
} else {
print(«Document added with ID: \(docRef!.documentID)»)
}
}
}
alertVC.addAction(addAction)
present(alertVC, animated: true, completion: nil)
}
|
Создайте и запустите приложение еще раз, и, когда появится симулятор, попробуйте добавить несколько задач, а также пометить несколько как выполненные и, наконец, протестировать функцию удаления, удалив некоторые задачи. Вы можете подтвердить, что сохраненные данные были обновлены в режиме реального времени, переключившись на консоль базы данных Firebase и наблюдая за коллекцией и документами.
Фильтрация и составные запросы
До сих пор вы работали только с простым запросом, без каких-либо специальных возможностей фильтрации. Чтобы создать чуть более надежные запросы, вы можете фильтровать по определенным значениям, используя предложение whereField :
|
1
|
docRef.whereField(“name”, isEqualTo: searchString)
|
Вы можете упорядочить и ограничить данные запроса, используя методы order(by: ) и limit(to: ) ? следующим образом:
|
1
|
docRef.order(by: «name»).limit(5)
|
В приложении FirebaseDo вы уже использовали limit с базовым запросом. В приведенном выше фрагменте вы также использовали другую функцию — составные запросы, в которых и порядок, и предел связаны друг с другом. Вы можете связать столько запросов, сколько хотите, например, в следующем примере:
|
1
2
3
4
5
|
docRef
.whereField(“name”, isEqualTo: searchString)
.whereField(“done”, isEqualTo: false)
.order(by: «name»)
.limit(5)
|
Вывод
В этом руководстве вы изучили новый продукт Google MBaaS, Cloud Firestore , и в процессе создали простое приложение с напоминанием о задачах, которое демонстрирует, как легко сохранять, синхронизировать и запрашивать данные в облаке. Вы узнали о структуре схемы данных Firestore по сравнению с базой данных Firebase Realtime , а также о том, как читать и записывать данные в режиме реального времени, а также обновлять и удалять данные. Вы также узнали, как выполнять простые и сложные запросы и как фильтровать данные.
Облачное хранилище пожаров было создано с целью обеспечения надежности базы данных Firebase Realtime без многих ограничений, которые должны были перенести мобильные разработчики, особенно в том, что касается масштабируемости и запросов. Мы лишь слегка коснулись того, что вы можете сделать с помощью Firestore, и, безусловно, стоит изучить некоторые из более сложных концепций, таких как разбиение на страницы данных с помощью курсоров запросов , управление индексами и защита ваших данных .