1. Введение
Проще говоря, регулярные выражения (регулярные выражения или сокращенные выражения) являются способом задания строковых шаблонов. Вы, несомненно, знакомы с функцией поиска и замены в вашем любимом текстовом редакторе или IDE. Вы можете искать точные слова и фразы. Вы также можете активировать опции, такие как нечувствительность к регистру, чтобы при поиске по слову «цвет» также находились «Цвет», «ЦВЕТ» и «CoLoR». Но что, если вы хотите найти варианты правописания слова «цвет» (американское правописание: цвет, британское правописание: цвет) без необходимости выполнять два отдельных поиска?
Если этот пример кажется слишком простым, как насчет того, чтобы найти все варианты правописания английского имени «Кэтрин» (Кэтрин, Кэтрин, Кэтрин, Кэтрин и т. Д., Чтобы назвать несколько). В более общем случае вы можете искать в документе все строки, похожие на шестнадцатеричные числа, даты, номера телефонов, адреса электронной почты, номера кредитных карт и т. Д.
Регулярные выражения являются мощным способом (частично или полностью) решения этих (и многих других) практических проблем, связанных с текстом.
Контур
Структура этого урока следующая. Я представлю основные концепции, которые вам необходимо понять, адаптировав подход, используемый в теоретических учебниках (после устранения ненужной строгости или педантизма). Я предпочитаю этот подход, потому что он позволяет вам понять, возможно, 70% функциональности, которая вам понадобится, в контексте нескольких основных принципов. Оставшиеся 30% — это более продвинутые функции, которые вы можете изучить позже или пропустить, если только вы не собираетесь стать мастером регулярных выражений.
С регулярными выражениями связано множество синтаксисов, но большинство из них просто для того, чтобы вы могли применять основные идеи максимально лаконично. Я буду вводить их постепенно, а не опускать большую таблицу или список для запоминания.
Вместо того, чтобы сразу переходить к реализации Swift, мы изучим основы с помощью отличного онлайн-инструмента, который поможет вам проектировать и оценивать регулярные выражения с минимальным трением и ненужным багажом. Когда вы освоитесь с основными идеями, написание кода на Swift станет проблемой сопоставления вашего понимания с API Swift.
Мы будем стараться придерживаться прагматичного мышления. Регулярные выражения — не лучший инструмент для каждой ситуации обработки строк. На практике нам нужно определить ситуации, когда регулярные выражения работают очень хорошо, и ситуации, когда они не работают. Существует также золотая середина, где регулярные выражения могут использоваться для выполнения части работы (обычно некоторой предварительной обработки и фильтрации), а остальная часть работы оставлена алгоритмической логике.
Основные понятия
Регулярные выражения имеют свои теоретические основы в «теории вычислений», одной из тем, изучаемых информатикой, где они играют роль входных данных, применяемых к определенному классу абстрактных вычислительных машин, называемых конечными автоматами.
Расслабьтесь, однако, вы не обязаны изучать теоретические основы, чтобы использовать регулярные выражения практически. Я упоминаю их только потому, что подход, который я буду использовать для первоначальной мотивации регулярных выражений с нуля, отражает подход, используемый в учебниках по информатике для определения «теоретических» регулярных выражений.
Предполагая, что вы немного знакомы с рекурсией, я хотел бы, чтобы вы помнили, как определяются рекурсивные функции. Функция определяется в терминах ее более простых версий, и, если вы проследите рекурсивное определение, вы должны получить базовый случай, который явно определен. Я поднимаю это, потому что наше определение ниже также будет рекурсивным.
Обратите внимание, что, когда мы говорим о строках в целом, мы неявно имеем в виду набор символов, таких как ASCII, Unicode и т. Д. Давайте представим, что мы живем во вселенной, где строки состоят из 26 букв нижнего регистра алфавит (a, b, … z) и ничего больше.
правила
Мы начнем с утверждения, что каждый символ в этом наборе можно рассматривать как регулярное выражение, совпадающее с ним как строку. Так a как регулярное выражение соответствует «a» (рассматривается как строка), b является регулярным выражением, совпадающим со строкой «b» и т. д. Также допустим, что существует «пустое» регулярное выражение Ɛ которое соответствует пустой строке «». Такие случаи соответствуют тривиальным «базовым случаям» рекурсии.
Теперь мы рассмотрим следующие правила, которые помогают нам создавать новые регулярные выражения из существующих:
- Конкатенация (то есть «связывание вместе») любых двух регулярных выражений — это новое регулярное выражение, которое соответствует конкатенации любых двух строк, которые соответствуют исходным регулярным выражениям.
- Чередование двух регулярных выражений — это новое регулярное выражение, которое соответствует любому из двух исходных регулярных выражений.
- Звезда Клини регулярного выражения соответствует нулю или более смежных экземпляров того, что соответствует исходному регулярному выражению.
Давайте сделаем это из нескольких простых примеров с нашими алфавитными строками.
Пример 1
Из правила 1, a и b являются регулярными выражениями, совпадающими с «a» и «b», означает, что ab является регулярным выражением, соответствующим строке «ab». Поскольку ab и c являются регулярными выражениями, abc является регулярным выражением, соответствующим строке «abc», и так далее. Продолжая этот путь, мы можем создавать произвольные длинные регулярные выражения, соответствующие строке с одинаковыми символами. Ничего интересного еще не произошло.
Пример 2
Из правила 2, o и a являются регулярными выражениями, o|a соответствует «o» или «a». Вертикальная черта представляет чередование. c и t являются регулярными выражениями, и в сочетании с правилом 1 мы можем утверждать, что c(o|a)t является регулярным выражением. Скобки используются для группировки.
Что это соответствует? c и t соответствуют друг другу, что означает, что регулярное выражение c(o|a)t соответствует «c», за которым следуют «a» или «o», за которыми следует «t», например, строка «cat» или «cot». Обратите внимание, что оно не соответствует «coat», поскольку o|a только «a» или «o», но не одновременно обоим. Теперь вещи начинают становиться интересными.
Пример 3
Из правила 3 a* соответствует нулю или более экземпляров «а». Он соответствует пустой строке или строкам «a», «aa», «aaa» и т. Д. Давайте реализуем это правило в сочетании с двумя другими правилами.
Что совпадает? Он соответствует «ht» (с нулевыми значениями «o»), «hot», «hoot», «hooot» и так далее. Как насчет b(o|a)* ? Он может соответствовать «b», за которым следует любое количество экземпляров «o» и «a» (включая ни одного из них). «b», «boa», «baa», «bao», «baooaoaoaoo» — это лишь некоторые из бесконечного числа строк, которым соответствует это регулярное выражение. Еще раз обратите внимание, что круглые скобки используются для группировки части регулярного выражения, к которому применяется * .
Пример 4
Давайте попробуем найти регулярные выражения, которые соответствуют строкам, которые мы уже имеем в виду. Как бы мы сделали регулярное выражение, которое распознает блешение овец, которое я буду рассматривать как любое количество повторений основного звука «baa» («baa», «baabaa», «baabaabaa» и т. Д.)
Если вы сказали (baa)* , то вы почти правы. Но обратите внимание, что это регулярное выражение также будет соответствовать пустой строке, что нам не нужно. Другими словами, мы хотим игнорировать не блеющих овец. baa(baa)* — это регулярное выражение, которое мы ищем. Точно так же мычание коровы может быть moo(moo)* . Как мы можем узнать звук любого животного? Просто. Используйте чередование. baa(baa)*|moo(moo)*
Если вы поняли вышеизложенные идеи, поздравляю, вы уже в пути.
2. Вопросы синтаксиса
Напомним, мы наложили глупые ограничения на наши строки. Они могут состоять только из строчных букв алфавита. Теперь мы отменим это ограничение и рассмотрим все строки, состоящие из символов ASCII.
Мы должны понимать, что для того, чтобы регулярные выражения были удобным инструментом, они сами должны быть представлены в виде строк. Таким образом, в отличие от ранее, мы больше не можем использовать символы, такие как * , | , ( , ) и т. д. без какой-либо сигнализации о том, используем ли мы их в качестве «специальных» символов, представляющих чередование, группировку и т. д., или рассматриваем ли мы их как обычные символы, которые должны буквально совпадать.
Решение состоит в том, чтобы рассматривать эти и другие «метасимволы», которые могут иметь особое значение. Чтобы переключаться между одним использованием и другим, мы должны быть в состоянии избежать их. Это похоже на идею использования «\ n» (экранирование n) для обозначения новой строки в строке. Это немного сложнее в том смысле, что в зависимости от символа контекста, который обычно является «мета», он может представлять свое буквальное «я» без отступления. Мы увидим примеры этого позже.
Еще одна вещь, которую мы ценим, это лаконичность. Многие регулярные выражения, которые могут быть выражены с использованием только записи предыдущего раздела, были бы утомительно многословны. Например, предположим, что вы просто хотите найти все две строки символов, состоящие из строчной буквы, за которой следует цифра (например, строки типа «a0», «b9», «z3» и т. Д.). Используя обозначения, которые мы обсуждали ранее, это привело бы к следующему регулярному выражению:
|
1
|
(a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z)(0|1|2|3|4|5|6|7|8|9)
|
Просто печатать это чудовище уничтожило меня.
Разве [abcdefghijklmnopqrstuvwxyz][0123456789] выглядит лучше? Обратите внимание на метасимволы [ и ] которые обозначают набор символов, любой из которых дает положительное совпадение. На самом деле, если учесть, что буквы от a до z и цифры от 0 до 9 встречаются последовательно в наборе ASCII, мы можем уменьшить регулярное выражение до крутого [az][0-9] .
В пределах набора символов тире, - , еще один метасимвол, указывающий диапазон. Обратите внимание, что вы можете сжать несколько диапазонов в одну пару квадратных скобок. Например, [0-9a-zA-Z] может соответствовать любому буквенно-цифровому символу. 9 и а (и з и а ) прижатые друг к другу могут выглядеть смешно, но помните, что регулярные выражения — это краткость, а смысл понятен.
Говоря о краткости, есть еще более краткие способы представления определенных классов связанных символов, как мы увидим через минуту. Обратите внимание, что полоса чередования, | , по-прежнему действителен и полезен синтаксис, как мы увидим через мгновение.
Больше синтаксиса
Прежде чем мы начнем практиковать, давайте рассмотрим немного больше синтаксиса.
период
Период . , соответствует любому отдельному символу, за исключением переносов строк. Это означает, что ct может соответствовать «cat», «crt», «c9t», «c% t», «ct», «ct» и так далее. Если бы мы хотели сопоставить точку как обычный символ, например, чтобы соответствовать строке «ct», мы могли бы либо экранировать ее ( c\.t ), либо поместить ее в собственный класс символов ( c[.]t ).
В целом, эти идеи применимы к другим метасимволам, таким как [ , ] , ( , ) , * и другим, с которыми мы еще не сталкивались.
Круглые скобки
Круглые скобки ( ( и ) ) используются для группировки, как мы видели ранее. Мы собираемся использовать слово token для обозначения либо одного символа, либо выражения в скобках. Причина в том, что многие операторы регулярных выражений могут быть применены к любому из них.
Скобки также используются для определения групп захвата , что позволяет вам определить, какая часть вашего совпадения была захвачена определенной группой захвата в регулярном выражении. Я расскажу об этом очень полезном функционале позже.
плюс
Знак + после токена является одним или несколькими экземплярами этого токена. В нашем примере с блеять овец baa baa(baa)* можно представить более кратко как (baa)+ . Напомним, что * означает ноль или более вхождений. Обратите внимание, что (baa)+ отличается от baa+ , потому что в первом знак + применяется к токену baa тогда как в последнем он применяется только к a перед ним. В последнем случае он соответствует строкам типа «baa», «baaa» и «baaaa».
Вопросительный знак
А ? следование токену означает ноль или один экземпляр этого токена.
практика
RegExr — отличный онлайн-инструмент для экспериментов с регулярными выражениями. Когда вы освоите чтение и написание регулярных выражений, будет гораздо проще использовать API регулярных выражений платформы Foundation. Даже тогда вам будет проще сначала проверить свое регулярное выражение в режиме реального времени на веб-сайте.
Посетите веб-сайт и сфокусируйтесь на основной части страницы. Вот что вы увидите:
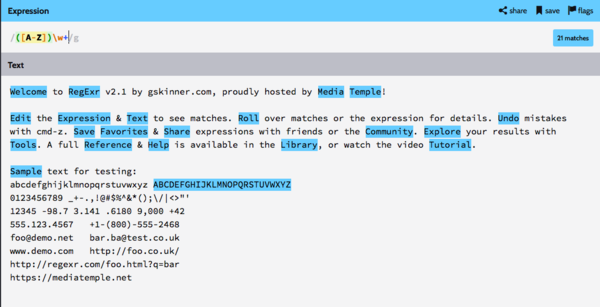
Вы вводите регулярное выражение в поле вверху и вводите текст, в котором вы ищете совпадения.
«/ G» в конце поля выражения не является частью регулярного выражения как такового. Это флаг, который влияет на общее поведение сопоставления движка регулярных выражений. Добавляя «/ g» к регулярному выражению, движок ищет все возможные совпадения регулярного выражения в тексте, что является желаемым поведением. Синяя подсветка указывает на совпадение. Наведите указатель мыши на регулярное выражение, это удобный способ напомнить вам о значении составляющих его частей.
Знайте, что регулярные выражения могут быть различными, в зависимости от языка или библиотеки, которую вы используете. Это означает не только то, что синтаксис может немного отличаться в разных вариантах, но также и возможности и возможности. Swift, например, использует синтаксис шаблона, определенный ICU. Я не уверен, какой вариант используется в RegExr (который работает на JavaScript), но в рамках этого руководства они очень похожи, если не идентичны.
Я также призываю вас изучить панель слева, в которой много информации представлено в сжатой форме.
Наш первый практический пример
Чтобы избежать путаницы, я должен упомянуть, что, говоря о сопоставлении регулярных выражений, мы можем иметь в виду одно из двух:
- ищет любые (или все) подстроки строки, которые соответствуют регулярному выражению
- проверка, соответствует ли полная строка регулярному выражению
Значением по умолчанию, с которым работают механизмы регулярных выражений, является (1). До сих пор мы говорили о (2). К счастью, смысл (2) легко реализовать с помощью метасимволов, которые будут представлены позже. Не волнуйтесь об этом сейчас.
Давайте начнем с простого тестирования нашего примера блеения овец. Введите (baa)+ в поле выражения и несколько примеров для проверки совпадений, как показано ниже.
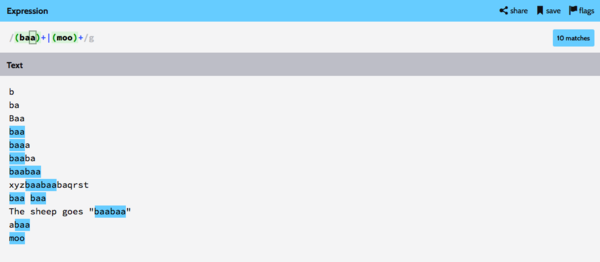
Я надеюсь, вы понимаете, почему на самом деле удачные матчи были успешными, а другие — неудачными. Даже в этом простом примере есть несколько интересных вещей, на которые следует обратить внимание.
Жадные матчи
Строка «baabaa» содержит два совпадения или одно? Другими словами, является ли каждый отдельный «baa» совпадением или весь «baabaa» — одиночным совпадением? Это зависит от того, ищется ли «жадная спичка». Жадное совпадение пытается сопоставить как можно большую часть строки.
Прямо сейчас движок регулярных выражений совпадает с жадностью, а это значит, что «baabaa» — это одно совпадение. Есть способы сделать ленивое соответствие, но это более сложная тема, и, поскольку у нас уже есть полные листы, мы не будем освещать это в этом уроке.
Инструмент RegExr оставляет небольшой, но заметный пробел в выделении, если две смежные части строки каждая по отдельности (но не вместе) соответствуют регулярному выражению. Мы увидим пример такого поведения чуть позже.
Прописные и строчные
«Baabaa» терпит неудачу из-за заглавной буквы «B». Скажем, вы хотите, чтобы только первая буква «B» была заглавной, каким будет соответствующее регулярное выражение? Попробуй сначала разобраться сам.
Один ответ — (B|b)aa(baa)* . Это поможет, если вы прочитаете это вслух. Прописные или строчные буквы «b», за которыми следует «aa», за которым следует ноль или более экземпляров «baa». Это выполнимо, но учтите, что это может быстро стать неудобным, особенно если мы хотим полностью игнорировать капитализацию. Например, мы должны были бы указать альтернативы для каждого случая, что привело бы к чему-то громоздкому, как ([Bb][Aa][Aa])+ .
К счастью, механизмы регулярных выражений обычно имеют возможность игнорировать регистр. В случае RegExr, нажмите кнопку с надписью «flags» и установите флажок «ignore case». Обратите внимание, что буква «i» добавляется перед списком опций в конце регулярного выражения. Попробуйте несколько примеров со смешанными буквами, например, «bAABaa».
Другой пример
Давайте попробуем разработать регулярное выражение, которое может захватывать варианты имени «Кэтрин». Как бы вы подошли к этой проблеме? Я бы записал как можно больше вариантов, взглянул на общие части, а затем попытался выразить словами варианты (с акцентом на альтернативные и дополнительные буквы) в виде последовательности. Далее я попытаюсь сформулировать регулярное выражение, которое ассимилирует все эти вариации.
Давайте попробуем это с этим списком вариантов: Кэтрин, Кэтрин, Кэтрин, Кэтрин, Кэтлин, Катрин и Катрин. Я оставлю это на ваше усмотрение, чтобы записать еще несколько, если хотите. Глядя на эти варианты, я могу примерно сказать, что:
- имя начинается с «k» или «c»
- с последующим «в»
- с последующим, возможно, «ч»
- возможно сопровождаемый «а» или «е»
- сопровождаемый или «r» или «l»
- сопровождаемый одним из «я», «ее» или «у»
- и определенно следует за «н»
- возможно, «е» в конце
Имея в виду эту идею, я могу придумать следующее регулярное выражение:
|
1
|
[kc]ath?[ae]?(r|l)(i|ee|y)ne?
|
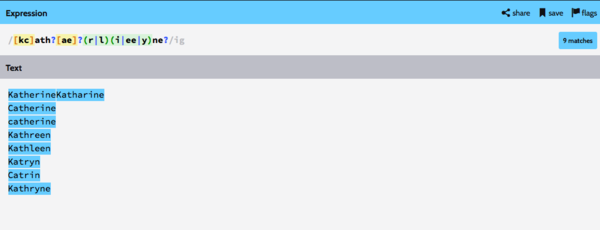
Обратите внимание, что в первой строке «KatherineKatharine» есть два совпадения без разделения между ними. Если вы внимательно посмотрите на это в текстовом редакторе RegExr, вы можете заметить небольшой разрыв в выделении между двумя совпадениями, о чем я говорил ранее.
Обратите внимание, что приведенное выше регулярное выражение также соответствует именам, которые мы не рассматривали и которые могли бы даже не существовать, например, «Cathalin». В нынешнем контексте это никак не влияет на нас. Но в некоторых приложениях, таких как проверка электронной почты, вы хотите быть более точными в отношении строк, которые вам соответствуют, и тех, которые вы отклоняете. Это обычно увеличивает сложность регулярного выражения.
Больше синтаксиса и примеров
Прежде чем мы перейдем к Swift, я хотел бы обсудить еще несколько аспектов синтаксиса регулярных выражений.
Краткие представления
Несколько классов связанных символов имеют краткое представление:
-
\wбуквенно-цифровой символ, включая подчеркивание, эквивалентный[a-zA-Z0-9_] -
\dпредставляет собой цифру, эквивалентную[0-9] -
\sпредставляет пробел, то есть пробел, табуляцию или разрыв строки
Эти классы также имеют соответствующие отрицательные классы:
-
\Wпредставляет не алфавитно-цифровой символ без подчеркивания -
\Dне цифра -
\Sнепробельный символ
Запомните некапитализированные классы, а затем вспомните, что соответствующий им заглавный соответствует тому, что некапитализированный класс не соответствует. Обратите внимание, что они могут быть объединены путем включения в квадратные скобки при необходимости. Например, [\s\S] представляет любой символ, включая разрывы строк. Напомним, что период . соответствует любому символу, кроме разрывов строк.
Якоря
^ и $ являются якорями, которые представляют начало и конец строки соответственно. Помните, что я написал, что вы можете сопоставить всю строку, а не искать совпадения подстроки? Вот как ты это делаешь. ^c[oau]t$ соответствует «cat», «cot» или «cut», но не, скажем, «catch» или «recut».
Слово Границы
\b представляет границу между словами, например, из-за пробела или пунктуации, а также начала или конца строки. Обратите внимание, что он немного отличается тем, что соответствует позиции, а не явному символу. Это может помочь думать о границе слова как о невидимом разделителе, который отделяет слово от предыдущего / следующего. Как и следовало ожидать, \B представляет «не слово границы». \bcat\b находит совпадения в \bcat\b «кошка», «кошка», «привет, кошка», но не в словах «acat» или «catch».
Отрицание
Идею отрицания можно сделать более конкретной, используя метасимвол ^ внутри набора символов. Это совершенно другое использование ^ от «начала привязки строки». Это означает, что для отрицания ^ должен использоваться в наборе символов в самом начале. [^a] соответствует любому символу, кроме буквы «a», а [^az] соответствует любому символу, кроме строчной буквы.
Можете ли вы представить \W используя отрицание и диапазон символов? Ответ [^A-Za-z0-9_] . Как вы думаете, [a^] соответствует? Ответ может быть символом «а» или «^», поскольку он не встречался в начале набора символов. Здесь «^» соответствует буквально.
В качестве альтернативы, мы могли бы избежать этого явно так: [\^a] . Надеюсь, вы начинаете развивать интуицию о том, как избежать.
Кванторы
Мы увидели, как * (и + ) можно использовать для сопоставления токена ноль или более (и один или несколько) раз. Эта идея сопоставления токена несколько раз может быть конкретизирована с помощью квантификаторов в фигурных скобках. Например, {2, 4} означает два-четыре совпадения предыдущего токена. {2,} означает два или более совпадений, а {2} означает ровно два совпадения.
Мы рассмотрим подробные примеры, которые используют большинство этих элементов в следующем уроке. Но для практики я призываю вас создать свои собственные примеры и протестировать синтаксис, который мы только что увидели с помощью инструмента RegExr.
Вывод
В этом уроке мы в основном сосредоточились на теории и синтаксисе регулярных выражений. В следующем уроке мы добавим Swift к миксу. Прежде чем двигаться дальше, убедитесь, что вы понимаете, что мы рассмотрели в этом руководстве, поигравшись с RegExr .