Почему согласованность?
Но почему я выбрал Coherence, а не другие? Мне нравится работать со GlassFish, и я недавно искал стабильную и простую интеграцию с одной из этих сеток в памяти для некоторых случаев интенсивного использования данных. Поэтому первое место, которое нужно было посмотреть, — это стек продуктов Oracle. Более или менее движимая идеей, что должна быть какая-либо интеграция в EclipseLink, который представляет собой JPA 2.0 RI, поставляемый со GlassFish. Тем более, что есть новый Cache API с JPA 2.0.
Первое исследование выявило утечку информации в этой теме. Ни один из упомянутых продуктов до сих пор не имеет какого-либо плагина или другой интеграции с EclipseLink. Даже если EclipseLink имеет нечто, называемое фреймворком «перехватчик кэша», который позволяет действительно легко подключаться к сторонним системам кэширования, я искал (вероятно, поддерживаемое) решение ootb. Так что в итоге я посмотрел на Coherence. Небольшое замечание: я не тот человек, который спрашивает о лицензировании или стоимости. Все, что я делаю, это использую Coherence в соответствии с лицензией OTN .
Что такое согласованность?
Oracle Coherence — это сеточное решение для хранения данных. Вы можете масштабировать критически важные приложения с помощью Coherence, чтобы обеспечить очень быстрый доступ к часто используемым данным. Автоматически и динамически распределяя данные в памяти между несколькими серверами, Coherence обеспечивает постоянную доступность данных и целостность транзакций даже в случае сбоя сервера. Это общая инфраструктура, которая сочетает локальность данных с локальной вычислительной мощностью для выполнения анализа данных в реальном времени, вычислений в сетке в памяти и параллельной обработки транзакций и событий.
Стратегии для JPA на сетке
Все сеточные решения для данных в памяти имеют очень простой API ввода / вывода. Вы выдаете что-то вроде:
|
1
2
|
Cache.put(key, object);Cache.get(key); |
хранить ваши объекты в кеше или вернуть их из кеша. Coherence будет ответственным за сохранение всего в вашей базе данных (возможно, с использованием EclipseLink). С точки зрения приложения это выглядит как очень простой API для использования. Давайте назовем это «Кешами, поддерживаемыми JPA». Но это только один из трех возможных сценариев. Вторым является подход L2 Cache для JPA, который в основном означает, что вы просто реализуете приложение на основе JPA и подключаете согласованность на втором этапе. В-третьих, комбинация первых двух и просто перенаправляет все операции базы данных в Coherence. Все три имеют свои положительные стороны и, конечно, недостатки.
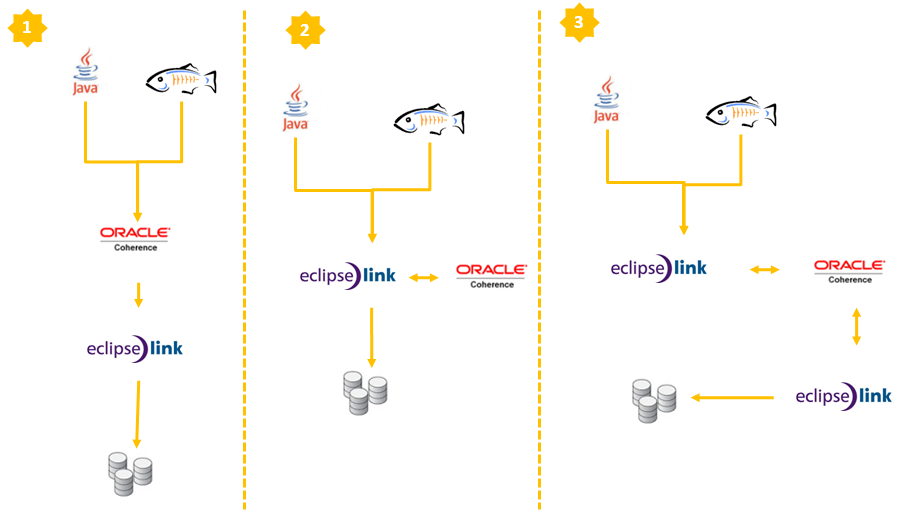
Продукты и определения
На данный момент лучше всего посмотреть на различные продукты и названия вокруг. JPA 2 RI — это EclipseLink , которая является частью коммерческого предложения от Oracle под названием TopLink . Вся интеграция Coherence является частью продукта TopLink Grid, который также содержит EclipseLink в качестве реализации JPA.
1) JPA поддерживает кэши
Вы можете использовать Coherence API с кэшами, поддерживаемыми базой данных, отображаемой через JPA. Сетка обращается к реляционным данным через реализации JPA CacheLoader и CacheStore. В этом «традиционном» подходе Coherence TopLink Grid предоставляет реализации CacheLoader и CacheStore, оптимизированные для EclipseLink JPA. ( EclipseLinkJPACacheLoader и EclipseLinkJPACacheStore ), которые содержатся в файле toplink-grid.jar . Таким образом, вы используете стандартный файл конфигурации JPA времени выполнения persistence.xml и файл отображения JPA orm.xml. Файл конфигурации кэша Coherence coherence-cache-config.xml должен быть указан для переопределения настроек Coherence по умолчанию и определения схемы кэширования CacheStore.
Я покажу вам этот пример со второй частью серии.
2) JPA L2 Cache
Конфигурация Grid Cache использует Coherence как общий кэш JPA (L2).
Запросы первичного ключа пытаются сначала получить объекты из Coherence и, в случае неудачи, запросят базу данных, обновив Coherence результатами запроса. Запросы неосновного ключа выполняются к базе данных, а результаты сравниваются с Coherence, чтобы избежать затрат на создание объектов для кэшированных объектов. Новые запрашиваемые объекты вводятся в Coherence. Операции записи обновляют базу данных и, в случае успешного принятия, обновленные сущности помещаются в Coherence.
Я покажу вам этот пример с третьей частью серии.
3) JPA L2 Cache с кешем, поддерживаемым JPA
Конфигурация Grid Entity должна использоваться приложениями, которым требуется быстрый доступ к большим объемам довольно стабильных данных и которые выполняют относительно небольшое количество обновлений. В сочетании с Coherence в качестве кэша L2, использующего обратную запись, для улучшения времени отклика приложения путем асинхронного обновления базы данных. Операции чтения получают объекты из кэша Coherence. Операции записи помещают объекты в кэш Coherence, настроенный кэш L2 выполняет операции записи в базу данных.
Я покажу вам этот пример с последней частью серии.
Дальнейшее чтение и загрузка:
Справка: высокопроизводительный JPA со GlassFish и Coherence — часть 1 от нашего партнера по JCG Маркуса Эйзела в блоге «Разработка корпоративного программного обеспечения на Java»
- Высокопроизводительный JPA с GlassFish и Coherence — Часть 2
- Высокопроизводительный JPA с GlassFish и Coherence — Часть 3
- Разработка и тестирование в облаке
- Управление конфигурацией в Java EE
- Утечка: Oracle WebLogic Server 12g
- Декораторы Java EE6: декорирование классов во время внедрения
- Список учебных пособий по Java и Android