Аннотация
Изучая, как создать высокодоступный (HA), многоканальный кластер Payara / GlassFish с репликацией сеанса, я обнаружил, что не могу найти все, что мне нужно, в одной ссылке. Я предполагал, что это будет общая потребность, и ее легко найти. К сожалению, мое предположение было неверным. Таким образом, цель этого поста — дать полный сквозной пример высокой доступности (HA), репликации сеансов, мультимашинной кластеризации Payara. Но я также говорю (почти), потому что, как и с любой технологией, я уверен, что есть и другие способы сделать это. Способ, описанный в этом посте, взят из моего исследования.
Требования
Я сделал всю работу для этого поста, используя следующие основные технологии. Вы можете сделать то же самое с разными технологиями или версиями, но без гарантий.
- Java SE 8 — OpenJDK 1.8.0_91
- Java EE 7 — Payara 4.1.1.163
- VirtualBox 5.1.6
- Лубунту 16.04
- Nginx 1.10.0
- NetBeans 8.2
- Maven 3.0.5 (в комплекте с NetBeans)
Определения
В этом посте следующие слова будут иметь эти конкретные значения. Здесь нет ничего, что требовало бы адвоката, но хорошо бы убедиться, что определения установлены.
Машина : слово «машина» означает нечто, работающее под управлением собственной операционной системы. Это может быть реальное оборудование, такое как ноутбук, настольный компьютер, сервер или Raspberry Pi. Или это может быть виртуальная машина, работающая на чем-то вроде VirtualBox или VMWare. Или это может быть что-то похожее на машину, например контейнер Docker.
Кластер . Кластер — это набор экземпляров GlassFish Server, которые работают вместе как один логический объект. Кластер предоставляет среду выполнения для одного или нескольких приложений Java Platform, Enterprise Edition (Java EE) (Администрирование серверных кластеров GlassFish, nd)
Узел кластера. Узел кластера представляет собой узел, на котором установлено программное обеспечение GlassFish Server. Узел должен существовать для каждого хоста, на котором находятся экземпляры GlassFish Server (Администрирование серверных узлов GlassFish, nd)
Экземпляр узла кластера. Экземпляр сервера GlassFish — это отдельная виртуальная машина для платформы Java (виртуальная машина Java или машина JVM) на одном узле, на котором работает сервер GlassFish. Машина JVM должна быть совместима с платформой Java Enterprise Edition (Java EE). (Администрирование экземпляров сервера GlassFish, nd)
Архитектура
Поскольку этот пост описывает кластер Payara на нескольких компьютерах, важно знать, какую роль каждая машина будет играть в кластере. Не стоит начинать установку программного обеспечения на нескольких машинах без плана. Этот раздел даст обзор:
- Диаграмма архитектуры
- Роли машины
- Конфигурация сети машины
- Конфигурация пользователя машины
- Установка программного обеспечения машины
Как на самом деле работают машины, не будет рассмотрено в этом посте. Это задача, оставленная на ваше усмотрение. Некоторые варианты: реальное оборудование (Raspberry Pi), виртуальные машины (Virtual Box), контейнеры (Docker) или облако (AWS). Если у вас уже есть машины, запущенные, настроенные и готовые к работе, вы можете пропустить этот раздел и перейти непосредственно к созданию кластера .
Архитектурная схема
На рисунке 1 показана простая диаграмма архитектуры для простого примера приложения, создаваемого для этого поста. Но даже если это просто , важно иметь. Это предотвращает случайную установку программного обеспечения на машины, пока вы не «сделаете это правильно». Кроме того, важное слово, используемое здесь, просто . Эта архитектура содержит минимальные части, необходимые для этого примера; это ни в коем случае не является всеобъемлющим или готовым к производству. Итак, с учетом этого, следующее, что нужно сделать, — рассмотреть детали этой архитектуры более подробно.
Рисунок 1 — Диаграмма «Зона S»
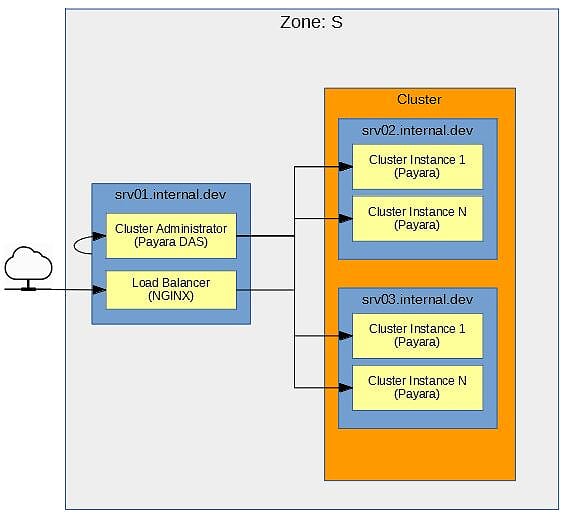
Зона: S Всем машинам в сети должна быть назначена зона. Зона группирует машины, выполняющие аналогичную функцию, а также определяет, как машины между зонами взаимодействуют друг с другом. Этот пример показывает Zone S Эта зона предназначена для машин, поддерживающих сервисы приложений.
srv [N] .internal.dev Синие прямоугольники обозначают машины в зоне. У каждой машины в зоне должна быть четко определенная роль, и лучше не давать машине брать слишком много ролей. Машины для этой зоны называются srv[N].internal.dev . srv указывает, что машина является частью обслуживающей машины Zone S [N] однозначно идентифицирует машину. Наконец, домен .internal.dev указывает, что это машина, доступ к которой осуществляется изнутри в среде разработки . Роль каждой машины описана в разделе « Роли машин ».
Кластер Оранжевый прямоугольник представляет кластер внутри зоны. Кластер будет построен с Payara. Все машины, участвующие в кластере, должны быть представлены в рамке.
Администратор кластера, Экземпляр кластера, Балансировщик нагрузки Желтые прямоугольники показывают, что работает на машине. Роль машины определяет, что на ней работает. Далее вы можете посмотреть на роли машин.
Роли машины
Итак, что работает на каждой машине в Zone S ? Возвращаясь к рисунку 1, роли машины выглядят следующим образом:
-
srv01.internal.devэтой машины две роли. Первая роль — Payara DAS для администрирования кластера. DAS строго разработан и предназначен только для внутреннего использования. Он не должен быть доступен за пределами зоны. Кроме того, как и DAS, приложения Java EE не должны быть развернуты на нем. Вторая роль — это балансировщик нагрузки NGINX. Балансировщик нагрузки является точкой входа вZone Sкогда приложениям требуется доступ к службам, развернутым в кластере в этой зоне. -
srv02.internal.devЭтот компьютер является узлом в кластере Payara. Как показано, узел содержит 2 экземпляра. -
srv03.internal.devЭтот компьютер является узлом в кластере Payara. Как показано, узел содержит 2 экземпляра.
Теперь, когда становится понятной роль каждой машины, следует обратить внимание на связь между машинами.
Конфигурация сети машины
Имена srv01 , srv02 и srv03 будут краткими именами компьютеров. Содержимое /etc/hostname на каждой машине будет иметь это имя. Вот имя хоста для srv01 :
|
1
2
|
$ cat /etc/hostname srv01 |
.internal.dev является доменом для этих машин. Машины должны иметь возможность общаться друг с другом либо по короткому имени хоста, либо по полному имени хоста.
ПРИМЕЧАНИЕ. Этот домен —
.internal.dev— будет важен позже для правильной настройки WAR для репликации сеанса высокой доступности в кластере.
Самый простой способ сделать это — через /etc/hosts . Сконфигурируйте /etc/hosts (на всех машинах в зоне), чтобы он содержал как короткие имена хостов, так и полные имена хостов.
|
1
2
3
4
5
|
$ cat /etc/hosts127.0.0.1 localhost10.0.2.16 srv01.internal.dev srv0110.0.2.17 srv02.internal.dev srv0210.0.2.18 srv03.internal.dev srv03 |
Простой ssh тест следует использовать для проверки связи между всеми машинами. Не пропустите эту проверку. Payara будет использовать SSH для связи, поэтому лучше проверить и устранить неполадки сейчас, прежде чем Payara попытается его использовать. Я оставлю детали для выполнения этого теста для вас.
Теперь, когда все машины могут взаимодействовать друг с другом, следует обратить внимание на учетные записи пользователей Linux на этих машинах. Не слишком увлекательно, но очень важно.
Конфигурация пользователя машины
Каждой машине понадобится пользователь payara с домашним каталогом в /home/payara . Пользователь payara используется для запуска Payara. Ничто не должно быть запущено от имени root . Достаточно просто.
Теперь, когда вы освоили основы конфигурации компьютера, пришло время приступить к созданию кластера Payara.
Создание кластера
Payara позволяет легко создать кластер. При использовании отдельных машин (стихи типичные примеры, которые используют одну и ту же машину для всего), есть несколько дополнительных шагов. Этот раздел даст обзор:
- Установка Payara
- Запуск домена Payara
- Конфигурация безопасности Payara DAS
- Проверка сети Payara
- Создание кластера
- Создание узла кластера
- Создание экземпляра узла кластера
- Запуск кластера
- Кластерная многоадресная проверка
Этот раздел строго посвящен созданию и настройке кластера. Это означает, что после прочтения этого раздела у вас будет кластер, но это не значит, что ваше приложение готово к высокой доступности и репликации сеанса. Конфигурация WAR будет обсуждаться в следующем разделе. Пришло время начать кластер.
Установка Payara
Установка Payara — это не что иное, как загрузка ZIP-файла и его разархивирование. Конечно, зайдите в Payara и найдите страницу загрузки. Этот пост использовал Payara 4.1.1.163. Пришло время установить Payara на все машины в зоне.
- Загрузить Payara 4.1.1.163
- Распакуйте Payara в
/home/payara. Это создаст/home/payara/payara41. - Создайте символическую ссылку
$ln -s payara41 active - Поместите каталоги Payara
binв$PATHпользователей Linuxpayara. Добавьте следующую строку в/home/payara/.bashrc:
|
1
|
export PATH=/home/payara/active/bin:/home/payara/active/glassfish/bin:$PATH |
Готово! Достаточно просто. Далее посмотрите, может ли домен Payara запускаться.
Запуск домена Payara
Используйте инструмент asadmin для запуска домена Payara. Выполните следующую команду на srv01.internal.dev .
|
1
|
payara$ asadmin start-domain domain1 |
Если все пойдет хорошо, домен запустится. Убедитесь, что он работает и работает, перейдя по адресу http: // localhost: 4848 . Конфигурация Payara по умолчанию не имеет имени пользователя / пароля, защищающего DAS, поэтому вы должны сразу войти в него. Теперь, когда DAS работает, следующее, что нужно сделать, — это некоторая настройка безопасности.
Конфигурация безопасности Payara DAS
Теперь пришло время настроить некоторую безопасность, необходимую для связи между компьютерами в кластере. Все эти команды выполняются в srv01.internal.dev .
ПРИМЕЧАНИЕ. Все эти настройки также можно выполнить с помощью приложения администратора Payara с графическим интерфейсом http: // localhost: 4848, но это неинтересно! Командная строка очень интересна и, надеюсь, позволяет автоматизировать.
Пароль asadmin asadmin пароль Payara asadmin по умолчанию. При первом выполнении этой команды помните, что Payara не имеет имени пользователя / пароля по умолчанию, поэтому при запросе пароля оставьте поле пустым. Выполните следующую команду на srv01.internal.dev :
|
1
2
3
4
5
|
payara@srv01$ asadmin change-admin-passwordEnter admin user name [default: admin]>adminEnter the admin password> // Keep this blank when executing this for the first timeEnter the new admin password> // Create a new passwordEnter the new admin password again> // Enter new password again |
Перезапустите домен, чтобы убедиться, что изменения подобраны. Выполните следующую команду на srv01.internal.dev :
|
1
|
payara@srv01$ asadmin restart-domain domain1 |
Теперь проверьте имя пользователя / пароль, используя asadmin для входа в DAS. Следующая команда войдет в DAS, и после входа в систему команда asadmin может быть выполнена без необходимости asadmin имени пользователя / пароля каждый раз. Это удобство, но, конечно, риск для безопасности. Чтобы войти, выполните следующую команду на srv01.internal.dev :
|
1
2
3
4
5
6
7
|
payara@srv01$ asadmin loginEnter admin user name [Enter to accept default]> adminEnter admin password> *******Login information relevant to admin user name [admin] for host [localhost] and admin port [4848] stored at [/home/payara/.gfclient/pass] successfully. Make sure that this file remains protected. Information stored in this file will be used by administration commands to manage associated domain.Command login executed successfully. |
Безопасный администратор Теперь вы хотите включить безопасную связь внутри кластера. В основном это означает, что Payara DAS будет безопасно взаимодействовать с экземплярами кластера. Этот шаг не нужен, но почти всегда приятно иметь. Выполните следующую команду на srv01.internal.dev :
|
1
|
payara@srv01$ asadmin enable-secure-admin |
Перезапустите домен, чтобы убедиться, что изменения подобраны. Выполните следующую команду на srv01.internal.dev :
|
1
|
payara@srv01$ asadmin restart-domain domain1 |
Вот и все для настройки безопасности. Следующее, что нужно сделать, это проверить связь между компьютерами в Зоне и DAS, прежде чем пытаться начать создание кластера.
Payara DAS Проверка связи
Постарайтесь не пропустить этот шаг. Большинство хочет получить право на создание кластера и пропустить этапы проверки. Это может сэкономить немного времени, но, если что-то не работает должным образом, проще устранить проблему на этапе проверки. До сих пор вся работа по запуску и настройке DAS была на srv01 . Теперь убедитесь, что машины srv02 и srv03 могут взаимодействовать с DAS на srv01 .
Выполните следующее на srv02.internal.dev и проверьте результат, как показано.
|
1
2
3
4
5
6
|
payara@srv02$ asadmin --host srv01 --port 4848 list-configsEnter admin user name> adminEnter admin password for user "admin"> server-configdefault-configCommand list-configs executed successfully. |
Выполните следующее на srv03.internal.dev и проверьте результат, как показано.
|
1
2
3
4
5
6
|
payara@srv03$ asadmin --host srv01 --port 4848 list-configsEnter admin user name> adminEnter admin password for user "admin"> server-configdefault-configCommand list-configs executed successfully. |
Успешное выполнение на srv02 и srv03 проверит, могут ли эти машины успешно взаимодействовать с DAS на srv01 . Теперь, когда это было проверено, пришло время создать кластер.
Создание кластера
Теперь кластер будет создан. Для этого примера кластер будет изобретательно назван c1 . В общем, кластер должен быть назван соответствующим образом, однако c1 будет хорошо работать для этого примера. Выполните следующее на srv01.internal.dev .
|
1
2
|
payara@srv01$ asadmin create-cluster c1Command create-cluster executed successfully. |
Это оно! Довольно анти-климатические да? Кластер есть, но в нем ничего нет. Настало время заполнить кластер узлами. Кластер не очень полезен без узлов.
Создание узла кластера
Узлы кластера будут на машинах srv02 и srv03 . Однако команды для создания узлов выполняются на srv01 . Инструмент asadmin при srv01 на srv01 будет использовать ssh для передачи необходимых файлов в srv02 и srv03 . Для удобства сначала создайте временный файл паролей, чтобы сделать SSH проще.
Файл временного пароля. Напомним, что пользователь Linux payara был создан на каждой из машин. Это обычный пользователь Linux, который запускает Payara, чтобы избежать запуска Payara от имени root . Временный файл паролей содержит незашифрованный пароль пользователя Linux srv02 на srv02 и srv03 . Предполагается, что пароль Linux для пользователя payara одинаков на всех машинах. Если это не так, то файл временного пароля необходимо будет обновить, payara правильный пароль для пользователя payara на компьютере srv[N] прежде чем будет предпринята попытка создать узел на srv[N]
ПРИМЕЧАНИЕ Файлы ключей RSA / DSA также можно использовать. Обратитесь к документации
create-node-sshдля получения дополнительной информации. http://docs.oracle.com/cd/E18930_01/html/821-2433/create-node-ssh-1.html#scrolltoc
Создать узел кластера на srv02 Чтобы создать узел на srv02 , выполните следующую команду на srv01.internal.dev .
|
1
2
3
|
payara@srv01$ echo "AS_ADMIN_SSHPASSWORD=[clear_text_password_of_payara_usr_on_srv02]" > /home/payara/passwordpayara@srv01$ asadmin create-node-ssh --nodehost **srv02.internal.dev** --sshuser payara --passwordfile /home/payara/password srv02-node |
Создать узел кластера на srv03 Чтобы создать узел на srv03 , выполните следующую команду на srv01.internal.dev .
|
1
2
3
|
payara@srv01$ echo "AS_ADMIN_SSHPASSWORD=[clear_text_password_of_payara_usr_on_srv03]" > /home/payara/passwordpayara@srv01$ asadmin create-node-ssh --nodehost **srv03.internal.dev** --sshuser payara --passwordfile /home/payara/password srv03-node |
Удалить файл временного пароля После того, как все узлы созданы, файл временного пароля больше не нужен. Это может быть удалено в этой точке. Конечно, если в кластер будет добавлено больше машин и потребуется больше узлов, можно легко создать другой файл временных паролей.
|
1
|
Payara@srv01$ rm /home/payara/password |
Итак, теперь у вас есть кластер и узлы. Узлы отличные. Но узлы не могут ничего сделать без экземпляров. Это экземпляры на узлах, которые могут запускать приложения; это фактический экземпляр Payara. Итак, пришло время сделать несколько экземпляров узлов кластера.
Создание экземпляра узла кластера
Создание экземпляра узла в основном создает экземпляры Payara на узлах. Узел может иметь много экземпляров на нем. Все зависит от ресурсов машины. Экземпляры узла будут созданы в узлах srv02 и srv03 . Однако команды для создания экземпляров узла выполняются на srv01 . Инструмент asadmin при srv01 на srv01 создаст экземпляры узлов на srv02 и srv03 .
Создание экземпляров узлов в srv02 Создание 2 экземпляров узлов в srv02 . Экземпляры узла будут называться srv02-instance-01 и srv02-instance-02 . Выполните следующую команду на srv01.internal.dev :
|
1
2
3
4
5
6
7
|
payara@srv01&$ asadmin create-instance --cluster c1 --node srv02-node srv02-instance-01Command _create-instance-filesystem executed successfully.Port Assignments for server instance srv02-instance-01: .....The instance, srv02-instance-01, was created on host srv02Command create-instance executed successfully. |
|
1
2
3
4
5
6
7
|
payara@srv01$ asadmin create-instance --cluster c1 --node srv02-node srv02-instance-02Command _create-instance-filesystem executed successfully.Port Assignments for server instance srv02-instance-02: .....The instance, srv02-instance-02, was created on host srv02Command create-instance executed successfully. |
Если после выполнения этих команд в консоль выводится сообщение «Команда create-instance успешно выполнена», то вполне вероятно, что все работает нормально. Тем не менее, вы должны проверить, чтобы быть уверенным. Процесс проверки выполняется на srv02 и srv03 . Успешная проверка означает поиск каталога /nodes . Выполните следующее на srv02.internal.dev .
|
1
2
3
|
payara@srv02$ cd /home/payara/active/glassfishpayara@srv02$ lsbin common config domains legal lib modules nodes osgi |
Создание экземпляров узлов в srv03 Создание 2 экземпляров узлов в srv03 . Делайте все точно так же, как в предыдущем заголовке, но используйте srv03 вместо srv02 .
Сейчас есть 4 экземпляра Payara …
-
srv02-instance-01 -
srv02-instance-02 -
srv03-instance-01 -
srv03-instance-02
распределить по 2 узлам …
-
srv02-node -
srv03-node
на 2х разных машинах…
-
srv02 -
srv03
на 1 логическом кластере Payara
-
c1
Теперь начните все!
Запуск кластера
Запуск кластера c1 действительно очень прост. Это делается с компьютера srv01 и, когда DAS запускает все экземпляры кластера, следите за консолью, чтобы убедиться, что все 4 запущены. Выполните следующую команду на srv01.internal.dev .
|
1
2
3
|
payara@srv01$ asadmin start-cluster c10%: start-cluster: Executing start-instance on 4 instances.Command start-cluster executed successfully. |
После запуска кластера убедитесь, что он работает, перечислив работающие кластеры в DAS. Также убедитесь, что экземпляры узла работают, перечислив экземпляры в DAS. Выполните следующие команды на srv01.internal.dev .
|
1
2
3
|
payara@srv01$ asadmin list-clustersc1 runningCommand list-clusters executed successfully. |
|
1
2
3
4
5
6
|
payara@srv01$ asadmin list-instancessrv02-instance-01 runningsrv02-instance-02 runningsrv03-instance-01 runningsrv03-instance-02 runningCommand list-instances executed successfully. |
Поздравляем! Теперь у вас есть небольшой кластер из 4 экземпляров. Теперь пришло время развертывать приложения, верно? Неправильно! Перед развертыванием приложений важно убедиться, что многоадресная сетевая связь между узлами является рабочим свойством, чтобы позволить репликации HttpSession в кластере. Проверьте многоадресную сетевую связь затем.
Многоадресная проверка кластера
Суть кластера в том, чтобы иметь приложение с высокой доступностью, реплицируемое в сеанс. Если у одного экземпляра есть проблема, другой экземпляр в кластере (возможно, на другом узле) вступит во владение без проблем. Но для того, чтобы это действительно произошло, экземпляры кластера должны иметь возможность успешно взаимодействовать друг с другом. У Payara есть инструмент validate-multicast , чтобы проверить это. Однако хитрость заключается в том, как запустить validate-multicast . Для успешного запуска validate-multicast необходимо запустить на ОБА srv02 и srv03 ОДНОВРЕМЕННО ! Выполните следующее в srv02.internal.dev И srv03.internal.dev же время (Hafner, 2011)!
srv02.internal.dev Выполните следующее для srv02.internal.dev :
|
01
02
03
04
05
06
07
08
09
10
11
12
|
payara@srv02$ asadmin validate-multicastWill use port 2048Will use address 228.9.3.1Will use bind interface nullWill use wait period 2,000 (in milliseconds)Listening for data...Sending message with content "srv02" every 2,000 millisecondsReceived data from srv02 (loopback)Received data from srv03Exiting after 20 seconds. To change this timeout, use the --timeout command line option.Command validate-multicast executed successfully. |
srv03.internal.dev Одновременно с srv02.internal.dev также выполните следующую srv03.internal.dev :
|
01
02
03
04
05
06
07
08
09
10
11
12
|
payara@srv03$ asadmin validate-multicastWill use port 2048Will use address 228.9.3.1Will use bind interface nullWill use wait period 2,000 (in milliseconds)Listening for data...Sending message with content "srv03" every 2,000 millisecondsReceived data from srv03 (loopback)Received data from srv02Exiting after 20 seconds. To change this timeout, use the --timeout command line option.Command validate-multicast executed successfully. |
При выполнении обеих этих команд в то же время связь между экземплярами должна быть успешной. На машине srv02 вы должны увидеть «Полученные данные от srv03», а на машине srv03 вы должны увидеть «Полученные данные от srv02». Это подтверждает, что многоадресная сетевая связь, используемая между экземплярами узла для репликации HttpSession работает правильно.
Ну вот и все! Кластер теперь полностью настроен и работает на нескольких машинах. Я уверен, что вам не терпится развернуть свое приложение в кластере. Итак, погрузитесь и посмотрите, как настроить WAR-файл для среды высокой доступности (репликация сеанса).
Конфигурация WAR
Как только кластер Payara настроен и запущен, большинство полагает, что любое приложение, развернутое в кластере, получит преимущества высокой доступности (HA) кластера и репликации сеанса. К сожалению, это не так. Ваше приложение должно быть разработано и настроено для кластера. Этот раздел даст обзор:
- Сериализация HttpSession
- web.xml <распространяемый />
- glassfish-web.xml cookieDomain
ПРИМЕЧАНИЕ. Все эти конфигурации необходимы. Если пропустить только 1, репликация сеанса в кластере не будет работать.
Первое, что нужно для вашего приложения — это сериализация сеансов. Это будет рассмотрено очень кратко в следующем.
Сериализация сессии
Сериализация HttpSession — это простая вещь, но на которую большинство команд разработчиков обращают очень мало внимания. Как правило, серверы приложений используют сериализацию для репликации сеансов в кластере. Если объекты в HttpSession не могут быть сериализованы, репликация сеанса не будет выполнена. Поэтому убедитесь, что ВСЕ объекты, помещенные в HttpSession , могут быть сериализованы.
Сериализация сеанса является критической конфигурацией. Если он пропущен, репликация сеанса в кластере не будет работать.
ПРИМЕЧАНИЕ. В среде разработки запустите приложение с помощью
javax.servlet.Filterкоторый пытается сериализовать все объекты вHttpSession. Если вы проводите адекватное тестирование, это должно выявить любые проблемы с сериализацией.
Теперь, когда все объекты в HttpSession могут быть сериализованы, следующая вещь, на которую нужно обратить внимание, — это конфигурация web.xml .
web.xml <распространяемый />
На странице 157 спецификации Servlet 3.1 элемент <distribtable /> для web.xml как «<distribtable /> указывает, что это веб-приложение запрограммировано надлежащим образом для развертывания в контейнере распределенного сервлета». Это означает, что <распространяемый /> должен быть добавлен в web.xml чтобы Payara знала, что приложение будет работать в кластере и должна обрабатываться как таковая. В листинге 1 приведен пример.
Листинг 1 — Распространяемый
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
<?xml version="1.0" encoding="UTF-8"?> xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd" version="3.1"> <display-name>clusterjsp</display-name> <distributable/> <servlet> <display-name>HaJsp</display-name> <servlet-name>HaJsp</servlet-name> <jsp-file>/HaJsp.jsp</jsp-file> </servlet> <servlet> <display-name>ClearSession</display-name> <servlet-name>ClearSession</servlet-name> <jsp-file>/ClearSession.jsp</jsp-file> </servlet> <session-config> <session-timeout>30</session-timeout> </session-config> <welcome-file-list> <welcome-file>HaJsp.jsp</welcome-file> </welcome-file-list></web-app> |
Элемент <distribtable /> является критической конфигурацией. Если он отсутствует, репликация сеанса в кластере не будет работать.
Элемент <distribtable /> — это конфигурация, необходимая для всех серверов Java EE. Payara также имеет некоторые собственные настройки. Следующая вещь, на которую стоит обратить внимание, это конфигурация, специфичная для сервера.
glassfish-web.xml cookieDomain
Файл glassfish-web.xml является файлом конфигурации, специфичным для Payara, для веб-приложения. В отличие от web.xml который применим ко всем серверам Java EE, glassfish-web.xml работает только для серверов GlassFish или Payara EE. Это означает, что при развертывании на другом сервере EE вам может понадобиться или не потребоваться найти эквивалентную конфигурацию для этого сервера.
Для Payara необходимо добавить glassfish-web.xml , чтобы добавить свойство cookieDomain . В листинге 2 показана иерархия тегов для правильной установки значения cookieDomain . Как видно из листинга 2, значение установлено на .internal.dev (Hafner, 2011). Если вы помните, это домен, который вы используете для кластерной архитектуры.
Листинг 2 — cookieDomain
|
1
2
3
4
5
6
7
8
9
|
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE glassfish-web-app PUBLIC "-//GlassFish.org//DTD GlassFish Application Server 3.1 Servlet 3.0//EN" "http://glassfish.org/dtds/glassfish-web-app_3_0-1.dtd"><glassfish-web-app error-url=""> <session-config> **<cookie-properties> <property name="cookieDomain" value=".internal.dev"/> </cookie-properties>** </session-config></glassfish-web-app> |
Эта конфигурация свойства cookieDomain важна, потому что она позволяет куки-файлу JSESSIONID, который используется для отслеживания сеанса пользователя между экземплярами узла кластера, передаваться любому экземпляру узла кластера при каждом запросе веб-браузера. Самый простой способ увидеть, что здесь происходит, — это объяснить, что происходит, если отсутствует конфигурация свойства cookieDomain .
ПРИМЕЧАНИЕ Это небольшой предварительный просмотр того, что должно произойти, но это нормально.
Предположим, отсутствует конфигурация свойства cookieDomain . Затем веб-браузер отправляет запрос приложению, запущенному на одном из экземпляров узла кластера, с URL-адресом http://srv02.internal.dev:28080/ferris-clusterjsp . Когда приложение обрабатывает запрос, оно создает файл cookie JSESSIONID, и значением домена этого файла cookie (по умолчанию) будет имя хоста, используемое для доступа к приложению, в данном случае srv02.internal.dev . Теперь еще один запрос к URL http://srv03.internal.dev:28080/ferris-clusterjsp . Это экземпляр кластера, поэтому можно ожидать, что этот экземпляр найдет сеанс, который уже был создан. Но этого не произойдет. Это не произойдет, потому что файл cookie JSESSIONID был создан со значением домена **srv02**.internal.dev поэтому веб-браузер не будет отправлять этот файл cookie по запросу http://**srv03**.internal.dev потому что cookie принадлежит srv02 а не srv03 .
Теперь предположим, что конфигурация свойства cookieDomain настроена так, как показано в листинге 2. Что происходит сейчас? Итак, веб-браузер отправляет запрос приложению, запущенному на одном из экземпляров узла кластера, с помощью URL http://srv02.internal.dev:28080/ferris-clusterjsp . Однако на этот раз, когда приложение обрабатывает запрос, оно создаст файл cookie JSESSIONID, а значением домена этого файла cookie будет домен, который вы настроили в листинге 2, — .internal.dev . Теперь еще один запрос к URL http://srv03.internal.dev:28080/ferris-clusterjsp . Веб-браузер отправит JSESSIONID вместе с этим запросом, поскольку файл cookie принадлежит .internal.dev а запрос отправляется по http://srv03**.internal.dev** .
Свойство cookieDomain является критической конфигурацией. Если он отсутствует или если используемый вами домен не соответствует значению cookieDomain , то репликация сеанса в кластере не будет работать.
Поздравляю. Ваше веб-приложение настроено и готово к развертыванию в кластере. Развертывание легко сделать, и вы будете делать это дальше.
Развертывание WAR
На этом этапе вы, наконец, готовы развернуть свою WAR. Ну, не совсем. У тебя есть ВОЙНА? Нет? Ну, тебе повезло. Приложение clusterjsp популярно для тестирования кластеров и репликации сеансов. У меня есть собственный форк clusterjsp в моей учетной записи GitHub, который уже настроен и готов к развертыванию в этом примере кластера. Вы можете скачать мой форк clusterjsp по адресу https://github.com/mjremijan/ferris-clusterjsp/releases . В этом разделе вы увидите:
- Команда
asadmin deployPayaraasadmin deploy - Проверка правильности развертывания приложения в кластере.
Команда развертывания
Сначала вы должны загрузить ferris-clusterjsp-1.1.0.0.war из моей учетной записи GitHub. Затем asadmin его в кластере с помощью команды asadmin . Выполните следующее на srv01.internal.dev :
|
1
2
3
4
|
$ asadmin deploy --force true --precompilejsp=true --enabled=true --availabilityenabled=true --asyncreplication=true --target c1 --contextroot=ferris-clusterjsp --name=ferris-clusterjsp:1.1.0.0 ferris-clusterjsp-1.1.0.0.warApplication deployed with name ferris-clusterjsp:1.1.0.0.Command deploy executed successfully. |
–Force true Вызывает повторное развертывание веб-приложения, даже если оно уже развернуто.
–Precompilejsp = true Приложение ferris-clusterjsp использует несколько простых файлов JSP, поэтому их необходимо предварительно скомпилировать при развертывании.
–Enabled = true Разрешает доступ к приложению после его развертывания.
–Availabilityenabled = true Обеспечивает высокую доступность благодаря репликации и пассивации сеанса. Применяется также к сессионным компонентам с сохранением состояния, хотя обычно они больше не используются.
–Asyncreplication = true. Выполнять репликацию сеанса в кластере в отдельном асинхронном потоке по сравнению с потоком, обрабатывающим запрос пользователя.
–Target c1 Развернуть приложение в кластере c1
–Contextroot = ferris-clusterjsp Установить корневой каталог приложения для ferris-clusterjsp . Это также можно определить в glassfish-web.xml .
–Name = ferris-clusterjsp: 1.1.0.0 Задайте отображаемое имя приложения в том виде, в котором оно отображается в консоли администратора Payara. Как правило, это хорошая идея, чтобы включить номер версии в отображаемое имя.
ferris-clusterjsp – 1.1.0.0.war Имя файла WAR для развертывания.
Теперь, когда WAR развернут, необходимо проверить, что приложение было успешно развернуто и работает на всех экземплярах узла кластера.
Развертывание проверки
Когда вы выполните asadmin deploy выше команду asadmin deploy , через короткое время вы должны увидеть сообщение «Command deploy execute execute execute». Если так, то это хорошо! Приложение было успешно развернуто в кластере. Чтобы убедиться, что он был успешно развернут, выполните на srv01.internal.dev следующее:
|
1
2
3
4
5
|
$ asadmin list-applications --long true --type web c1NAME TYPE STATUS ferris-clusterjsp:1.1.0.0 <web> enabled Command list-applications executed successfully. |
Эта команда asadmin просит Payara перечислить все приложения типа web в кластере c1 . Результат должен быть 1, приложение ferris-clusterjsp: 1.1.0.0 и его статус должны быть включены . И просто чтобы убедиться, что все в порядке, посмотрите на состояние экземпляров узла, выполнив следующее на srv01.internal.dev .
|
1
2
3
4
5
6
|
$ asadmin list-instances c1srv02-instance-01 running srv02-instance-02 running srv03-instance-01 running srv03-instance-02 running |
Эта команда asadmin сообщает, что в кластере c1 есть 4 экземпляра, и все 4 экземпляра работают. Приложение ferris-clusterjsp успешно работает в кластере. Следующее, что нужно сделать, это проверить это!
Тестирование репликации сеанса WAR
Настало время проверить, работает ли репликация сеанса в кластере. Это не сложно, однако вам нужно покинуть мир командной строки и начать работать с браузером. Чтобы тестирование репликации сеанса работало правильно, вам необходимо:
- Определите URL-адреса ссылок для каждого отдельного экземпляра узла кластера, на котором выполняется приложение.
- Используйте веб-браузер, чтобы посетить каждую ссылку.
Ссылки на каждый экземпляр
Первое, что вам нужно сделать, это найти URL-адреса для доступа к приложению ferris-clusterjsp на каждом экземпляре узла кластера. Вот как ты это делаешь. Приложение ferris-clusterjsp работает на 4 экземплярах узлов кластера, и каждый экземпляр имеет свой собственный URL. Получить список ссылок, выполнив следующие действия:
- Откройте веб-браузер на
srv01.internal.dev. - Перейдите в консоль администратора Payara по адресу
http://localhost:4848. - Логин (помните, что вы изменили пароль администратора в конфигурации безопасности Payara DAS ).
- Нажмите на узел дерева приложений .
После нажатия на узел дерева приложений вы увидите приложение ferris-clusterjsp: 1.1.0.0. На рисунке 2 показано, что в столбце Action таблицы есть гиперссылка с именем Launch . Нажмите это!
Рисунок 2 — ссылка Launch
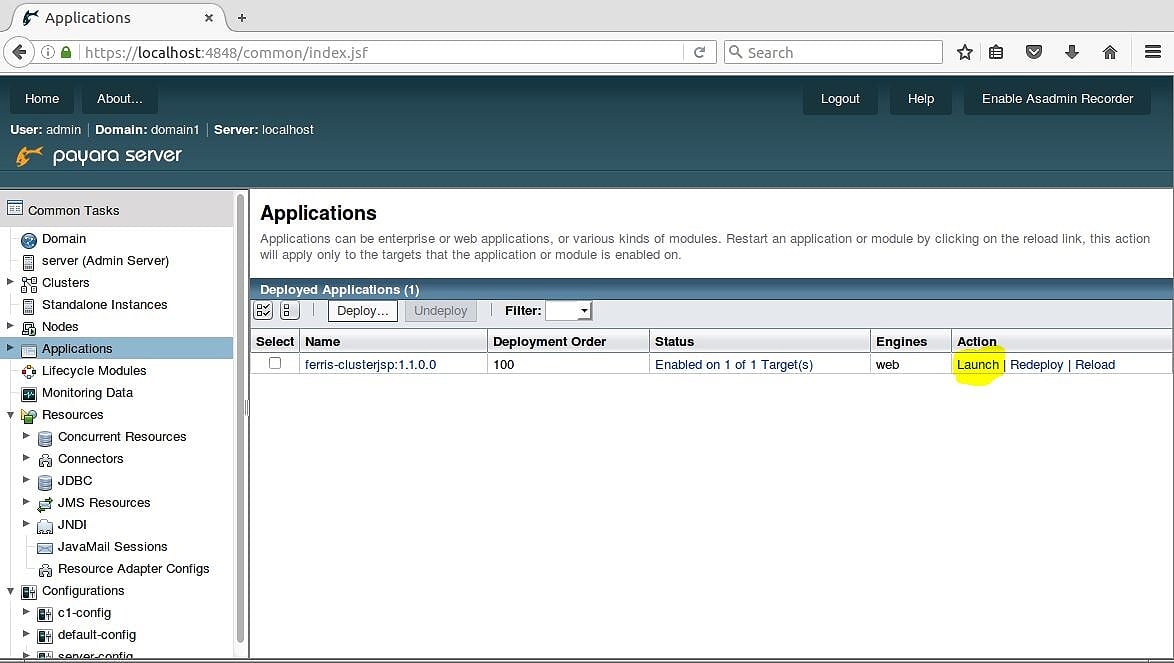
Launch link
После нажатия на ссылку Launch появится новое окно браузера со всеми ссылками на приложение в кластере. На рисунке 3 показано 8 ссылок. Каждый из 4 экземпляров узла кластера доступен по HTTP или HTTPS.
Рисунок 3 — Все ссылки
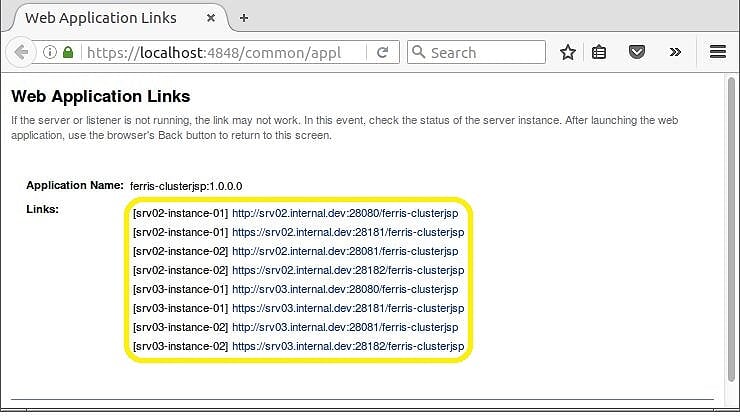
Теперь, когда вы знаете все ссылки, вы можете получить прямой доступ к приложению ferris-clusterjsp в каждом из 4 экземпляров. Это позволит вам проверить, работает ли репликация сеанса. Если ваш первый запрос к экземпляру srv02-instance – 01 , вы сможете увидеть сеанс в любом из 3 других экземпляров. Надеюсь, это сработает!
Тестирование репликации
Чтобы проверить, работает ли репликация сеанса, все, что вам нужно сделать, — это получить доступ к приложению на одном из экземпляров узла кластера, записать значение идентификатора сеанса, затем получить доступ к приложению на другом экземпляре узла и посмотреть, реплицировался ли ваш сеанс. Начните сначала с srv02-instance – 01 . Откройте веб-браузер и перейдите по http://srv02.internal.dev:28080/ferris-clusterjsp . Приложение покажет информацию об экземпляре узла кластера и о вашем сеансе. Ваш браузер будет похож на рисунок 4а.
Рисунок 4a — ferris-custerjsp на srv02-instance – 01
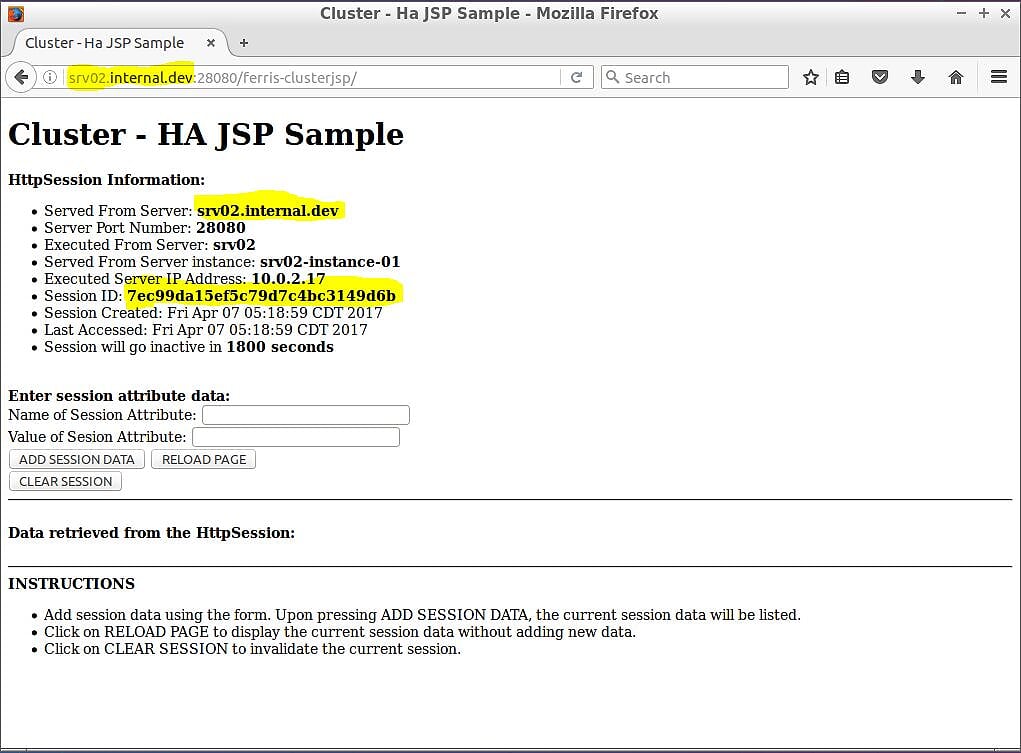
На рис. 4, а показаны несколько фрагментов информации, которые вам понадобятся, чтобы подтвердить, что репликация сеанса работает. Во-первых, URL-адрес веб-браузера: http://srv02.internal.dev:28080/ferris-clusterjsp а имя хоста URL-адреса соответствует информации, полученной с сервера на странице. Кроме того, на странице отображается созданный для вас идентификатор сеанса — в данном случае 7ec99da15ef5c79d7c4bc3149d6b .
Теперь у вас есть сеанс в приложении, и, если все работает, этот сеанс должен быть реплицирован по всему кластеру. Единственное, что осталось сделать, чтобы проверить это, это выбрать другой экземпляр узла кластера и посмотреть, получите ли вы тот же сеанс. Выберите srv03-instance – 02, чтобы проверить следующее. Этот экземпляр узла кластера не только находится на совершенно другой физической машине, но также переключает протокол с HTTP на HTTPS. Откройте веб-браузер и перейдите по https://srv03.internal.dev:28182/ferris-clusterjsp . Рисунок 4b показывает, что должно произойти.
Рисунок 4b — ferris-custerjsp на srv03-instance – 02
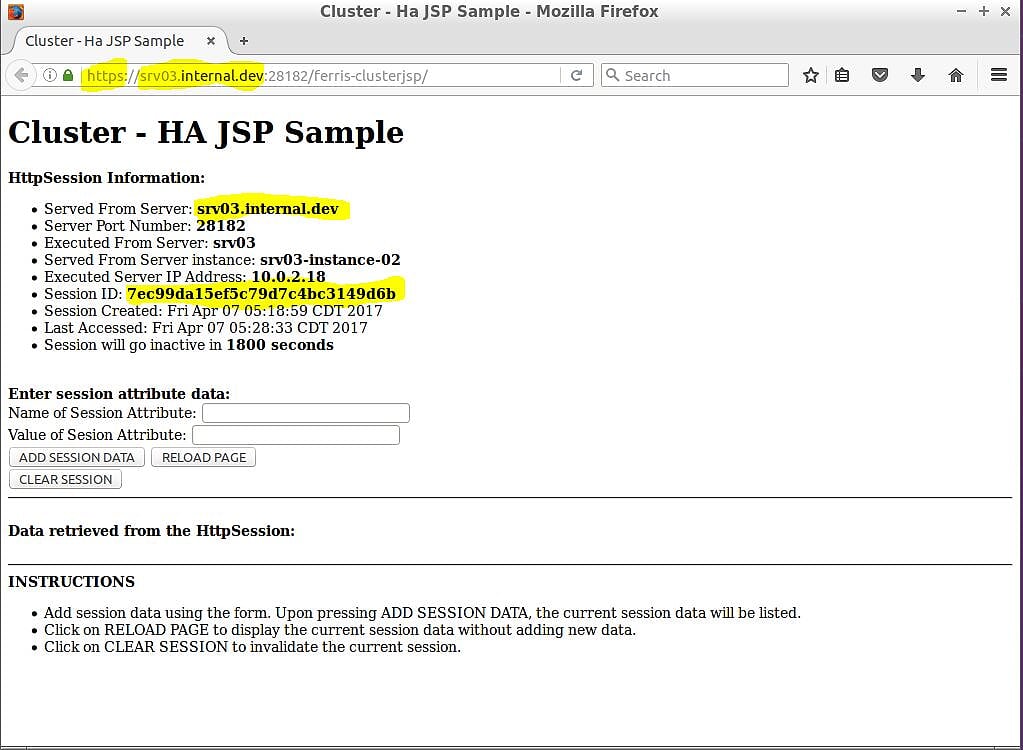
На рисунке 4b показаны результаты, и они выглядят действительно хорошо! Выделено, что вы можете увидеть переход с HTTP на HTTPS (ваш веб-браузер должен был также заставить вас принять сертификат).URL-адрес веб-браузера https://srv03.internal.dev:28182/ferris-clusterjspи имя хоста URL-адреса совпадают с информацией, полученной с сервера на странице. Но самое главное, вы получаете тот же идентификатор сеанса — в этом случае 7ec99da15ef5c79d7c4bc3149d6b .
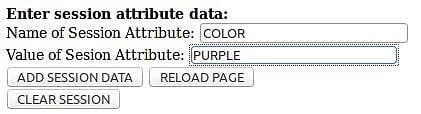
Теперь вы можете немного повеселиться и протестировать репликацию. Используйте страницу, чтобы добавить некоторые данные атрибута сеанса и посмотреть, реплицируются ли они в кластере. Неважно, какой экземпляр узла кластера вы используете первым. Выбери один.Затем перейдите в раздел « Ввод данных атрибута сеанса: страница» и добавьте данные сеанса, как показано на рисунке 5.
Рисунок 5 — Добавление данных атрибута сеанса
Нажмите кнопку ДОБАВИТЬ ДАННЫЕ СЕССИИ . На рисунке 6 показано, что страница обновится, и будут добавлены данные атрибута сеанса.
Рисунок 6 — Добавлены данные атрибута сеанса

После добавления данных атрибута сеанса перейдите в другой браузер и обновите страницу. Вы увидите, что данные были реплицированы. На рисунке 7 показаны веб-браузеры рядом с идентичными реплицированными данными атрибутов сеанса.
Рисунок 7 — Браузеры рядом с теми же данными

Поздравляем!Теперь у вас есть полностью работающий кластер с репликацией сеансов с несколькими виртуальными машинами. Но чего-то еще не хватает: высокая доступность (HA). Для HA вам понадобится балансировщик нагрузки. Итак, следующая вещь, на которую стоит обратить внимание, — это настройка балансировки нагрузки.
Конфигурация балансировщика нагрузки
Прямо сейчас у вас есть отличный кластер с несколькими репликациями виртуальных машин, но он бесполезен, потому что он еще не доступен. У вас есть ссылки для доступа к каждому отдельному экземпляру узла кластера, но наличие URL-адреса для 1 экземпляра не обеспечивает высокую доступность (HA). Теперь вам нужен балансировщик нагрузки, который может отправить запрос на общий URL-адрес, например, http://srv.internal.devи прокси-сервер, который запрашивает любой из активных экземпляров в кластере. И, благодаря успешной настройке репликации сеанса в кластере, не имеет значения, к какому экземпляру балансировщика нагрузки будет применяться ваш запрос, поскольку данные сеанса будут одинаковыми во всем кластере. Для этого поста вы будете использовать NGINX в качестве балансировщика нагрузки. Этот раздел будет смотреть на:
- Установка NGINX
- Конфигурация NGINX
- Тестирование NGINX
Установка NGINX
Установить NGINX просто. Вы должны быть в состоянии использовать, apt-getчтобы сделать это. Выполните следующую команду srv01.internal.dev. Помните на диаграмме архитектуры для зоны, srv01.internal.devэто машина в зоне, которая будет запускать балансировщик нагрузки.
|
1
|
$ apt-get install nginx |
Вот и все.NGINX теперь установлен. Чтобы заставить его работать с вашими экземплярами узла кластера, вам необходимо выполнить небольшую настройку, что вы и будете делать дальше.
Конфигурация NGINX
Эта конфигурация NGINX очень проста. Есть 2 вещи, которые вам нужно сделать. Во-первых, вам нужно настроить восходящую конфигурацию, которая содержит имена хостов и номера портов всех экземпляров узла кластера. Второе — обновить местоположение для запросов прокси к восходящему каналу .
upsteam Во-первых, посмотрите на конфигурацию восходящего потока . Предполагая, что вы установили NGINX srv01.internal.dev, откройте /etc/nginx/nginx.confфайл для редактирования. Отредактируйте файл и добавьте исходную конфигурацию, как показано в следующем примере. Выше по потоку конфигурации проходит внутри HTTP конфигурации.
|
1
2
3
4
5
6
7
8
|
http { upstream cluster_c1 { server srv02.internal.dev:28080; server srv02.internal.dev:28081; server srv03.internal.dev:28080; server srv03.internal.dev:28081; }} |
Перезапустите NGINX, чтобы получить изменения.
|
1
|
$ /etc/init.d/nginx restart |
местоположение Далее, посмотрите на конфигурацию местоположения . Предполагая, что вы установили NGINX srv01.internal.dev, откройте /etc/nginx/sites-available/defaultфайл для редактирования. Отредактируйте файл и обновите конфигурацию местоположения, чтобы СООТВЕТСТВОВАТЬ следующему примеру. Местоположение конфигурация идет внутри сервера конфигурации.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
server { listen 80; server_name localhost; upstream cluster_c1 { location / { root html; index index.html index.htm; proxy_connect_timeout 10; proxy_send_timeout 15; proxy_read_timeout 20; proxy_pass http://cluster_c1; }} |
Перезапустите NGINX, чтобы получить изменения.
|
1
|
$ /etc/init.d/nginx restart |
Тестирование NGINX
По умолчанию NGINX настроен на прослушивание через порт 80. Вы видели это в предыдущем разделе, когда выполняли настройку местоположения . Если и NGINX, и Payara запущены и работают, вот самый простой способ проверить.
- Откройте веб-браузер на
srv01.internal.dev. - Перейти к
http://localhost
Поскольку NGINX настроен как прокси-сервер перед Payara, браузер покажет страницу Payara-is-сейчас работает, как показано на рисунке 8.
Рисунок 8 — Payara с локальным прокси через NGINX
Вот и все.NGINX теперь настроен и работает. Это означает, что у вас есть часть архитектуры высокой доступности (HA), готовая к тестированию. Вы можете сделать это дальше.
ВОЙНА Тестирование высокой доступности (HA)
Теперь ты в доме. Вот все части архитектуры до сих пор:
- Кластер Payara, способный поддерживать репликацию сеанса.
- Приложение написано и настроено на использование репликации сеанса.
- Кластер Payara с несколькими экземплярами узлов.
- Балансировщик нагрузки NGINX, настроенный на прокси-запросы к экземплярам узла кластера.
Теперь пришло время посмотреть, все ли части работают вместе. Для этих финальных тестов вам необходим веб-браузер, способный отправлять запросы через балансировщик нагрузки NGINX. Помните 2 очень важные вещи:
- Балансировщик нагрузки работает
srv01.internal.devна порту 80. - URL, который вы используете, должен заканчиваться
.internal.dev.
Самый простой способ сделать это — отредактировать файл hosts на вашей тестовой машине и добавить хост для тестирования кластера. Предположим, что тестовое имя хоста будет srv.internal.dev. Затем добавьте следующее в файл hosts вашей тестовой машины :
|
1
2
3
4
5
6
|
$ cat /etc/hosts127.0.0.1 localhost10.0.2.16 srv01.internal.dev srv0110.0.2.17 srv02.internal.dev srv0210.0.2.18 srv03.internal.dev srv0310.0.2.16 srv.internal.dev |
Первый тест, который вы должны сделать, это повторить простой тест NGINX. Только на этот раз используйте имя хоста, которое вы только что сохранили в файле hosts . Выполните тест, выполнив следующие действия:
- Откройте веб-браузер на тестовой машине.
- Перейти к
http://srv.internal.dev
Поскольку NGINX настроен в качестве прокси-сервера перед Payara, браузер покажет страницу Payara-is-сейчас работает, как показано на рисунке 9. Разница на этот раз в том, что URL использует имя хоста, сохраненное в файле hosts .
Рисунок 9 — Payara с srv.internal.dev, проксированным через NGINX
Теперь вот последний тест, чтобы убедиться, что все работает. Откройте веб -браузер в приложении ferris-clusterjsp и посмотрите, что произойдет. Выполните тест, выполнив следующие действия:
- Откройте веб-браузер на тестовой машине.
- Перейдите к
http://srv.internal.dev/ferris-clusterjsp.
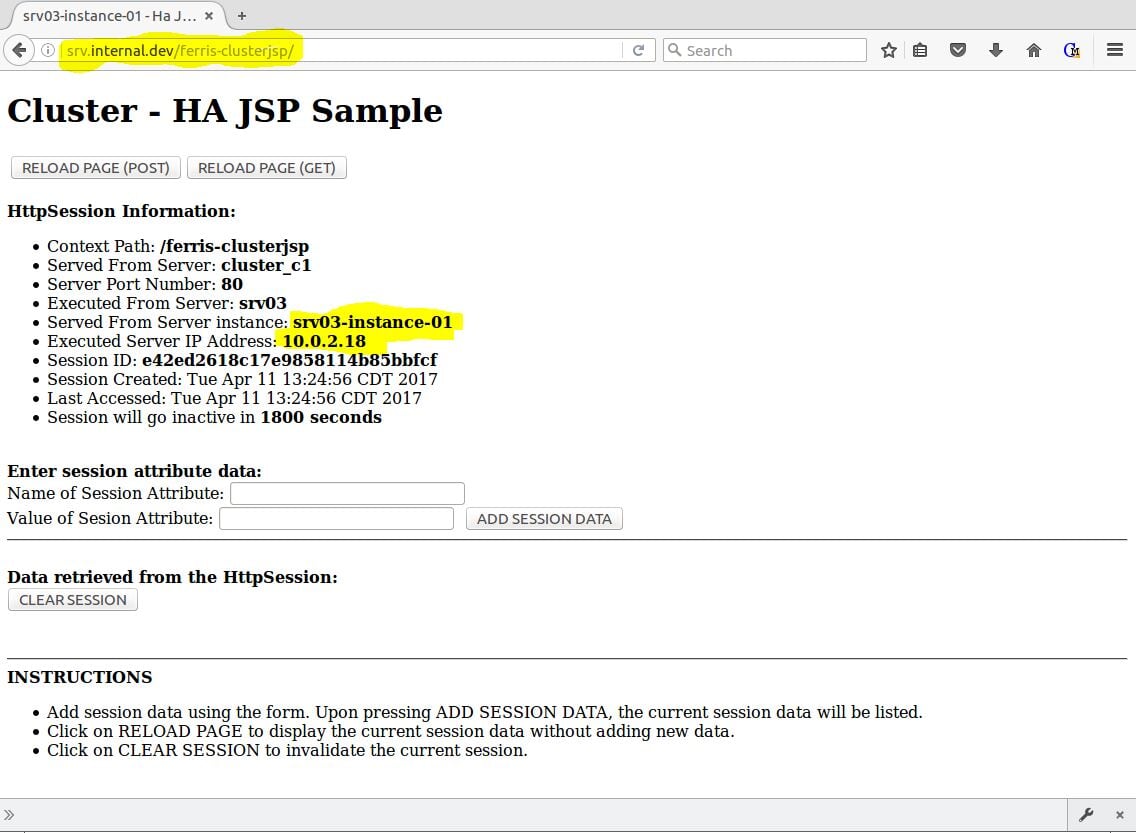
Если все пойдет хорошо, вы увидите страницу примера JSP HA, обработанную одним из экземпляров узла кластера. На рисунке 10 показано, что srv03-instance-01обработан первый запрос.
Рисунок 10 — Payara с прокси-сервером ferris-clusterjsp через NGINX 
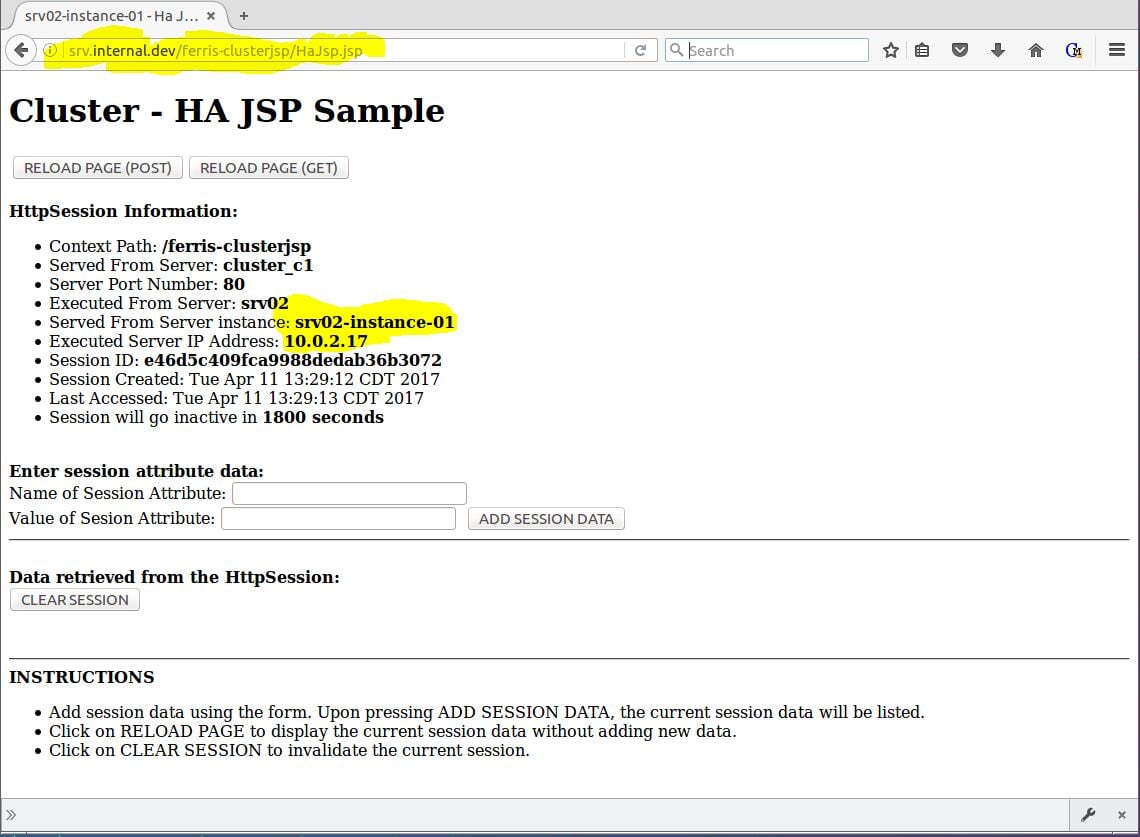
Теперь захватывающая часть. Продолжайте тестирование! Продолжайте перезагружать страницу. Как показано на рисунке 11, вы увидите, что экземпляр Served From Server: и IP-адрес исполняемого сервера: изменится, поскольку балансировщик нагрузки NGINX передает запросы на другие экземпляры узла кластера, но идентификатор сеанса останется прежним. Здорово!
Рисунок 11 — Payara с ferris-clusterjsp, проксированным через NGINX Рисунок 11 — Payara с ferris-clusterjsp, проксированным через NGINX
Теперь для еще более веселого теста. Высокая доступность (HA) означает, что если экземпляр узла кластера выходит из строя, приложение все еще продолжает работать, и на ваших пользователей это не влияет. Попробуй!Завершите работу одного из узлов кластера и посмотрите, что произойдет. Выполните следующую команду srv01.internal.dev:
bash $ asadmin stop-instance srv03-instance-01
Это остановит 1 экземпляр кластера. Теперь вернитесь в браузер и начните перезагружать страницу. Во время перезагрузки следите за экземпляром Served From Server: значение. Поскольку srv03-instance-01теперь он выключен, вы заметите, что этот экземпляр будет пропущен при циклическом переборе балансировки нагрузки через экземпляры кластера. Один экземпляр вашего кластера остановлен, но ваше приложение все еще работает нормально. Если вы хотите запустить экземпляр снова, выполните следующую команду srv01.internal.dev:
|
1
|
$ asadmin start-instance srv03-instance-01 |
Это перезапустит экземпляр. Теперь вернитесь в свой браузер и снова загрузите страницу. Во время перезагрузки следите за экземпляром Served From Server: значение. Вы в конечном итоге заметите srv03-instance-01, вернется! ?
Резюме
Моя цель на этом посте состояла в том, чтобы объединить в одном месте инструкции по созданию многоадресного кластера Payara / GlassFish с высокой степенью доступности (HA), реплицированного в течение сеанса. Надеюсь, я достиг этой цели, дав инструкции для следующего:
- Создание многомашинной архитектуры для кластера
- Установка Payara
- Настройка DAS для кластерной связи
- Создание кластера
- Создание узлов кластера
- Создание экземпляров узла кластера
- Настройка WAR для использования сеанса репликации
- Настройка NGINX для балансировки нагрузки и проксирования.
- Тестирование всего на каждом этапе, чтобы убедиться, что все работает.
Я надеюсь, что вы нашли этот пост полезным.Также обратите внимание, что в заголовке этого поста есть веская причина: «(почти)»: это не единственный способ создания высокодоступного (реплицируемого в сеансе) мультимашированного кластера Payara / GlassFish. Но это способ.
Рекомендации
Спецификация Java Servlet 3.1 (2013 г., 28 мая). Java Servlet 3.1 Спецификация для оценки [PDF]. Получено с http://download.oracle.com/otndocs/jcp/servlet-3_1-fr-eval-spec/index.html
Hafner S. (2011, 12 мая). Glassfish 3.1 — Учебник по кластеризации, часть 2 (сеансы) [запись в веб-журнале]. Получено с https://javadude.wordpress.com/2011/05/12/glassfish-3-1-%E2%80%93-clustering-tutorial-part2-sessions/ .
Hafner S. (2011, 25 апреля). Glassfish 3.1 — Учебное пособие по кластеризации. Получено с https://javadude.wordpress.com/2011/04/25/glassfish-3-1-clustering-tutorial/
Мейсон Р. (2013, 3 сентября). Балансировка нагрузки Apache Tomcat с Nginx. Получено с https://dzone.com/articles/load-balancing-apache-tomcat
Фасоли, У. (2013 г., 17 августа). Glassfish Cluster SSH — Учебное пособие: Как создать и настроить кластер Glassfish с SSH (Часть 2) [Запись в веб-журнале]. Получено с http://ufasoli.blogspot.com/2013/08/
Фасоли, У. (2013, 17 июля). Glassfish asadmin без пароля. Получено с http://ufasoli.blogspot.fr/2013/07/glassfish-asadmin-without-password.html
Oracle GlassFish Server 3.1 Раздел 1: Подкоманды утилиты asadmin. (й). Получено с https://docs.oracle.com/cd/E18930_01/html/821-2433/gentextid-110.html#scrolltoc
Камареро, РМ (2012, 21 января). clusterjsp.war [WAR]. Получено с http://blogs.nologin.es/rickyepoderi/uploads/SimplebutFullGlassfishHAUsingDebian/clusterjsp.war
Крофт, М. (2016, 30 июня). Создание простого кластера с сервером Payara [запись в веб-журнале]. Получено с http://blog.payara.fish/creating-a-simple-cluster-with-payara-server
Администрирование серверных кластеров GlassFish. (nd) Получено с https://docs.oracle.com/cd/E26576_01/doc.312/e24934/clusters.htm#GSHAG00005
Администрирование узлов сервера GlassFish. (й). Получено с https://docs.oracle.com/cd/E26576_01/doc.312/e24934/nodes.htm#GSHAG00004
Администрирование экземпляров сервера GlassFish. (й). Получено с https://docs.oracle.com/cd/E26576_01/doc.312/e24934/instances.htm#GSHAG00006
| Ссылка: | Высокая доступность (HA), репликация сеанса, кластер Payara с несколькими виртуальными машинами от нашего партнера JCG Майкла Ремиджана в блоге Майкла Ремиджана . |