 В предыдущем посте я описал пример вычисления PageRank, который является частью курса Mining Massive Dataset с Apache Hadoop . В этом посте я взял существующее задание Hadoop на Java и несколько изменил его (добавил модульные тесты и сделал пути к файлам заданными параметром). В этом посте показано, как использовать эту работу в реальном кластере Hadoop. Кластер представляет собой кластер AWS EMR с 1 главным узлом и 5 основными узлами , каждый из которых поддерживается экземпляром m3.xlarge .
В предыдущем посте я описал пример вычисления PageRank, который является частью курса Mining Massive Dataset с Apache Hadoop . В этом посте я взял существующее задание Hadoop на Java и несколько изменил его (добавил модульные тесты и сделал пути к файлам заданными параметром). В этом посте показано, как использовать эту работу в реальном кластере Hadoop. Кластер представляет собой кластер AWS EMR с 1 главным узлом и 5 основными узлами , каждый из которых поддерживается экземпляром m3.xlarge .
Первым шагом является подготовка входных данных для кластера. Я использую AWS S3, так как это удобный способ работы с EMR. Я создал новое ведро ’emr-pagerank-demo’ и создал следующие подпапки:
- в: папка, содержащая входные файлы для работы
- job: папка, содержащая мой исполняемый файл Jad Hadoop
- log: папка, в которую EMR будет помещать свои файлы журналов
Затем в папке «in» я скопировал данные, которые я хочу оценить. Я использовал этот файл в качестве ввода. Разархивированный файл стал файлом размером 5 ГБ с содержимым XML, хотя он и не очень большой, но для демонстрации этого достаточно. Когда вы возьмете исходники предыдущего поста и запустите mvn clean install, вы получите файл jar: ‘hadoop-wiki-pageranking-0.2-SNAPSHOT.jar’. Я загрузил этот jar-файл в папку ‘job’.
Вот и все для подготовки. Теперь мы можем запустить кластер. Для этой демонстрации я использовал Консоль управления AWS :
- Назовите кластер
- Введите папку журнала в качестве местоположения журнала
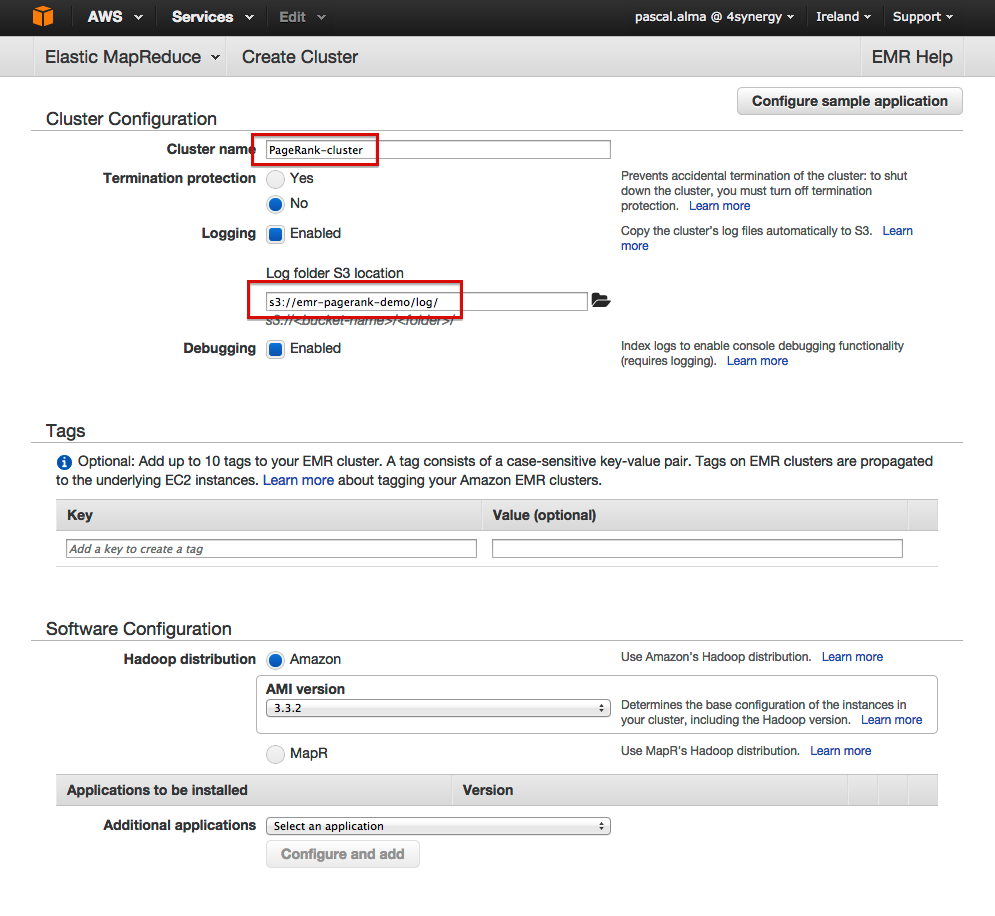
- Введите количество экземпляров Core
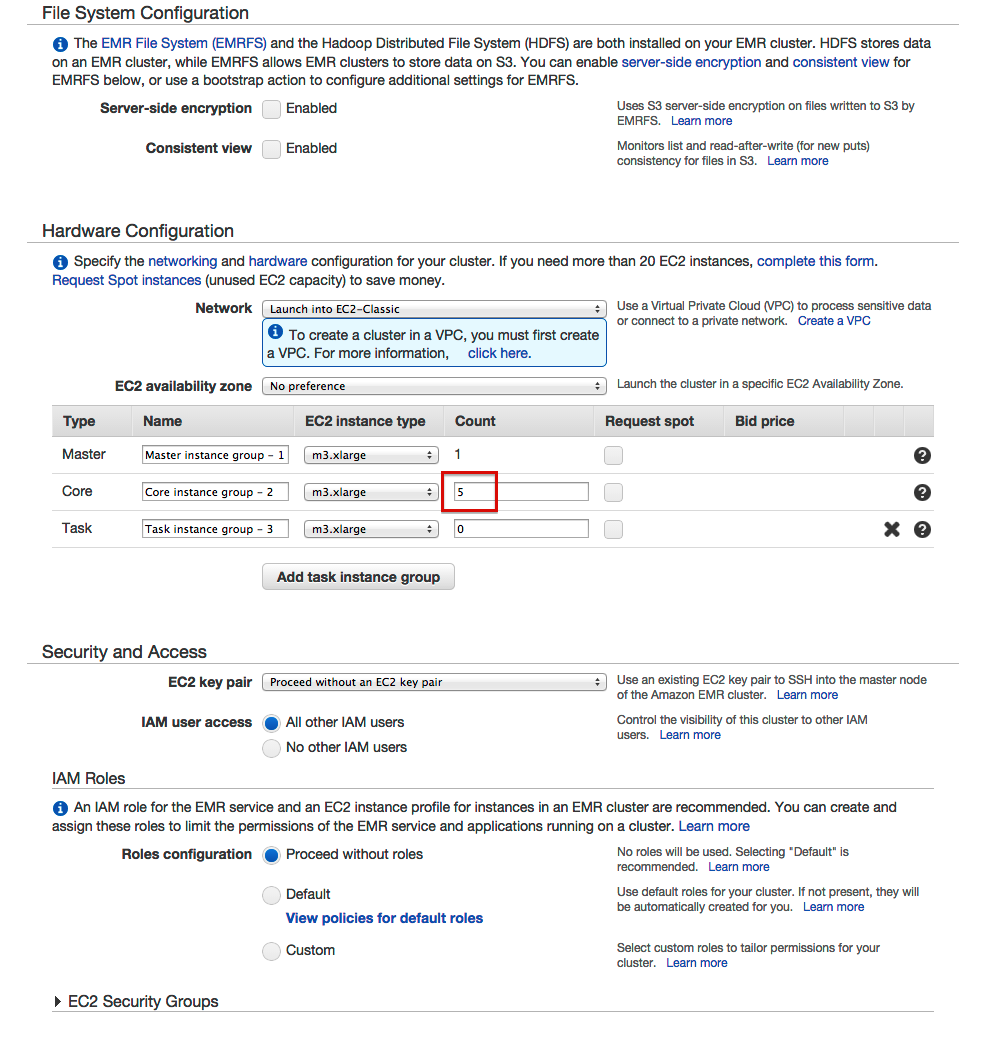
- Добавьте шаг для нашей банки
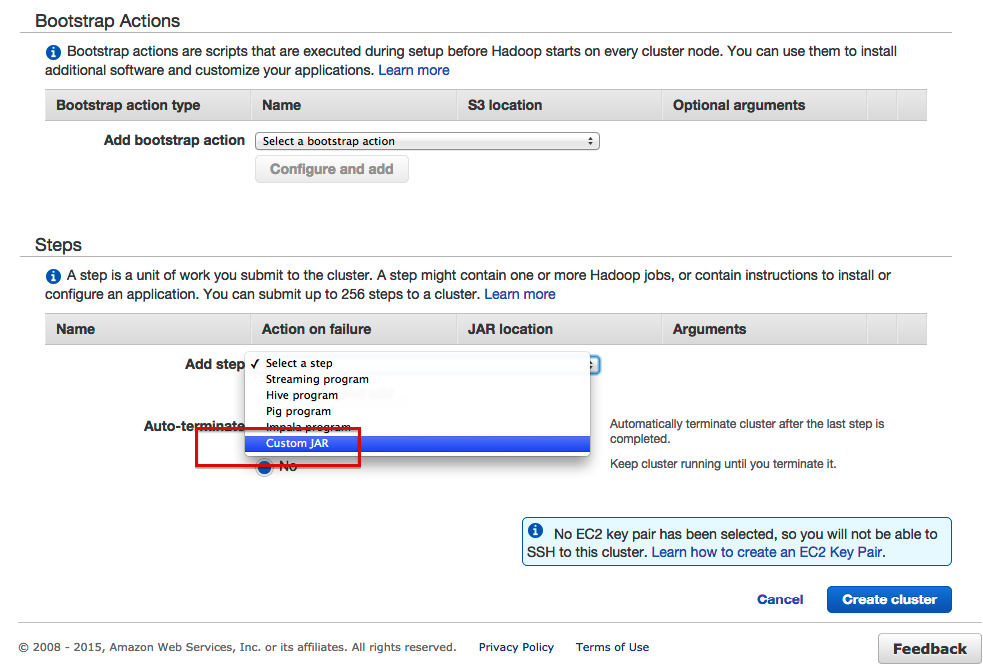
- Настройте шаг следующим образом:
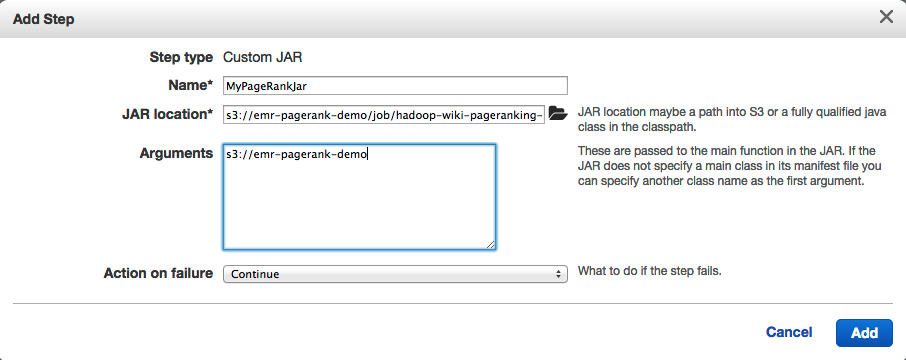
- Это должно привести к следующему обзору:
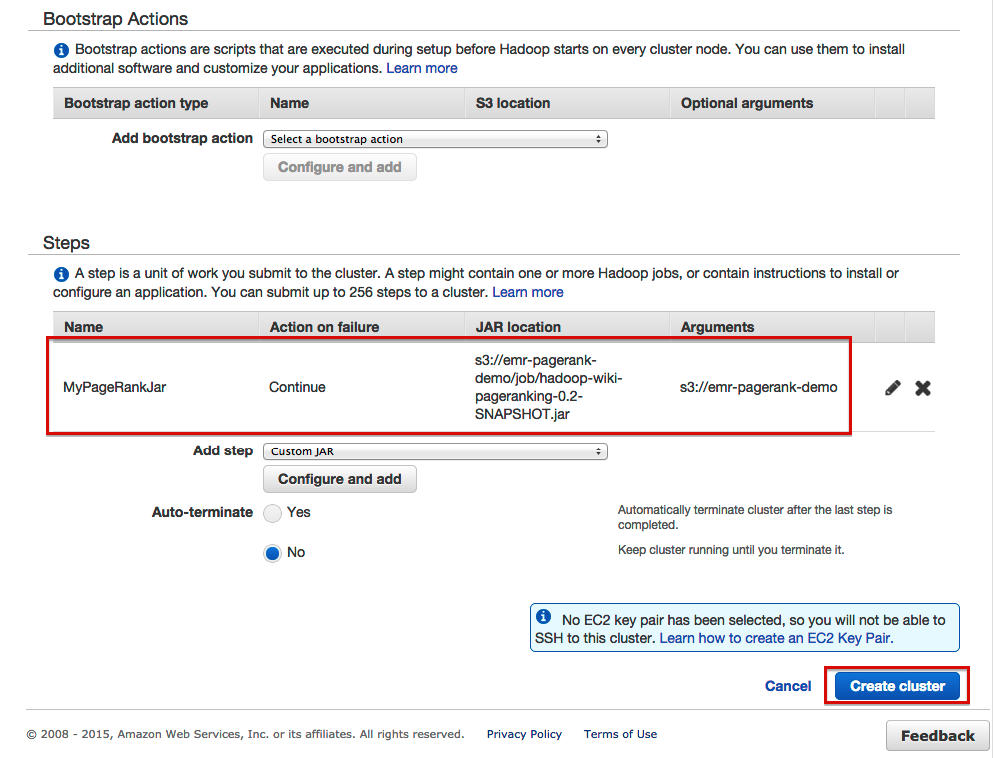
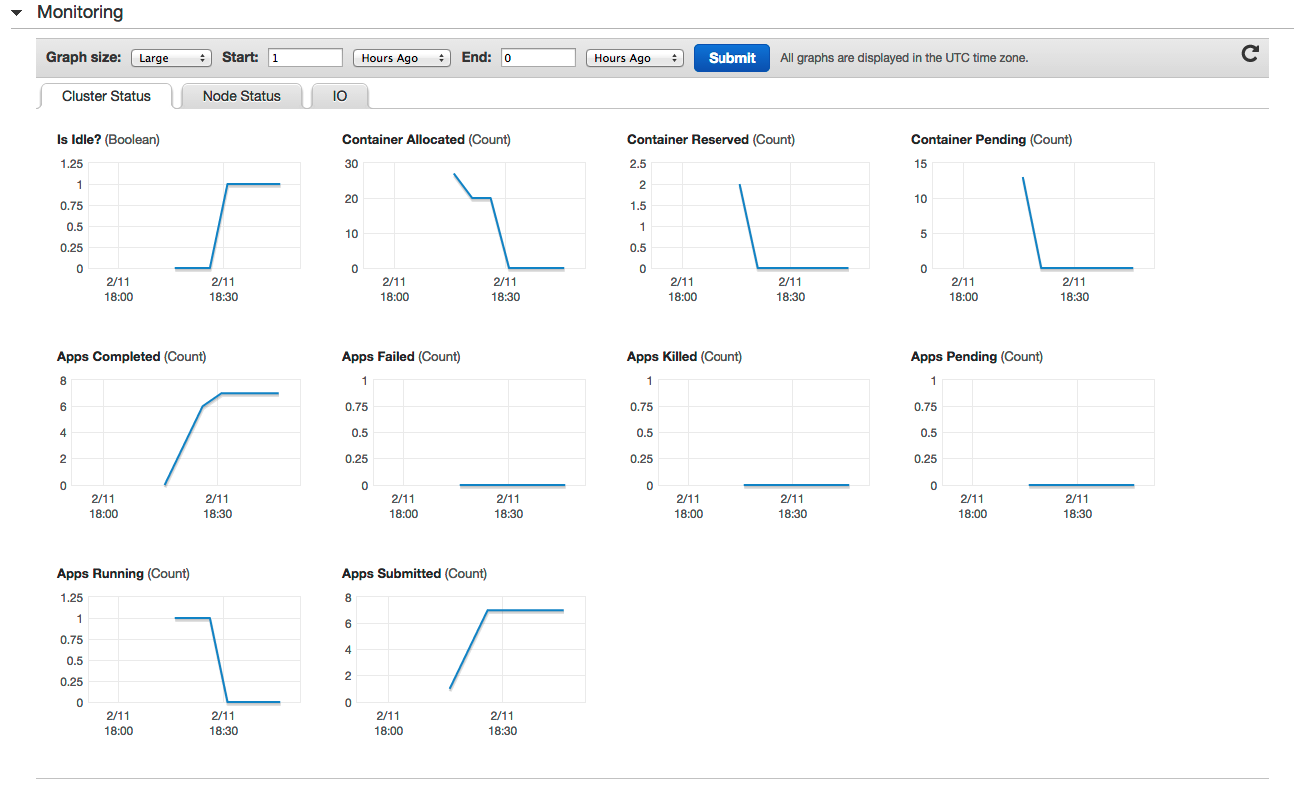
Если это правильно, вы можете нажать кнопку «Создать кластер» и заставить EMR выполнять свою работу. Вы можете отслеживать кластер в разделе «Мониторинг» консоли:
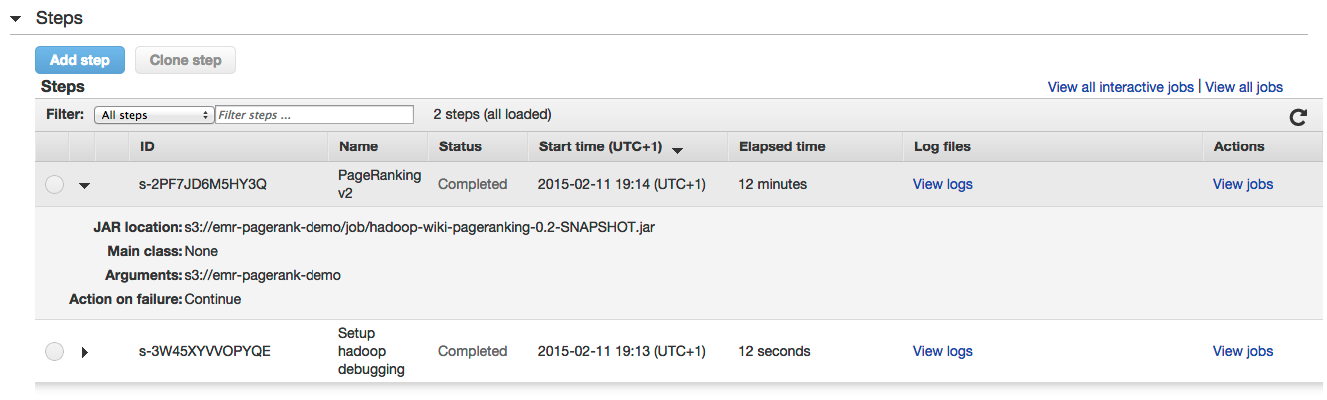
И следите за состоянием шагов в части «Шаги»:
Через несколько минут работа будет завершена (в зависимости от размера входных файлов и используемого кластера, конечно). В нашей корзине S3 мы видим, что файлы журналов создаются в папке ‘log’:
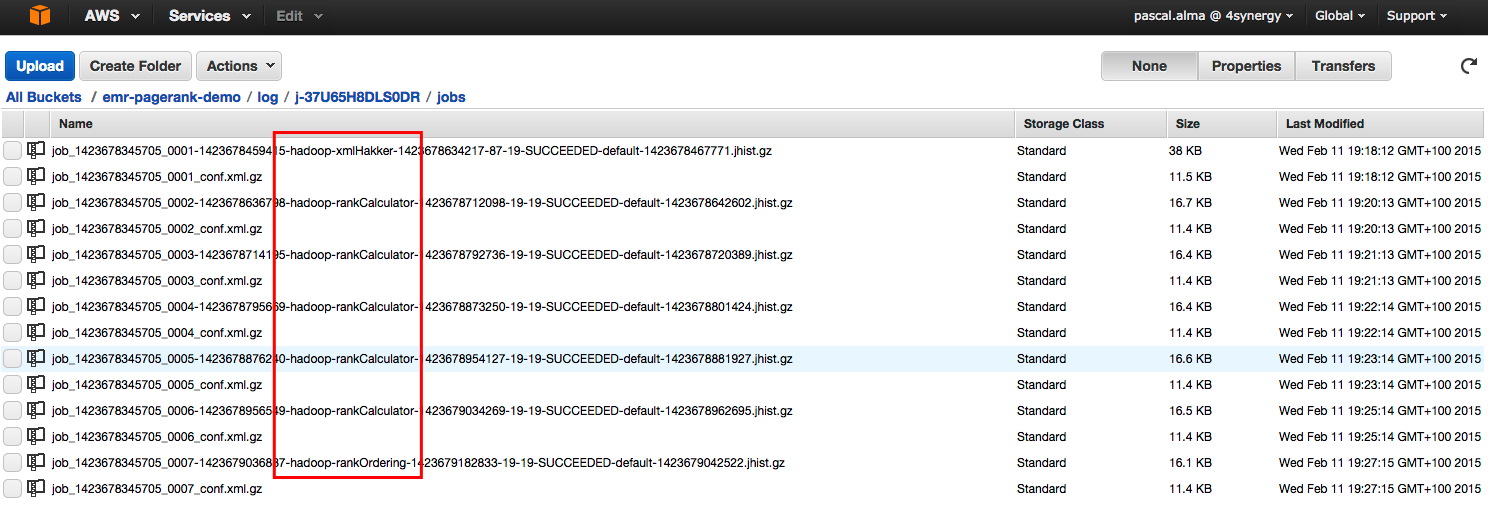
Здесь мы видим в общей сложности 7 заданий: 1 x шаг подготовки Xml, 5 x шаг rankCalculator и 1 x шаг rankOrdering.
И что более важно, мы можем видеть результаты в папке «Result»:
Каждый редуктор создает свой собственный файл результатов, поэтому у нас есть несколько файлов здесь. Нас интересует тот, у кого наибольшее количество, поскольку есть страницы с самыми высокими рангами. Если мы посмотрим на этот файл, то увидим следующий результат в топ-10 рейтинга:
|
01
02
03
04
05
06
07
08
09
10
|
271.6686 Spaans274.22974 Romeinse_Rijk276.7207 1973285.39502 Rondwormen291.83002 Decapoda319.89224 Brussel_(stad)390.02606 2012392.08563 Springspinnen652.5087 20072241.2773 Boktorren |
Обратите внимание, что текущая реализация выполняет вычисления только 5 раз (жестко запрограммировано), поэтому на самом деле это не итерация мощности, как описано в теории MMDS (хорошая модификация для следующего выпуска программного обеспечения :-)).
Также обратите внимание, что кластер не завершается после завершения задания, когда используются параметры по умолчанию, поэтому затраты на кластер увеличиваются, пока кластер не будет завершен вручную.
| Ссылка: | Выполнение задания PageRank Hadoop в AWS Elastic MapReduce от нашего партнера по JCG Паскаля Альмы в блоге Pragmatic Integrator . |