Что такое Apache Kafka?
Apache Kafka — это распределенная потоковая система с возможностью публикации и подписки на поток записей. В другом аспекте это система обмена сообщениями предприятия. Это очень быстрая, горизонтально масштабируемая и отказоустойчивая система. Кафка имеет четыре основных API, называемых
API производителя:
Этот API позволяет клиентам подключаться к серверам Kafka, работающим в кластере, и публиковать поток записей в одной или нескольких темах Kafka.
Потребительский API:
Этот API позволяет клиентам подключаться к серверам Kafka, работающим в кластере, и использовать потоки записей из одной или нескольких тем Kafka. Потребители Кафки вытягивают сообщения из тем Кафки.
API потоков:
Этот API позволяет клиентам действовать как потоковые процессоры, потребляя потоки из одной или нескольких тем и создавая потоки для других выходных тем. Это позволяет преобразовывать входной и выходной потоки.
API коннектора:
Этот API позволяет писать повторно используемый код производителя и потребителя. Например, если мы хотим прочитать данные из любой СУБД, опубликовать данные в теме и использовать данные из темы и записать их в СУБД. С помощью API коннектора мы можем создавать повторно используемые компоненты коннектора источника и приемника для различных источников данных.
Для каких случаев используется Кафка?
Кафка используется для следующих случаев использования,
Система обмена сообщениями:
Kafka используется в качестве системы обмена корпоративными сообщениями для разделения исходной и целевой систем для обмена данными. Kafka обеспечивает высокую пропускную способность с разделами и отказоустойчивость при репликации по сравнению с JMS.
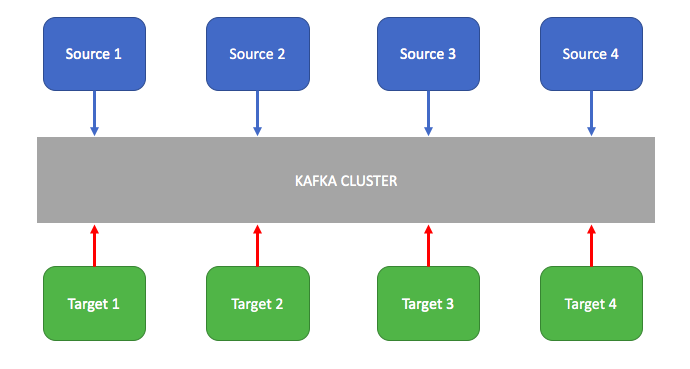
Отслеживание веб-активности:
Отслеживать события путешествия пользователя на сайте для аналитики и обработки данных в автономном режиме.
Агрегация журналов:
Обрабатывать журнал из разных систем. Особенно в распределенных средах с микросервисными архитектурами, где системы развертываются на разных хостах. Нам нужно объединить журналы из разных систем и сделать журналы доступными в центральном месте для анализа. Прочтите статью об архитектуре распределенного ведения журнала, где используется Kafka, https://smarttechie.org/2017/07/31/distributed-logging-architecture-for-micro-services/
Метрика Коллектор:
Кафка используется для сбора метрик из различных систем и сетей для мониторинга операций. Для таких инструментов мониторинга, как Ganglia , Graphite и т. Д., Доступны репортеры метрик Kafka.
Некоторые ссылки на эту https://github.com/stealthly/metrics-kafka
Что такое брокер?
Экземпляр в кластере Kafka называется брокером. В кластере Kafka, если вы подключитесь к одному из брокеров, вы сможете получить доступ ко всему кластеру. Экземпляр посредника, который мы подключаем к кластеру доступа, также известен как сервер начальной загрузки. Каждый брокер идентифицируется числовым идентификатором в кластере. Начнем с кластера Kafka — это три брокера. Но есть кластеры, в которых есть сотни брокеров.
Что такое тема?
Тема — это логическое имя, для которого публикуются записи. Внутри тема разделена на разделы, в которые публикуются данные. Эти разделы распределены между брокерами в кластере. Например, если в теме есть три раздела с 3 посредниками в кластере, у каждого посредника есть один раздел. Опубликованные данные в раздел добавляются только с шагом смещения.
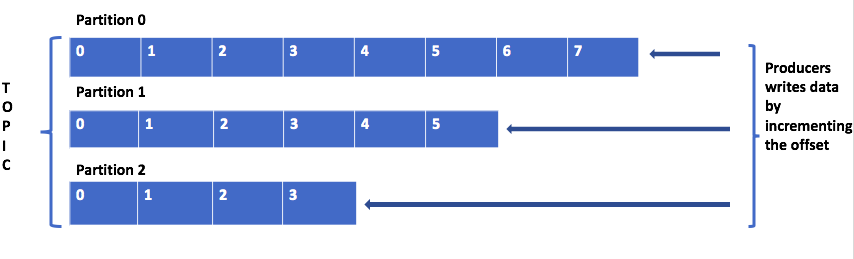
Ниже приведены пара моментов, которые мы должны помнить при работе с разделами.
- Темы идентифицируются по названию. У нас может быть много тем в кластере.
- Порядок сообщений поддерживается на уровне раздела, а не по теме.
- Как только данные, записанные в раздел, не переопределяются. Это называется неизменностью.
- Сообщение в разделах хранится с ключом, значением и отметкой времени. Кафка обеспечивает публикацию сообщения в том же разделе для данного ключа.
- Из кластера Kafka каждый раздел будет иметь лидера, который будет выполнять операции чтения / записи в этот раздел.
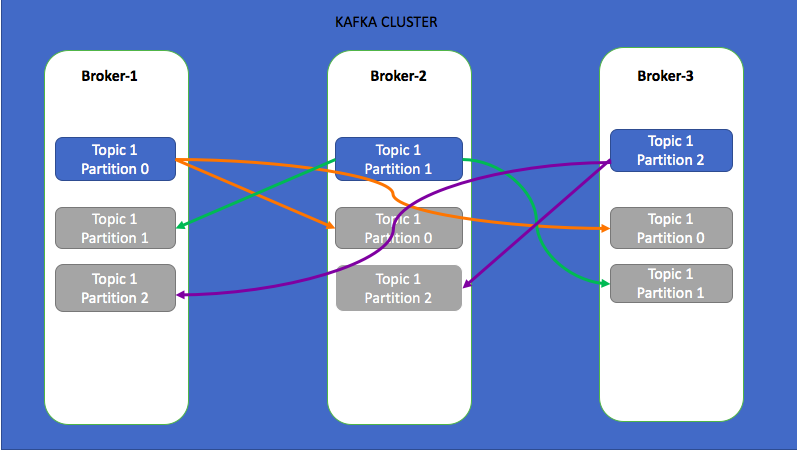
В приведенном выше примере я создал тему с тремя разделами с коэффициентом репликации 3. В этом случае, поскольку кластер имеет 3 посредника, три раздела распределены равномерно, а реплики каждого раздела реплицируются на еще 2 посредника. Поскольку коэффициент репликации равен 3, потери данных не происходит, даже если 2 брокера не работают. Всегда держите коэффициент репликации больше 1 и меньше или равен числу посредников в кластере. Нельзя создать тему с коэффициентом репликации, превышающим количество посредников в кластере.
На приведенной выше диаграмме для каждого раздела есть лидер (светящийся раздел), а другие несинхронные реплики (серые разделы) являются подписчиками. Для раздела 0 брокер-1 является лидером, а брокер-2 — брокером-3 — фолловерами. Все операции чтения / записи в раздел 0 будут переданы в broker-1, а то же самое будет скопировано в broker-2 и broker-3.
Теперь давайте создадим кластер Kafka с 3 брокерами, выполнив следующие шаги.
Шаг 1:
Загрузите последнюю версию Apache Kafka . В этом примере я использую 1.0, который является последним. Извлеките папку и перейдите в папку bin. Запустите Zookeeper, который необходим для запуска с кластера Kafka. Zookeeper — это координационная служба для управления брокерами, выбора лидера для разделов и оповещения Kafka об изменениях в теме (удаление темы, создание темы и т. Д.) Или брокеров (добавление брокера, умирание брокера и т. Д.). В этом примере я запустил только один экземпляр Zookeeper. В производственных средах у нас должно быть больше экземпляров Zookeeper для управления аварийным переключением. Без Zookeeper Kafka кластер не может работать.
|
1
|
./zookeeper-server-start.sh ../config/zookeeper.properties |
Шаг 2:
Теперь начните Kafka брокеров. В этом примере мы собираемся запустить трех брокеров. Перейдите в папку config в корневом каталоге Kafka и скопируйте файл server.properties 3 раза и назовите его как server_1.properties, server_2.properties и server_3.properties. Измените следующие свойства в этих файлах.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
#####server_1.properties#####broker.id=1listeners=PLAINTEXT://:9091log.dirs=/tmp/kafka-logs-1#####server_2.properties######broker.id=2listeners=PLAINTEXT://:9092log.dirs=/tmp/kafka-logs-2######server_3.properties#####broker.id=3listeners=PLAINTEXT://:9093log.dirs=/tmp/kafka-logs-3M |
Теперь запустите 3 брокера с помощью следующих команд.
|
1
2
3
4
5
6
7
8
|
###Start Broker 1 #######./kafka-server-start.sh ../config/server_1.properties###Start Broker 2 #######./kafka-server-start.sh ../config/server_2.properties###Start Broker 3 #######./kafka-server-start.sh ../config/server_3.properties |
Шаг 3:
Создайте тему с помощью команды ниже.
|
1
|
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic first_topic |
Шаг 4:
Создайте несколько сообщений в теме, созданной на предыдущем шаге, с помощью консоли производителя Kafka. Для производителя консоли укажите любой адрес брокера. Это будет сервер начальной загрузки, чтобы получить доступ ко всему кластеру.
|
1
2
3
4
5
6
|
./kafka-console-producer.sh --broker-list localhost:9091 --topic first_topic>First message>Second message>Third message>Fourth message> |
Шаг 5:
Использовать сообщения, используя консоль Kafka. Для потребителя Kafka укажите любой адрес брокера в качестве сервера начальной загрузки. Помните, что при чтении сообщений вы можете не увидеть порядок. Поскольку порядок поддерживается на уровне раздела, а не на уровне темы.
|
1
|
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first_topic --from-beginning |
Если вы хотите, вы можете описать тему, чтобы увидеть, как распределяются разделы и список лидеров каждого раздела, используя команду ниже.
|
1
2
3
4
5
6
7
|
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic first_topic#### The Result for the above command#####Topic:first_topic PartitionCount:3 ReplicationFactor:3 Configs: Topic: first_topic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3 Topic: first_topic Partition: 1 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1 Topic: first_topic Partition: 2 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2 |
В приведенном выше описании broker-1 является лидером для раздела: 0, а broker-1, broker-2 и broker-3 имеют реплики каждого раздела.
В следующей статье мы увидим JAVA API производителя и потребителя. До тех пор, Счастливого Сообщения !!!
| Опубликовано на Java Code Geeks с разрешения Шивы Джанапати, партнера нашей программы JCG. Смотреть оригинальную статью здесь: Введение в Apache Kafka
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |