SBE — это очень быстрая библиотека сериализации, которая используется в финансовой индустрии, в этом блоге я расскажу о некоторых вариантах дизайна, которые сделаны для того, чтобы сделать ее быстрой.
Целью сериализации является кодирование и декодирование сообщений, и доступно множество опций, начиная с XML, JSON, Protobufer, Thrift, Avro и т. Д.
XML / JSON — это кодирование / декодирование на основе текста, в большинстве случаев это хорошо, но когда важна задержка, эти кодирование / декодирование на основе текста становятся узким местом.
Protobuffer / Thrift / Avro являются бинарными опциями и используются очень широко.
SBE также является двоичным и был построен на основе механического сочувствия, чтобы использовать преимущества базового оборудования (кэш-память процессора, предварительный выборщик, шаблон доступа, инструкция конвейера и т. Д.).
Небольшая история революции CPU и Memory.
В нашей отрасли появился мощный процессор из 8-битных, 16-битных, 32-битных, 64-битных, и теперь обычный настольный ЦП может выполнять почти миллиарды команд, если программист способен написать программу для генерации такого типа нагрузки. Память также стала дешевой, и очень легко получить сервер 512 ГБ.
То, как мы программируем, должно измениться, чтобы воспользоваться всеми этими вещами, структура данных и алгоритм должны измениться.
Погружаемся внутрь.
Подход с полным стеком
Большая часть системы полагается на оптимизацию во время выполнения, но SBE использует подход с полным стеком, и первый уровень оптимизации выполняется компилятором.
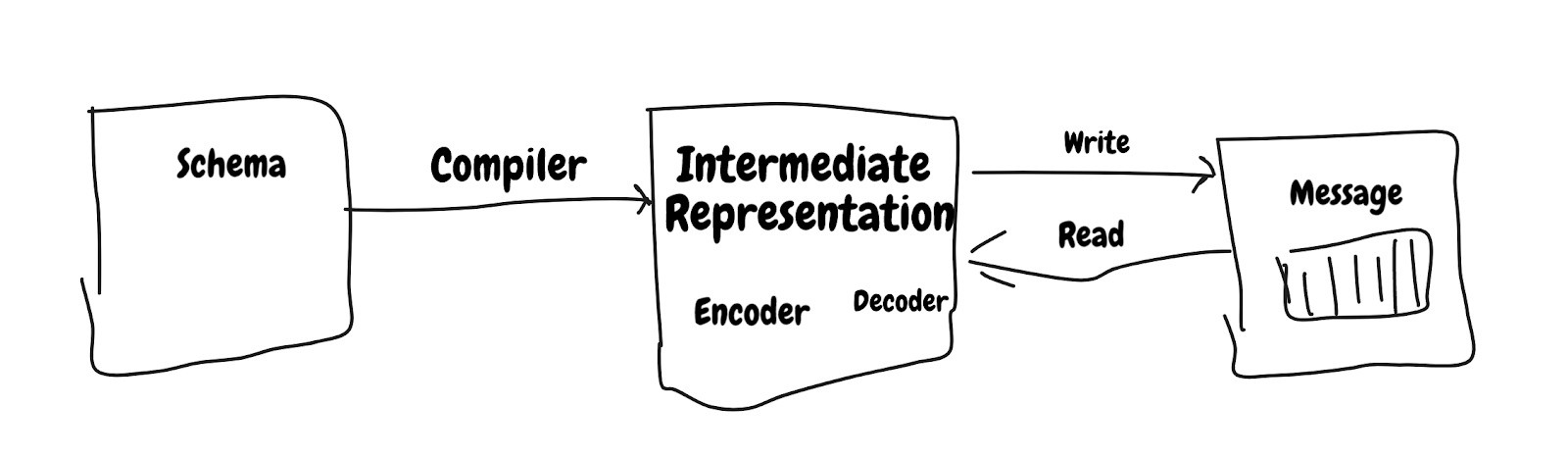
Схема — XML-файл для определения макета и типа данных сообщения.
Компилятор — который принимает схему в качестве входных данных и генерирует IR. В этом слое происходит много магии, например использование финальных / констант, оптимизированного кода.
Сообщение — фактическое сообщение является оберткой над буфером.
Подход с полным стеком позволяет проводить оптимизацию на различном уровне.
Нет мусора или меньше мусора
Это очень важно для системы с низкой задержкой, и если об этом не позаботятся, приложение не сможет правильно использовать кэши ЦП и может войти в GC-паузу.
SBE построен на основе шаблона flyweight , он предназначен для повторного использования объекта, чтобы уменьшить нагрузку на память в JVM.
Он имеет понятие буфера, и его можно использовать повторно, кодер / декодер может принимать буфер в качестве входных данных и работать с ним. Кодер / Декодер не выделяет или очень мало (т.е. в случае String).
SBE рекомендует использовать буфер прямой / автономной памяти, чтобы полностью исключить GC, эти буферы могут быть выделены на уровне потоков и могут использоваться для декодирования и кодирования сообщений.
Фрагмент кода для использования буфера.
|
1
2
3
|
final ByteBuffer byteBuffer = ByteBuffer.allocateDirect(4096);final UnsafeBuffer directBuffer = new UnsafeBuffer(byteBuffer); |
|
1
2
3
4
5
|
tradeEncoder .tradeId(1) .customerId(999) .qty(100) .symbol("GOOG") .tradeType(TradeType.Buy); |
Предварительная выборка кэша
CPU имеет встроенный аппаратный предварительный выбор. Предварительная выборка из кэша — это методика, используемая компьютерными процессорами для повышения производительности выполнения путем извлечения инструкций или данных из их исходного хранилища в более медленной памяти в более быструю локальную память до того, как она фактически понадобится.
Доступ к данным из быстрого кэша ЦП на много порядков быстрее, чем доступ из основной памяти.
В сообщении блога « номер задержки, о котором вы должны знать » подробно рассказывается о том, насколько быстрым может быть кэш процессора.
Предварительная выборка работает очень хорошо, если алгоритм выполняет потоковую передачу, а используемые данные непрерывны, как массив. Доступ к массиву очень быстрый, потому что он последовательный и предсказуемый
SBE использует массив в качестве основного хранилища, и в него упакованы поля.
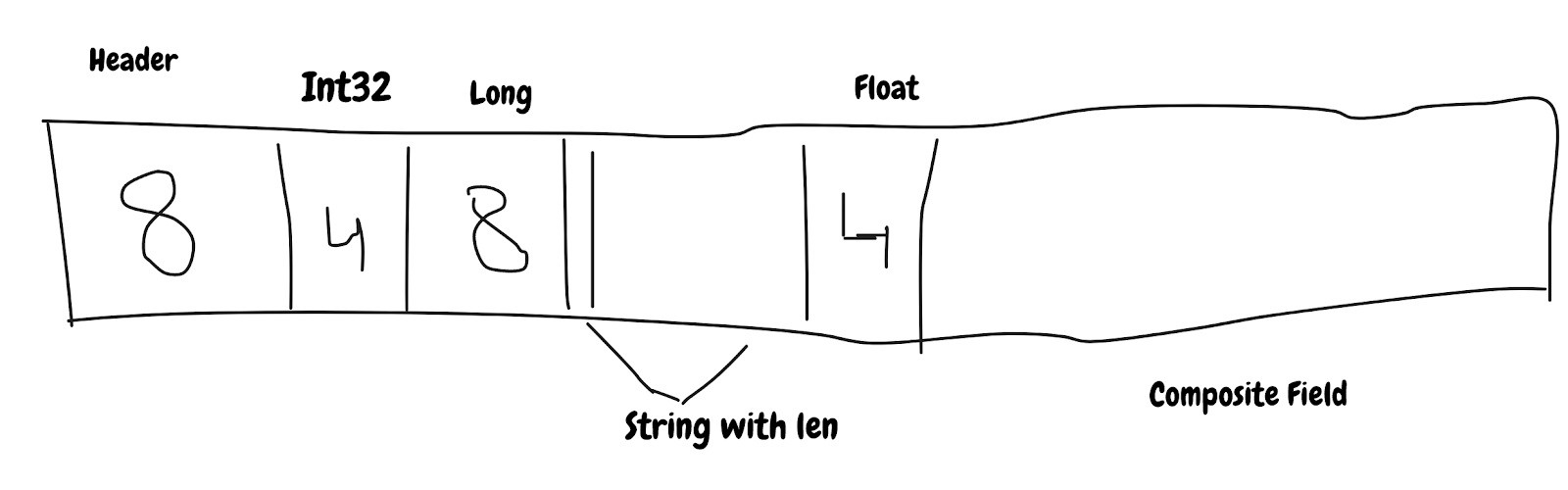
Данные перемещаются небольшими партиями строки кэша, которая обычно составляет 8 байт, поэтому, если приложение запрашивает 1 байт, оно получает 8 байт данных. Поскольку данные упакованы в массив, доступ к содержимому массива однобайтовой предварительной выборки заранее, и это ускорит обработку.
Думайте о prefetcher как об индексе в таблице базы данных. Приложение получит выгоду, если чтения основаны на этих индексах.
Потоковый доступ
SBE поддерживает все типы примитивов, а также позволяет определять пользовательские типы с переменным размером, что позволяет кодеру и декодеру быть потоковыми и последовательными. Это имеет большое преимущество при чтении данных из строки кэша, и декодер должен знать очень мало метаданных о сообщении (то есть смещение и размер).
Это происходит с компромиссным порядком чтения, который должен основываться на порядке компоновки, особенно если кодируются переменные типы данных.
Например, напишите, используя нижеуказанный порядок
|
1
2
3
4
5
6
|
tradeEncoder .tradeId(1) .customerId(999) .tradeType(TradeType.Buy) .qty(100) .symbol("GOOG") .exchange("NYSE"); |
Для строковых атрибутов (символ и обмен) порядок чтения должен быть первым символом, а затем заменен , если приложение меняет порядок, тогда оно будет читать неправильное поле, другое считывание должно быть только один раз для атрибута переменной длины, потому что это потоковый шаблон доступа.
Хорошие вещи приходят по цене!
Небезопасный API
Проверка с привязкой к массиву может добавить накладные расходы, но SBE использует небезопасный API, и у него нет дополнительных накладных расходов на проверку привязки.
Используйте константы в сгенерированном коде
Когда компилятор генерирует код, он предварительно вычисляет материал и использует константы. Одним примером является поле off set в сгенерированном коде, оно не вычисляется.
Фрагмент кода
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public static int qtyId(){return 2;}public static int qtySinceVersion(){return 0;}public static int qtyEncodingOffset(){return 16;}public static int qtyEncodingLength(){return 8;} |
Это имеет компромисс, это хорошо для производительности, но не хорошо для гибкости. Вы не можете изменить порядок полей, и новые поля должны быть добавлены в конце.
Еще одна хорошая вещь о константах — это то, что они есть только в сгенерированном коде, а не в сообщении. Это очень эффективно.
Бесплатный код филиала
Каждое ядро имеет несколько портов для параллельной работы, и есть несколько инструкций, которые душат как ветви, мод, деление. SBE-компилятор генерирует код, свободный от этих дорогих инструкций, и имеет базовую математику с указателями.
Код, свободный от дорогих инструкций, очень быстрый и использует все порты ядра.
Пример кода для сериализации Java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
public void writeFloat(float v) throws IOException { if (pos + 4 <= MAX_BLOCK_SIZE) { Bits.putFloat(buf, pos, v); pos += 4; } else { dout.writeFloat(v); }}public void writeLong(long v) throws IOException { if (pos + 8 <= MAX_BLOCK_SIZE) { Bits.putLong(buf, pos, v); pos += 8; } else { dout.writeLong(v); }}public void writeDouble(double v) throws IOException { if (pos + 8 <= MAX_BLOCK_SIZE) { Bits.putDouble(buf, pos, v); pos += 8; } else { dout.writeDouble(v); }} |
Пример кода для SBE
|
1
2
3
|
public TradeEncoder customerId(final long value){ buffer.putLong(offset + 8, value, java.nio.ByteOrder.LITTLE_ENDIAN); return this;} |
|
1
2
3
|
public TradeEncoder tradeId(final long value){ buffer.putLong(offset + 0, value, java.nio.ByteOrder.LITTLE_ENDIAN); return this;} |
Некоторые цифры по размеру сообщения.
Тип класса маршал.СериализуемыйМаршал -> размер 267
Тип класса маршал. ExternalizableMarshal -> размер 75
Тип класса маршал.SBEMarshall -> размер 49
SBE является наиболее компактным и очень быстрым, авторы SBE утверждают, что он примерно в 20-50 раз быстрее, чем протобуфер Google.
Код SBE доступен при простом бинарном кодировании
Пример кода, используемого в блоге, доступен @ sbeplayground
| Смотрите оригинальную статью здесь: Inside Simple Binary Encoding (SBE)
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |