Тема сегодняшнего поста немного отходит от повседневного программирования и разработки, но, тем не менее, охватывает очень важную тему: файлы журналов нашего приложения. Наши приложения генерируют огромное количество журналов, которые, если все сделано правильно, чрезвычайно полезны для устранения неполадок. Это не имеет большого значения, если у вас запущено и работает одно приложение, но в настоящее время приложения, в частности веб-приложения, работают на сотнях серверов. При таких масштабах выяснить, где проблема становится проблемой. Разве не было бы неплохо иметь какое-то представление, которое объединяет все журналы всех наших запущенных приложений в одну панель инструментов, чтобы мы могли видеть целое изображение, построенное из кусочков? Пожалуйста, добро пожаловать: Logstash , структура агрегации журналов.
Хотя это не единственное доступное решение, я обнаружил, что Logstash очень прост в использовании и чрезвычайно прост в интеграции. Начнем с того, что нам даже не нужно ничего делать на стороне приложения, Logstash может сделать всю работу за нас. Позвольте мне представить пример проекта: отдельное Java-приложение, в котором выполняется многопоточность. Существует запись в файл, сконфигурированный с использованием великолепной библиотеки Logback ( SLF4J может быть использован в качестве простой замены). Файл POM выглядит довольно просто:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemalocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelversion>4.0.0</modelversion> <groupid>com.example</groupid> <artifactid>logstash</artifactid> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <properties> <project.build.sourceencoding>UTF-8</project.build.sourceencoding> <logback.version>1.0.6</logback.version> </properties> <dependencies> <dependency> <groupid>ch.qos.logback</groupid> <artifactid>logback-classic</artifactid> <version>${logback.version}</version> </dependency> <dependency> <groupid>ch.qos.logback</groupid> <artifactid>logback-core</artifactid> <version>${logback.version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupid>org.apache.maven.plugins</groupid> <artifactid>maven-compiler-plugin</artifactid> <version>3.0</version> <configuration> <source>1.7 <target>1.7</target> </configuration> </plugin> </plugins> </build></project> |
И есть только один класс Java под названием Starter, который использует службы Executors для одновременной работы. Несомненно, каждый поток выполняет некоторую регистрацию, и время от времени возникает исключение.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
package com.example.logstash;import java.util.ArrayList;import java.util.Collection;import java.util.Random;import java.util.concurrent.Callable;import java.util.concurrent.ExecutionException;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Future;import java.util.concurrent.TimeUnit;import java.util.concurrent.TimeoutException;import org.slf4j.Logger;import org.slf4j.LoggerFactory;public class Starter { private final static Logger log = LoggerFactory.getLogger( Starter.class ); public static void main( String[] args ) { final ExecutorService executor = Executors.newCachedThreadPool(); final Collection< Future< Void > > futures = new ArrayList< Future< Void > >(); final Random random = new Random(); for( int i = 0; i < 10; ++i ) { futures.add( executor.submit( new Callable< Void >() { public Void call() throws Exception { int sleep = Math.abs( random.nextInt( 10000 ) % 10000 ); log.warn( 'Sleeping for ' + sleep + 'ms' ); Thread.sleep( sleep ); return null; } } ) ); } for( final Future< Void > future: futures ) { try { Void result = future.get( 3, TimeUnit.SECONDS ); log.info( 'Result ' + result ); } catch (InterruptedException | ExecutionException | TimeoutException ex ) { log.error( ex.getMessage(), ex ); } } }} |
Идея состоит в том, чтобы продемонстрировать не только простые однострочные события регистрации, но и знаменитые трассировки стека Java. Поскольку каждый поток спит в течение произвольного временного интервала, он вызывает исключение TimeoutException каждый раз, когда запрашивается результат вычисления из базового будущего объекта и для его возврата требуется более 3 секунд. Последняя часть — это конфигурация Logback ( logback.xml ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
<configuration scan="true" scanperiod="5 seconds"> <appender name="FILE" class="ch.qos.logback.core.FileAppender"> <file>/tmp/application.log</file> <append>true</append> <encoder> <pattern>[%level] %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %logger{36} - %msg%n</pattern> </encoder> </appender> <root level="INFO"> <appender-ref ref="FILE"> </appender-ref></root></configuration> |
И мы готовы идти! Обратите внимание, что путь к файлу /tmp/application.log соответствует c: \ tmp \ application.log в Windows. Запуск нашего приложения заполнил бы файл журнала чем-то вроде этого:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
[WARN] 2013-02-19 19:26:03.175 [pool-2-thread-1] com.example.logstash.Starter - Sleeping for 2506ms[WARN] 2013-02-19 19:26:03.175 [pool-2-thread-4] com.example.logstash.Starter - Sleeping for 9147ms[WARN] 2013-02-19 19:26:03.175 [pool-2-thread-9] com.example.logstash.Starter - Sleeping for 3124ms[WARN] 2013-02-19 19:26:03.175 [pool-2-thread-3] com.example.logstash.Starter - Sleeping for 6239ms[WARN] 2013-02-19 19:26:03.175 [pool-2-thread-5] com.example.logstash.Starter - Sleeping for 4534ms[WARN] 2013-02-19 19:26:03.175 [pool-2-thread-10] com.example.logstash.Starter - Sleeping for 1167ms[WARN] 2013-02-19 19:26:03.175 [pool-2-thread-7] com.example.logstash.Starter - Sleeping for 7228ms[WARN] 2013-02-19 19:26:03.175 [pool-2-thread-6] com.example.logstash.Starter - Sleeping for 1587ms[WARN] 2013-02-19 19:26:03.175 [pool-2-thread-8] com.example.logstash.Starter - Sleeping for 9457ms[WARN] 2013-02-19 19:26:03.176 [pool-2-thread-2] com.example.logstash.Starter - Sleeping for 1584ms[INFO] 2013-02-19 19:26:05.687 [main] com.example.logstash.Starter - Result null[INFO] 2013-02-19 19:26:05.687 [main] com.example.logstash.Starter - Result null[ERROR] 2013-02-19 19:26:08.695 [main] com.example.logstash.Starter - nulljava.util.concurrent.TimeoutException: null at java.util.concurrent.FutureTask$Sync.innerGet(FutureTask.java:258) ~[na:1.7.0_13] at java.util.concurrent.FutureTask.get(FutureTask.java:119) ~[na:1.7.0_13] at com.example.logstash.Starter.main(Starter.java:43) ~[classes/:na][ERROR] 2013-02-19 19:26:11.696 [main] com.example.logstash.Starter - nulljava.util.concurrent.TimeoutException: null at java.util.concurrent.FutureTask$Sync.innerGet(FutureTask.java:258) ~[na:1.7.0_13] at java.util.concurrent.FutureTask.get(FutureTask.java:119) ~[na:1.7.0_13] at com.example.logstash.Starter.main(Starter.java:43) ~[classes/:na][INFO] 2013-02-19 19:26:11.696 [main] com.example.logstash.Starter - Result null[INFO] 2013-02-19 19:26:11.696 [main] com.example.logstash.Starter - Result null[INFO] 2013-02-19 19:26:11.697 [main] com.example.logstash.Starter - Result null[INFO] 2013-02-19 19:26:12.639 [main] com.example.logstash.Starter - Result null[INFO] 2013-02-19 19:26:12.639 [main] com.example.logstash.Starter - Result null[INFO] 2013-02-19 19:26:12.639 [main] com.example.logstash.Starter - Result null |
Теперь давайте посмотрим, что Logstash может сделать для нас. Из раздела загрузки мы получаем единственный файл JAR: logstash-1.1.9-monolithic.jar . Это все, что нам нужно на данный момент. К сожалению, из- за этой ошибки в Windows мы должны где- то развернуть logstash-1.1.9-monolithic.jar , например, в папку logstash-1.1.9-monolithic . Logstash имеет только три концепции: входы , фильтры и выходы . Это очень хорошо объяснено в документации . В нашем случае вход представляет собой файл журнала приложения, c: \ tmp \ application.log . Но каков будет выход? ElasticSearch, кажется, является отличным кандидатом для этого: давайте внесем в журнал наши логи в любое время. Давайте скачаем и запустим его:
|
1
|
elasticsearch.bat -Des.index.store.type=memory -Des.network.host=localhost |
Теперь мы готовы интегрировать Logstash, который должен привязать наш файл журнала и направить его непосредственно в ElasticSearch . Следующая конфигурация делает именно это ( logstash.conf ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
input { file { add_field => [ 'host', 'my-dev-host' ] path => 'c:\tmp\application.log' type => 'app' format => 'plain' }}output { elasticsearch_http { host => 'localhost' port => 9200 type => 'app' flush_size => 10 }}filter { multiline { type => 'app' pattern => '^[^\[]' what => 'previous' }} |
На первый взгляд это может показаться не очень ясным, но позвольте мне объяснить, что к чему. Таким образом, вводом является c: \ tmp \ application.log , который представляет собой простой текстовый файл ( format => ‘plain’ ). Type => ‘app’ служит простым маркером, поэтому различные типы входов могут быть направлены на выходы через фильтры одного типа. Add_field => [‘host’, ‘my-dev-host’] позволяет вводить дополнительные произвольные данные во входящий поток, например имя хоста.
Вывод довольно ясный: ElasticSearch over HTTP, порт 9200 (настройки по умолчанию). Фильтрам нужно немного магии, все из-за следов стека Java. Многострочный фильтр склеит трассировку стека с оператором журнала, к которому он принадлежит, и будет сохранен как одна (большая) многострочная. Давайте запустим Logstash :
|
1
|
java -cp logstash-1.1.9-monolithic logstash.runner agent -f logstash.conf |
Большой! Теперь, когда мы запускаем наше приложение, Logstash будет наблюдать файл журнала, фильтровать его свойства и отправлять напрямую в ElasticSearch . Круто, но как мы можем выполнить поиск или хотя бы посмотреть, какие у нас есть данные? Хотя ElasticSearch имеет великолепный REST API, мы можем использовать другой отличный проект, Kibana , интерфейс веб-интерфейса для ElasticSearch . Установка очень проста и без проблем. После нескольких необходимых шагов мы запускаем Kibana :
|
1
|
ruby kibana.rb |
По умолчанию Kibana предоставляет веб-интерфейс, доступный через порт 5601, давайте нацелим на него наш браузер, http: // localhost: 5601 /, и мы должны увидеть что-то подобное (пожалуйста, нажмите на изображение для увеличения):
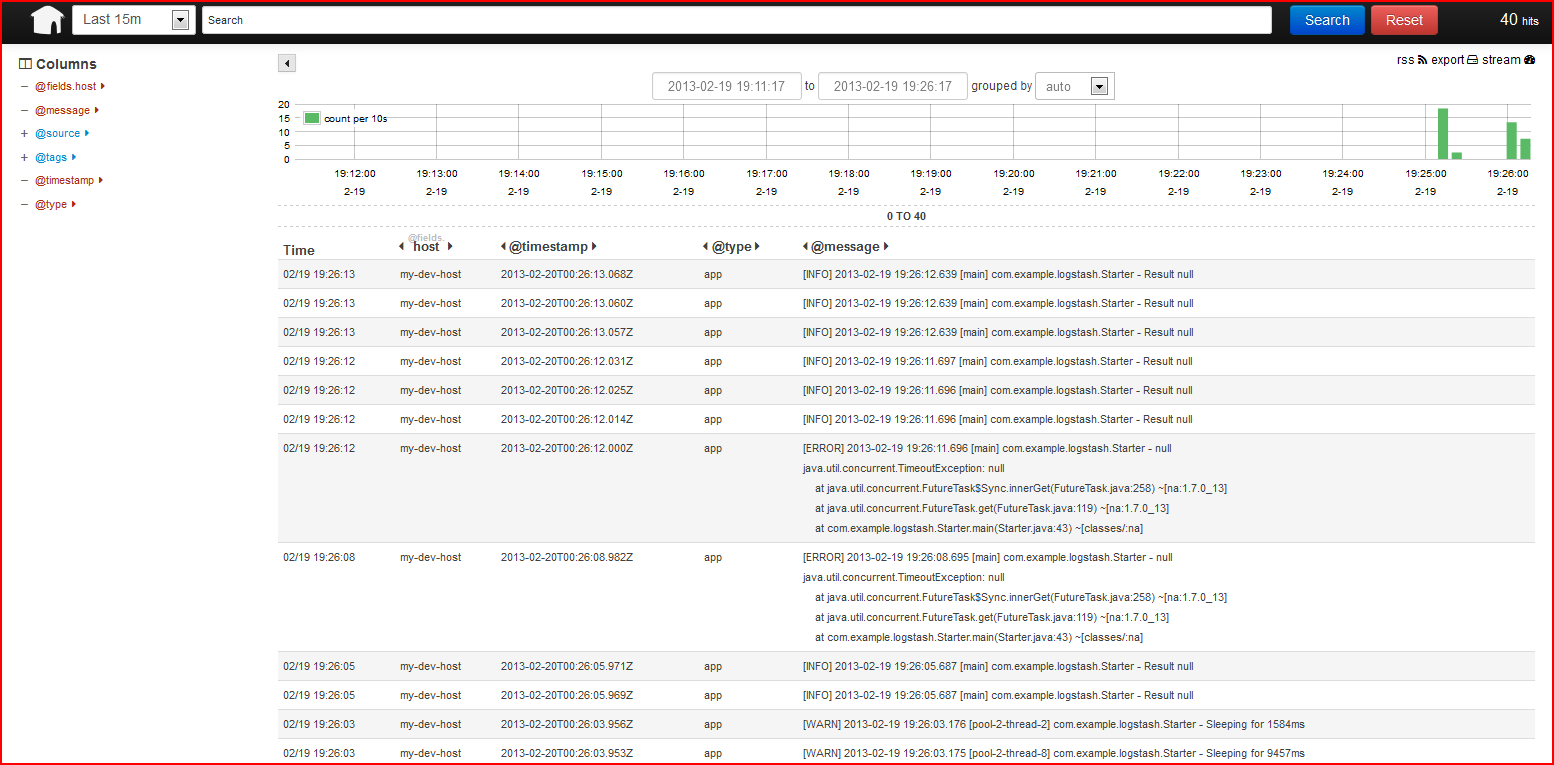
Все наши операторы журналов, дополненные именем хоста, просто есть. Исключения (со следами стека) связаны с соответствующим оператором журнала. Уровни журнала, отметки времени, все показывается. Полнотекстовый поиск доступен из коробки, благодаря ElasticSearch.
Это все круто, но наше приложение очень просто. Будет ли этот подход работать при развертывании с несколькими серверами / несколькими приложениями? Я уверен, что это будет работать просто отлично. Интеграция Logstash с Redis , ZeroMQ , RabbitMQ ,… позволяет собирать журналы из десятков различных источников и объединять их в одном месте. Большое спасибо, ребята из Logstash !
Ссылка: ваши журналы — ваши данные: logstash +asticsearch от нашего партнера по JCG Андрея Редько в блоге Андрея Редько {devmind} .