В этом блоге описывается решение типичной проблемы параллелизма в среде веб-приложений, а также показано, что вы, по всей вероятности, не можете быть уверены, что ваше приложение является поточно-ориентированным. Это просто работает — по стечению обстоятельств.
На прошлой неделе у нас была серьезная проблема в критически важном веб-модуле нашей производственной среды. Проблема заключалась в том, что нам приходилось перезагружать сервер в то время, когда у нас были очень большие объемы пользователей и транзакций (мы выполняем ~ 500 000 транзакций в этом модуле за рабочий день). Выключение сервера удалило наш кеш шаблона XSL. В результате многие потоки пытались перекомпилировать шаблоны одновременно после перезапуска. Это, в свою очередь, привело к проблеме перегрузки (ЦП) системы. Мы могли только перезапустить сервер, заблокировав входящие запросы на уровне веб-сервера. Фактически мы позволяли только некоторым потокам обходить веб-сервер и заходить на сервер приложений. После некоторого времени прогрева мы открыли веб-сервер, и система начала работать при приемлемой загрузке процессора.
Мы рассмотрели код приложения, вызвавший проблему, и решили реализовать интеллектуальный шаблон параллелизма, который удовлетворяет следующим требованиям:
— количество потоков, одновременно выполняющих интенсивную загрузку ЦП (например, компиляцию шаблона XSL), должно быть ограничено настраиваемым размером (=> избегать перегрузки ЦП при запуске в периоды пиковой нагрузки пользователя)
— кэшировать результат каждой интенсивной задачи ЦП, чтобы она выполнялась только один раз (у нас это уже было в нашем подверженном ошибкам решении)
— разрешить системе определять, является ли ЦП интенсивная задача должна быть выполнена снова (=> если приложение было повторно развернуто, шаблоны должны быть перекомпилированы)
Я избавляю меня от усилий (и трудностей), чтобы опубликовать старый небезопасный код. Ошибки в этом коде были:
во-первых— он не ограничивал количество потоков, позволяющих компилировать шаблоны,
во-вторых, — он не гарантировал, что только один поток компилирует определенный шаблон в данный момент времени (например, нашу стартовую страницу), — вместо этого многие потоки пытались скомпилировать один и тот же шаблон одновременно — это один имеет решающее значение!
Это все, как говорится, здесь приходит решение такой «проблемы параллелизма слишком много потоков». Вот код, и я также добавил диаграмму классов, потому что я считаю, что это обычная ситуация в веб-приложениях.
В следующем фрагменте показан наш новый HTMLDocumentGenerator, его обязанность — создавать и кэшировать экземпляры ConcurrentTransformer, по одному для каждого XSL-документа. Ответственность ConcurrentTransformer состоит в том, чтобы скомпилировать шаблон XSL и сохранить результат в его переменной шаблона. HTMLDocumentGenerator владеет кешем (строка 3), определяет лимит потоков, которые могут компилировать документы XSL (строка 5), и объявляет семафор, который реализует «компонент, создающий потоки» (строка 6). Метод createDocument (строки 10-20) создает и кэширует новые экземпляры ConcurrentTransformer для каждого документа XSL. Пример: /start/index.xsl будет иметь свой собственный экземпляр ConcurrentTransformer, а /start/main_menu.xsl также будет иметь свой собственный уникальный экземпляр.
public class HTMLDocumentGenerator implements DocumentGenerator, Initialisierbar, Reinitialisierbar, HTMLDocumentGeneratorMBean {
private final ConcurrentHashMap<String, ConcurrentTransformer> transformerCache =
new ConcurrentHashMap<String, ConcurrentTransformer>();
private int concurrentParserThreadCount = 10;
protected Semaphore bouncer;
...
public void createDocument(OutputStream document, Map<String, ?> inputData) throws DocumentGeneratorAusnahme {
...
ConcurrentTransformer newTransformer;
ConcurrentTransformer transformer =
transformerCache.putIfAbsent(xslDocumentName, newTransformer = new ConcurrentTransformer(xslDocumentName));
if (transformer == null) {
transformer = newTransformer;
}
template = transformer.generateTemplate(loadTimeApplication);
...
}
...
public void initialize() throws InitialisierungsAusnahme {
transformerCache.clear();
if (concurrentParserThreadCount <= 0) {
concurrentParserThreadCount = 10;
}
bouncer = new Semaphore(concurrentParserThreadCount);
}
...
}
Обратите внимание, что мы используем ConcurrentHashmap.putIfAbsent (), который позволяет выполнять поиск и создание кэшированных объектов за один шаг. Это эквивалентно:
if (!map.containsKey(key)) return map.put(key, value); else return map.get(key);
This is a perfect approach in a multithreaded high volume application. You could do the same with owned locks or synchronized blocks, but it will hardly be so safe (and fast!) like the example above. You will understand my statement if you look at the implementation of ConcurrentHashmap. It locks segments internally and not the whole table! This allows very high volumes of concurrent access without lock contention. In Line 18 we call the method generateTemplate that actually performs the CPU intense task (template compilation).
In Line 5 we declared a Semaphore which acts as a bouncer for the CPU intense code sections. Using this class you can control the number of concurrent threads that perform a certain task concurrently. It’s important to declare the Semaphore in the HTMLDocumentGenerator class, ’cause the thread limit applies to all cached ConcurrentTransformer instances.
Now let’s look at the ConcurrentTransformer that I declared as a protected inner class of HTMLDocumentGenerator. Using an inner class ConcurrentTransformer instances have immediate access to member variables of HTMLDocumentGenerator. There is one ConcurrentTransformer for each unique XSL template.
protected class ConcurrentTransformer {
private final Lock lock = new ReentrantLock();
private URL url = null;
private volatile Templates template = null;
private long lastCompileTime = Long.MAX_VALUE;
protected Templates generateTemplate(long ladezeitProzessApp) throws TransformerFactoryConfigurationError, TransformerConfigurationException, InterruptedException {
if (!mustCompile(loadTimeApplication)) {
return template;
}
lock.lockInterruptibly();
try {
if (!mustCompile(loadTimeApplication)) {
return template;
}
bouncer.acquire();
try {
TransformerFactory transFactory = TransformerFactory.newInstance();
URIResolver resolver = transFactory.getURIResolver();
transFactory.setURIResolver(new XMLTransformResolver(resolver));
StreamSource source = new StreamSource(url.toExternalForm());
template = transFactory.newTemplates(source);
lastCompileTime = System.currentTimeMillis();
return template;
} finally {
bouncer.release();
}
} finally {
lock.unlock();
}
}
private boolean mustCompile(long loadTimeApplication) {
return template == null || !templateCacheActive || requiresRecompile(loadTimeApplication);
}
}
Let’s go through generateTemplate step-by-step:
Line 9: check if thread needs to compile this XSL template. If false, return the compiled template. mustCompile returns true if for example the template variable is null, which means the template wasn’t compiled yet. The first thread that enters generateTemplate will get mustCompile() = true ’cause the ConcurrentTransformer was just created by that thread and the template variable is null.
Line 12: Block all subsequent threads ’cause only ONE thread can compile THIS XSL template at a given time.
Line 14: check again if thread needs to compile the XSL template. Sounds weird? Imagine a second thread that was blocked at Line 12 ’cause the first call to mustCompile returned true. This thread does not need to compile again ’cause the other (faster/first) thread already compiled the template.
Line 17: check if thread exceeds the permitted number of threads allowed to do compile jobs. Because the bouncer was defined in the HTMLDocumentGenerator only a limited number of threads will enter the next code block. This actually was the tricky part of the solution: Lock threads that want to compile a specific template but also ensure that the total number of active compilation tasks does not exceed a defined limit! Because the bouncer applies to all cached ConcurrentTransformer instances this is possible.
Line 19-25: Do the actual compilation work which is the CPU intense part that aused the system overload.
Line 27: Release a permit to allow other thread (in a different ConcurrentTransformer instance) to enter the compilation code.
Line 30: Release the lock so that other threads waiting for that XSL document can continue their processing. (they will return the template that was just compiled, see line 14)
Done! This solution will enforce that (1) only one thread will try to compile a specific XSL document and that (2) only a limitted amount of threads can do compilation work.
Here is the class diagram that shows the pattern-style structure of the solution:
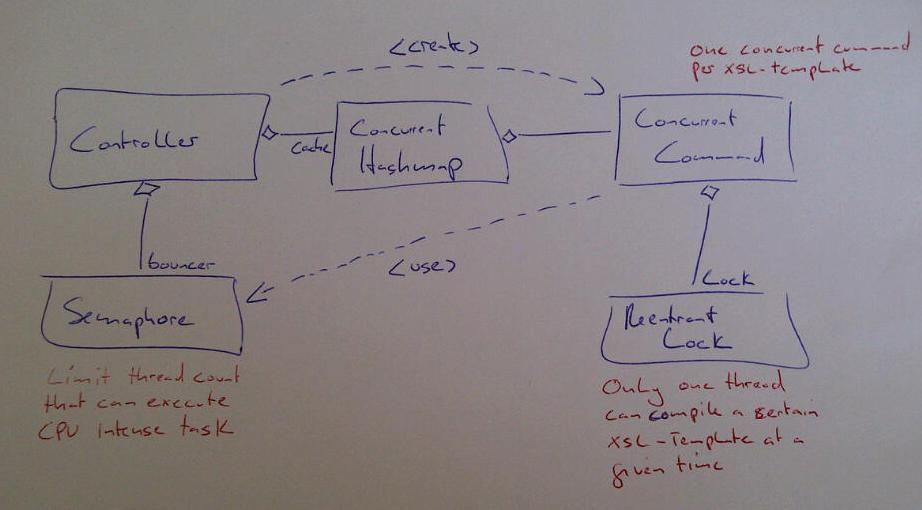
Ошибки
спящего и почему системы работают по совпадению
Несколько недель назад я встретил
доктора Хайнца Каббуца . Я посещал его
курс специалиста по Javaи он открыл мне глаза на такие проблемы. Многопоточность была его первым уроком, и он начал со слов: «Ваши веб-приложения не являются поточно-ориентированными, они просто работают — по чистой случайности!» Хотя это провокационное утверждение, он не ошибается, говоря, что … Описанная ошибка параллелизма была в нашем коде в течение долгого времени, скажем, 8 лет? Это просто не показывалось. Что изменилось? Мы перешли с WebSphere Application Server 6 на 7. И мы решили использовать новый синтаксический анализатор XSL, оптимизированный для z / OS. Старый XSL-парсер работал хорошо во время компиляции, но результат компиляции не был таким хорошим. Новый XSL-парсер обещал оптимизированный результат компиляции. Но, очевидно, это потребовало больше ресурсов процессора во время компиляции. Теперь,так как компиляция была загружена процессором с новым парсером, наша ошибка согласованности неожиданно оказалась большой проблемой. Я бы назвал это «спящим жуком». Он существует годами и внезапно саботирует вашу систему. Я полагаю, что в сегодняшних Java-приложениях есть много подобных ошибок, и я считаю, что не слишком провокационно утверждать, что в ваших системах также будут некоторые спящие ошибки. Ваши системы работают — но по стечению обстоятельств!
From http://niklasschlimm.blogspot.com/2011/09/your-web-applications-work-by-sheer.html