Когда вам нужно протестировать многопоточные программы, всегда нужно подождать, пока система не достигнет определенного состояния, и в этот момент тест может проверить, что было достигнуто правильное состояние.
Обычный способ сделать это — вставить в систему «зонд», который будет сигнализировать примитив синхронизации (например, семафор ), и тест будет ждать, пока семафор не будет сигнализирован или не истечет время ожидания. (Две вещи, которые вы никогда не должны делать — но это частая ошибка — это вставлять спящие в ваш код — потому что они замедляют вас и являются хрупкими — или использовать метод Object.wait без зацикливания на нем — потому что вы можете получить ложную информацию пробуждения, которые приведут к ложным, трудно диагностируемым и очень разочаровывающим ошибкам теста).
Это все хорошо и хорошо (хотя немного многословно — по крайней мере, до тех пор, пока не появятся лямбды Java 8), но что, если второй поток вызывает третий поток и не ожидает его завершения, но в тесте мы хотим подождать для этого? Конкретным примером может быть: интеграционный тест, который проверяет, что система, состоящая из клиента, который обменивается данными через промежуточное программное обеспечение обмена сообщениями с сеткой данных, правильно записывает данные в сетку данных? Конечно, мы будем использовать фиктивное промежуточное программное обеспечение и фиктивную сетку данных, таким образом, запуск / выключение и обработка будут очень быстрыми, но они все равно будут асинхронными (предположим, что мы не можем сделать его синхронным, потому что производственное не является и код написан так, что опирается на этот факт).
Ситуация описана визуально на графике последовательности ниже: у нас есть тест, работающий на T0, и мы хотели бы, чтобы он дождался завершения задачи на T3, прежде чем проверять состояние, в которое система прибыла.
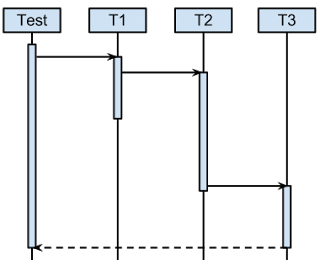
Мы можем добиться этого, используя небольшую модификацию нашей среды исполнения (которая, вероятно, является своего рода Executor). Учитывая следующий интерфейс:
|
1
2
3
4
|
public interface ActivityCollector { void before(); void after();} |
Мы бы вызвали before() в тот момент, когда задача ставится в очередь на выполнение, и after() после ее выполнения (это обычно происходит в разных потоках). Если мы теперь посмотрим, что перед увеличением счетчика и после его уменьшения мы можем просто подождать, пока счетчик станет нулевым (при правильной синхронизации), и в этот момент мы знаем, что все задачи были обработаны нашей системой. Вы можете найти Исполнителя, который реализует это здесь . В производстве вы, конечно, можете использовать реализацию интерфейса, которая ничего не делает , тем самым устраняя любые потери производительности.
Теперь давайте посмотрим на интерфейс, который определяет, как мы ожидаем «обработанное» условие:
|
1
2
3
|
interface ActivityWatcher { void await(long time, TimeUnit timeUnit);} |
Здесь использовались два варианта личного дизайна: только обеспечить способ ожидания определенного времени и больше (если тест занимает слишком много времени, вероятно, это регрессия производительности), и использовать непроверенные исключения для создания кода тестирования. короче.
Последней функцией будет сбор исключений во время выполнения задач и их немедленное прерывание, если где-то есть исключение, а не время ожидания. Это означает, что мы модифицируем наш интерфейс следующим образом:
|
1
2
3
4
5
|
public interface ActivityCollector { void before(); void after(); void collectException(Throwable t);} |
И код, обертывающий выполнение, будет выглядеть примерно так:
|
1
2
3
4
5
6
7
8
|
try { command.run();} catch (Throwable t) { activityCollector.collectException(t); throw t;} finally { activityCollector.after();} |
Вы можете найти реализацию ActivityWatcher / ActivityCollector здесь (они довольно связаны, поэтому один класс реализует их оба). Удачного тестирования!
Несколько предостережений:
- Это требует некоторой модификации вашего производственного кода, поэтому это может быть не лучшим решением (например, вы можете попробовать создать синхронные макеты ваших подсистем и выполнить тестирование таким образом).
- Это решение не очень подходит для случаев, когда задействованы таймеры, потому что будут времена, когда «никакие задачи не ожидают», но на самом деле задача ожидает в таймере. Вы можете обойти это, используя специальный таймер, который вызывает «до» при планировании и «после» в конце задачи.
- Та же проблема может возникнуть, если вы используете сетевую связь для большей аутентичности (даже если она внутри одного и того же процесса): будет момент, когда никакие задачи не запланированы, потому что они сериализуются в сетевом буфере ОС.
- ActivityCollector — это единая точка синхронизации. Таким образом, это может снизить производительность и скрыть ошибки параллелизма. Существуют более сложные способы его реализации, позволяющие избежать некоторых накладных расходов на синхронизацию (например, использование ConcurrentLinkedQueue), но вы не можете полностью их устранить.
PS. Этот пример основан на статье IBM, которую я, похоже, не могу найти (дорогой lazyweb: если кто-то найдет ее, пожалуйста, оставьте комментарий — до / после того, как ее назвали галочкой / меткой), а также на работе моих коллег. Моя единственная роль состояла в том, чтобы написать это и синтезировать это.
Ссылка: В ожидании подходящего момента — в интеграционном тестировании от нашего партнера по JCG Аттилы-Михали Балаза в блоге Java Advent Calendar .