Сценарии — это один из самых популярных способов настроить приложение под потребности клиента прямо во время выполнения. Как всегда, этот подход приносит не только пользу, например, существует хорошо известный компромисс между гибкостью и управляемостью. Эта статья не является одной из тех, которые теоретически обсуждают плюсы и минусы, она практически показывает различные способы применения сценариев и представляет библиотеку Spring, которая предоставляет удобную инфраструктуру сценариев и полезные функции.
Вступление
Сценарии (так называемая архитектура плагинов) — это самый простой способ сделать ваше приложение настраиваемым во время выполнения. Довольно часто сценарии входят в ваше приложение не случайно, а случайно. Скажем, у вас есть очень непонятная часть в функциональной спецификации, поэтому, чтобы не тратить один день на дополнительный бизнес-анализ, мы решили создать точку расширения и вызвать скрипт, который реализует заглушку — выясним, как она должна работать позже.
Существует много известных плюсов и минусов использования такого подхода: например, большая гибкость в определении бизнес-логики во время выполнения и экономия огромного количества времени на повторное развертывание по сравнению с невозможностью проведения комплексного тестирования, а следовательно, непредсказуемые проблемы с безопасностью, проблемы с производительностью и так далее.
Способы выполнения сценариев, обсуждаемые далее, могут быть полезны как для тех, кто уже решил придерживаться плагинов сценариев в своем Java-приложении, так и просто подумал о том, чтобы добавить их в свой код.
Ничего особенного, просто сценарии
С Java JSR-233 API оценка скриптов в Java — простая задача. Для этого API реализован ряд механизмов оценки производственного класса (Nashorn, JRuby, Jython и т. Д.), Поэтому нет проблем с добавлением некоторого волшебства сценариев в код Java, как показано здесь:
|
1
2
3
4
5
|
Map parameters = createParametersMap(); ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine scriptEngine = manager.getEngineByName("groovy"); Object result = scriptEngine.eval(script.getScriptAsString("discount.groovy"), new SimpleBindings(parameters)); |
Очевидно, что разбрасывать такой код по всему вашему приложению не очень хорошая идея, когда у вас есть более одного файла сценария и один вызов в базе кода, поэтому вы можете извлечь этот фрагмент в отдельный метод, помещенный в служебный класс. Иногда вы можете пойти еще дальше: вы можете создать специальный класс (или набор классов), который группирует бизнес-логику, основанную на сценариях, на основе бизнес-домена, например, класса PricingScriptService . Это позволит нам обернуть вызовы для оценки Groovy () в хорошие строго типизированные методы, но все еще есть некоторый шаблонный код, все методы будут содержать отображение параметров, логику загрузки текста сценария и вызов механизма оценки сценария, подобный этому:
|
1
2
3
4
5
6
|
public BigDecimal applyCustomerDiscount(Customer customer, BigDecimal orderAmount) { Map params = new HashMap<>(); params.put("cust", customer); params.put("amount", orderAmount); return (BigDecimal)scripting.evalGroovy(getScriptSrc("discount.groovy"), params);} |
Такой подход обеспечивает большую прозрачность в плане знания типов параметров и типа возвращаемого значения. И не забудьте добавить правило, запрещающее «развернутые» вызовы скриптового движка, в ваш документ по стандартам кодирования!
Сценарии на стероидах
Несмотря на то, что использовать скриптовые движки довольно просто, если у вас много скриптов в вашей кодовой базе, вы можете столкнуться с некоторыми проблемами производительности. В качестве примера — вы используете отличные шаблоны для отчетов и запускаете много отчетов одновременно. Рано или поздно вы увидите, что «простой» сценарий становится узким местом в производительности.
Вот почему некоторые фреймворки создают собственный движок сценариев поверх существующего API, добавляя некоторые приятные функции для повышения производительности, мониторинга выполнения, сценариев полиглота и т. Д.
Например, в среде CUBA есть довольно сложный механизм сценариев, который реализует функции для улучшения реализации и выполнения сценариев, такие как:
- Кэш классов, чтобы избежать повторной компиляции скриптов.
- Возможность написания скриптов с использованием языков Groovy и Java.
- Бин JMX для управления движком скриптов.
Все это повышает производительность и удобство использования, но, тем не менее, это низкоуровневые API для создания карт параметров, выборки текста сценария и т. Д., Поэтому нам все еще нужно сгруппировать их в модули высокого порядка, чтобы эффективно использовать сценарии в приложении.
И было бы несправедливо не упомянуть новый экспериментальный движок GraalVM и его API-интерфейс polyglot, который позволяет нам расширять Java-приложения другими языками. Так что, возможно, мы увидим, как Нашорн рано или поздно уйдет на пенсию и сможет писать на разных языках программирования в одном и том же исходном файле, но это все еще в будущем.
Spring Framework: предложение, от которого трудно отказаться?
В Spring Framework у нас есть встроенная поддержка сценариев через API JDK, вы можете найти много полезных классов в пакетах org.springframework.scripting. *. Есть оценщики, фабрики и т. Д. Все инструменты, необходимые для создания собственной поддержки сценариев.
Помимо низкоуровневых API, в Spring Framework есть реализация, которая должна упростить работу со сценариями в вашем приложении — вы можете определять bean-компоненты, реализованные на динамических языках, как описано в документации .
Все, что вам нужно сделать, это реализовать класс с использованием динамического языка, такого как Groovy, и описать bean-компонент в XML-файле конфигурации следующим образом:
|
1
2
3
|
<lang:groovy id="messenger" script-source="classpath:Messenger.groovy"> <lang:property name="message" value="I Can Do The Frug" /></lang:groovy> |
После этого вы можете внедрить bean-компонент Messenger в классы вашего приложения, используя XML-конфигурацию. Этот bean-компонент может быть автоматически «обновлен» в случае изменений базового сценария, рекомендуется использовать AOP и т. Д.
Этот подход выглядит хорошо, но вы, как разработчик, должны реализовать полноценные классы для ваших компонентов, если вы хотите использовать всю мощь поддержки динамического языка. В реальной жизни сценарии могут быть чисто функциями, поэтому вам нужно добавить дополнительный код в сценарий, чтобы он был совместим с Spring. Также в настоящее время некоторые разработчики считают конфигурацию XML «устаревшей» по сравнению с аннотациями и стараются избегать ее использования, поскольку определения и внедрения bean-компонентов разделены между кодом Java и кодом XML. Хотя это скорее вопрос вкуса, а не производительности / совместимости / читабельности и т. Д., Мы могли бы принять это во внимание.
Написание сценариев: проблемы и идеи
Итак, у всего есть своя цена, и когда вы добавляете скрипты в свое приложение, вы можете столкнуться с некоторыми проблемами:
- Управляемость. Обычно сценарии разбросаны по всему приложению, поэтому довольно сложно управлять многочисленными вызовами figureGroovy (или аналогичными).
- Обнаруживаемость — если что-то идет не так в вызывающем скрипте, довольно сложно найти реальную точку в исходном коде. Мы должны быть в состоянии легко найти все точки вызова скрипта в нашей IDE.
- Прозрачность — написание скриптового расширения не является тривиальной задачей, так как нет информации о переменных, отправляемых в скрипт, а также нет информации о результате, который он должен вернуть. В конце концов, сценарии могут быть сделаны только разработчиком и только изучая источники.
- Тестирование и обновления — развертывание (обновление) нового скрипта всегда опасно, нет возможности отката и инструментов для его тестирования перед производством.
Похоже, что скрытие вызовов методов со сценариями под обычными методами Java может решить большинство из этих проблем. Предпочтительный способ — вводить «скриптовые» бины и вызывать их методы со значимыми именами, а не вызывать просто другой «eval» метод из служебного класса. Поэтому наш код становится самодокументированным, разработчику не нужно искать файл «disc_10_cl.groovy», чтобы выяснить имена параметров, типы и т. Д.
Еще одно преимущество — если все сценарии имеют уникальные java-методы, связанные с ними, будет легко найти все точки расширения в приложении с помощью функции «Найти использование» в IDE, а также понять, каковы параметры этого сценария и для чего он нужен. возвращается.
Такой способ создания сценариев также упрощает тестирование — мы сможем не только тестировать эти классы «как обычно», но и, при необходимости, использовать макетные среды.
Все это напоминает подход, упомянутый в начале этой статьи, — «специальные» классы для скриптовых методов. А что, если мы пойдем еще дальше и скроем все вызовы механизма сценариев, создания параметров и т. Д. От разработчика?
Концепция хранилища сценариев
Идея довольно проста и должна быть знакома всем разработчикам, которые работали с Spring Framework. Мы просто создаем интерфейс Java и как-то связываем его методы со скриптами. Например, Spring Data JPA использует аналогичный подход, где методы интерфейса преобразуются в запросы SQL на основе имени метода, а затем выполняются механизмом ORM.
Что нам может понадобиться для реализации концепции?
Вероятно, аннотация уровня класса, которая поможет нам обнаружить интерфейсы репозитория сценариев и создать для них специальный компонент Spring.
Аннотация уровня метода поможет нам связать метод с его реализацией по сценарию.
И было бы неплохо иметь реализацию по умолчанию для метода, который является не простой заглушкой, а действительной частью бизнес-логики. Это будет работать, пока мы не реализуем алгоритм, разработанный бизнес-аналитиком. Или мы можем позволить ему / ей написать этот сценарий 🙂
Предположим, вам нужно создать сервис для расчета скидки на основе профиля пользователя. А бизнес-аналитик говорит, что мы можем смело предположить, что по умолчанию для всех зарегистрированных клиентов может быть предоставлена скидка 10%. Мы можем подумать о следующей концепции кода для этого случая:
|
1
2
3
4
5
6
7
8
9
|
@ScriptRepositorypublic interface PricingRepository { @ScriptMethod default BigDecimal applyCustomerDiscount(Customer customer, BigDecimal orderAmount) { return orderAmount.multiply(new BigDecimal("0.9")); }} |
И когда дело доходит до правильной реализации алгоритма дисконтирования, Groovy скрипт будет выглядеть так:
|
1
2
3
4
5
6
|
-------- file discount.groovy --------def age = 50if ((Calendar.YEAR - cust.birthday.year) >= age) { return amount.multiply(0.75)}-------- |
Конечная цель всего этого — позволить разработчику реализовать только интерфейс и только скрипт алгоритма дисконтирования, и не возиться со всеми этими вызовами «getEngine» и «eval». Решение для сценариев должно делать всю магию: когда метод вызывается, перехватывает вызов, находит и загружает текст сценария, оценивает его и возвращает результат (или выполняет метод по умолчанию, если текст сценария не найден). Идеальное использование должно выглядеть примерно так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
@Servicepublic class CustomerServiceBean implements CustomerService { @Inject private PricingRepository pricingRepository; //Other injected beans here @Override public BigDecimal applyCustomerDiscount(Customer cust, BigDecimal orderAmnt) { if (customer.isRegistered()) { return pricingRepository.applyCustomerDiscount(cust, orderAmnt); } else { return orderAmnt; } //Other service methods here } |
Вызов скрипта читабелен, и способ его вызова знаком любому разработчику Java, я полагаю.
Это были идеи, и они были использованы для создания библиотеки для реализации репозиториев скриптов с использованием Spring Framework. В библиотеке есть средства для загрузки текста сценария из разных источников и оценки, а также некоторые API, которые позволяют разработчику при необходимости реализовывать расширения для библиотеки.
Как это работает
Библиотека вводит некоторые аннотации (а также XML-конфигурацию для тех, кто предпочитает ее), которые инициируют создание динамических прокси для всех интерфейсов репозитория, помеченных аннотацией @ScriptRepository во время инициализации контекста. Эти прокси публикуются в виде одноэлементных компонентов, которые реализуют интерфейсы репозитория. Это означает, что вы можете внедрить эти прокси-компоненты в свои компоненты с помощью @Autowired или @Inject в точности так, как показано в фрагменте кода в предыдущем разделе.
Аннотация @EnableSpringRepositories, используемая в одном из классов конфигурации приложения, активирует репозитории сценариев. Этот подход аналогичен другим знакомым аннотациям Spring, таким как @EnableJpaRepositories или @EnableMongoRepositories. И для этой аннотации вам нужно указать массив имен пакетов, которые следует сканировать аналогично репозиториям JPA.
|
1
2
3
4
5
|
@Configuration@EnableScriptRepositories(basePackages = {"com.example", "com.sample"})public class CoreConfig {//More configuration here.} |
Как было показано ранее, нам нужно пометить каждый метод в репозитории сценариев @ScriptMethod (библиотека также предоставляет @GroovyScript и @JavaScript ), чтобы добавить метаданные к этим вызовам и указать, что эти методы являются сценариями. И реализация по умолчанию для скриптовых методов, конечно, поддерживается. Все компоненты решения отображаются на диаграмме ниже. Синие фигуры относятся к коду приложения, белые — к библиотеке. Весенние бобы отмечены логотипом Spring.
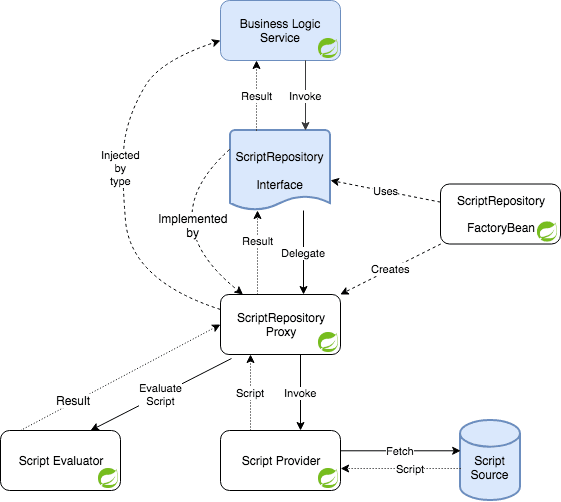
Когда вызывается скриптовый метод интерфейса, он перехватывается прокси-классом, который выполняет поиск двух компонентов: провайдера для получения текста сценария реализации и оценщика для получения результата. После оценки скрипта результат возвращается вызывающей службе. И поставщик, и оценщик могут быть указаны в свойствах аннотации @ScriptMethod, а также в тайм-ауте выполнения (хотя библиотека предоставляет значения по умолчанию для этих свойств):
|
01
02
03
04
05
06
07
08
09
10
11
12
|
@ScriptRepositorypublic interface PricingRepository {@ScriptMethod (providerBeanName = "resourceProvider", evaluatorBeanName = "groovyEvaluator", timeout = 100)default BigDecimal applyCustomerDiscount( @ScriptParam("cust") Customer customer, @ScriptParam("amount") BigDecimal orderAmount) { return orderAmount.multiply(new BigDecimal("0.9"));}} |
Вы можете заметить аннотацию @ScriptParam — нам нужно, чтобы они предоставили имена для параметров метода. Эти имена следует использовать в сценарии, поскольку компилятор Java стирает фактические имена параметров при компиляции. Вы можете опустить эти аннотации, в этом случае вам нужно будет назвать параметры скрипта «arg0», «arg1» и т. Д., Что влияет на читаемость кода.
По умолчанию в библиотеке есть провайдеры, которые могут читать файлы groovy и javascript из файловой системы, а также оценщики на основе JSR-233 для обоих языков сценариев. Вы можете создавать собственные провайдеры и оценщики для разных хранилищ скриптов и механизмов исполнения. Все эти средства основаны на интерфейсах среды Spring ( org.springframework.scripting.ScriptSource и org.springframework.scripting.ScriptEvaluator ), поэтому вы можете повторно использовать все ваши классы на основе Spring, например StandardScriptEvaluator, вместо класса по умолчанию.
Поставщики (а также оценщики) публикуются как компоненты Spring, поскольку прокси-сервер хранилища сценариев разрешает их по имени для гибкости — вы можете заменить исполнителя по умолчанию новым, не изменяя код приложения, но заменяя один компонент в контексте приложения.
Тестирование и управление версиями
Поскольку сценарии могут быть легко изменены, мы должны гарантировать, что мы не сломаем производственный сервер при изменении сценария. Библиотека совместима с тестовой средой JUnit, в этом нет ничего особенного. Поскольку вы используете его в приложении на основе Spring, вы можете протестировать свои сценарии, используя как модульные, так и интеграционные тесты как часть приложения, прежде чем загружать их в производство, также поддерживается mocking.
Кроме того, вы можете создать провайдер скриптов, который будет читать разные текстовые версии скриптов из базы данных или даже из Git или другой системы контроля версий. В этом случае будет легко переключиться на более новую версию скрипта или откатиться к предыдущей версии скрипта, если что-то пойдет не так в работе.
Вывод
Библиотека поможет вам организовать скрипты в вашем коде, обеспечивая следующее:
- Внедряя интерфейсы Java, разработчик всегда получает информацию о параметрах скрипта и их типах.
- Поставщики и оценщики помогают вам избавиться от вызовов механизма сценариев, разбросанных по коду вашего приложения.
- Мы можем легко определить местонахождение всех сценариев в коде приложения, используя команду IDE «Найти примеры (ссылки)» или просто текстовый поиск по имени метода.
Вдобавок к этому поддерживается автоконфигурация Spring Boot, и вы также можете протестировать свои сценарии перед их развертыванием в производство, используя знакомые модульные тесты и технику насмешки.
В библиотеке есть API для получения метаданных сценариев (имен методов, параметров и т. Д.) Во время выполнения, вы можете получить упакованные результаты выполнения, если хотите избежать записи блоков try..catch для обработки исключений, генерируемых сценариями, а также поддерживает XML Конфигурация, если вы предпочитаете хранить свою конфигурацию в этом формате.
Кроме того, время выполнения скрипта может быть ограничено параметром времени ожидания в аннотации.
Источники библиотеки можно найти по адресу https://github.com/cuba-rnd/spring-script-repositories .
| Опубликовано на Java Code Geeks с разрешения Андрея Беляева, партнера нашей программы JCG . Смотрите оригинальную статью здесь: в любой непонятной ситуации идите скрипты
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |